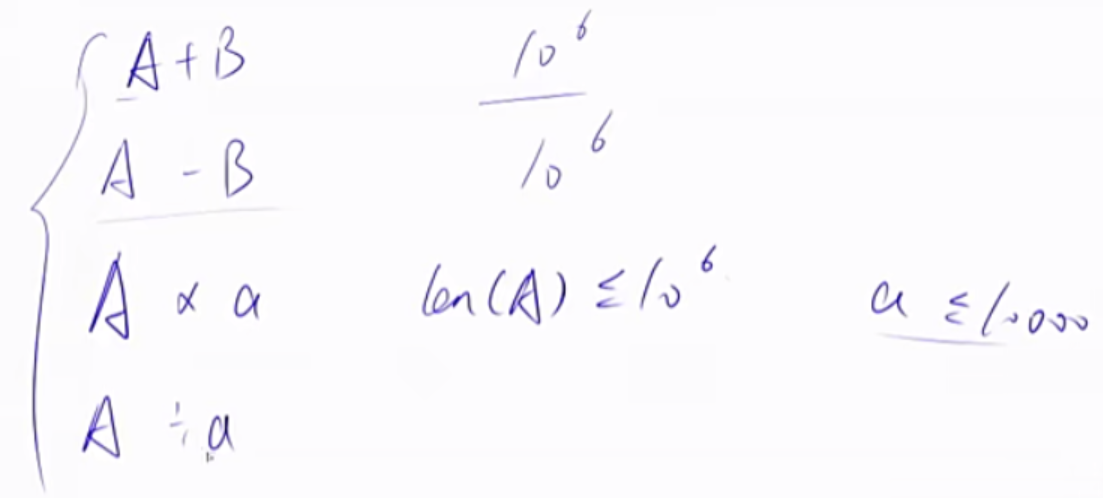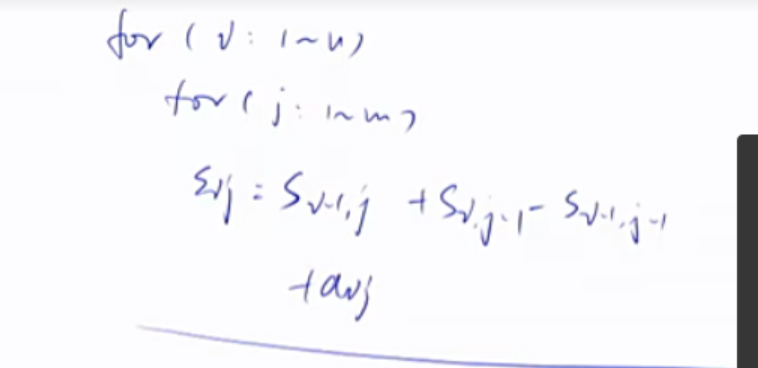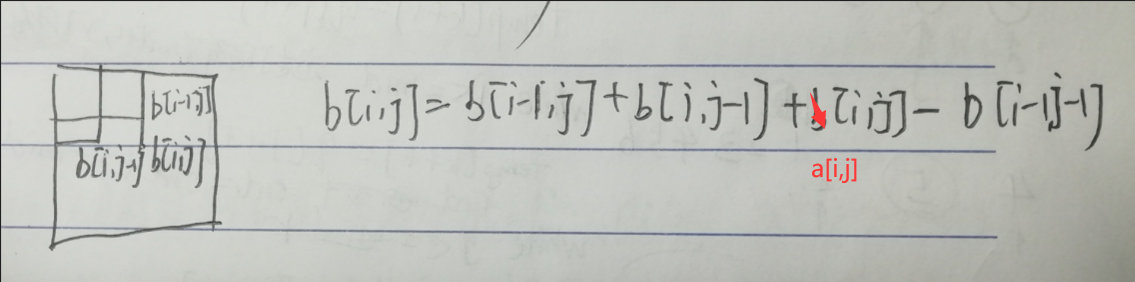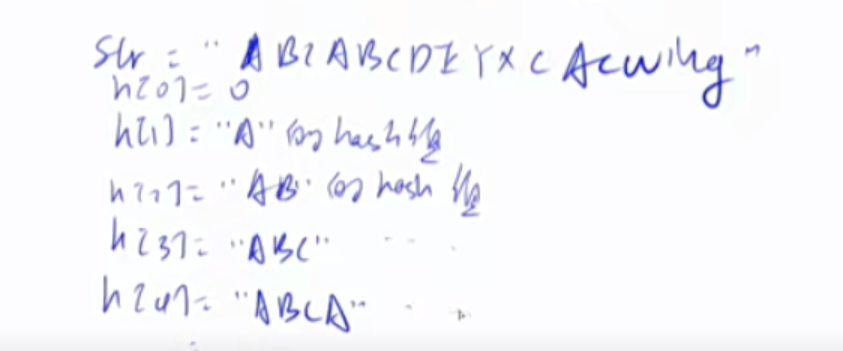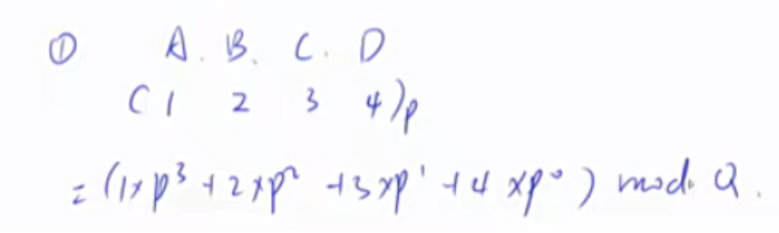模板来源
语法踩坑 强制类型转换之使用long类型的数据进行计算。括号中是重点。
1 long long temp = (long )num[i]+num[j]+num[l]+num[r];
快速排序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 void quick_sort (int q[], int l, int r) if (l >= r) return ; int i = l - 1 , j = r + 1 , x = q[l + r >> 1 ]; while (i < j) { do i ++ ; while (q[i] < x); do j -- ; while (q[j] > x); if (i < j) swap(q[i], q[j]); } quick_sort(q, l, j), quick_sort(q, j + 1 , r); }
快排模板 快排练习题
注意:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 #include <iostream> using namespace std ;int database[5000010 ];int count = -1 ;int aim = 0 ;int n;void quick_sort (int l,int r) if (l>=r) return ; int i = l-1 ,j = r+1 ,x = database[i+j>>1 ]; while (i<j){ do {i++;}while (database[i]<x); do j--;while (database[j]>x); if (i<j) swap(database[i],database[j]); } int idx; if (j == aim&& (l+1 ==r||i == j)){ count = database[aim]; return ; } else if (i == aim&& (l+1 ==r||i == j)){ count = database[aim]; return ; } else if (i == j && aim>j){ quick_sort(i+1 ,r); } else if (aim>j){ quick_sort(i,r); } else { quick_sort(l,j); } } int main () scanf ("%d %d" ,&n,&aim); for (int i = 0 ;i<n;i++){ scanf ("%d" ,&database[i]); } quick_sort(0 ,n-1 ); if (count == -1 ){ printf ("%d" ,database[aim]); }else { printf ("%d" ,count); } return 0 ; }
归并排序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 const int N = 1000010 ;int temp[N];void merge_sort (int q[], int l, int r) if (l >= r) return ; int mid = l + r >> 1 ; merge_sort(q, l, mid); merge_sort(q, mid + 1 , r); int k = 0 , i = l, j = mid + 1 ; while (i <= mid && j <= r) if (q[i] <= q[j]) tmp[k ++ ] = q[i ++ ]; else tmp[k ++ ] = q[j ++ ]; while (i <= mid) tmp[k ++ ] = q[i ++ ]; while (j <= r) tmp[k ++ ] = q[j ++ ]; for (i = l, j = 0 ; i <= r; i ++, j ++ ) q[i] = tmp[j]; }
练习题目
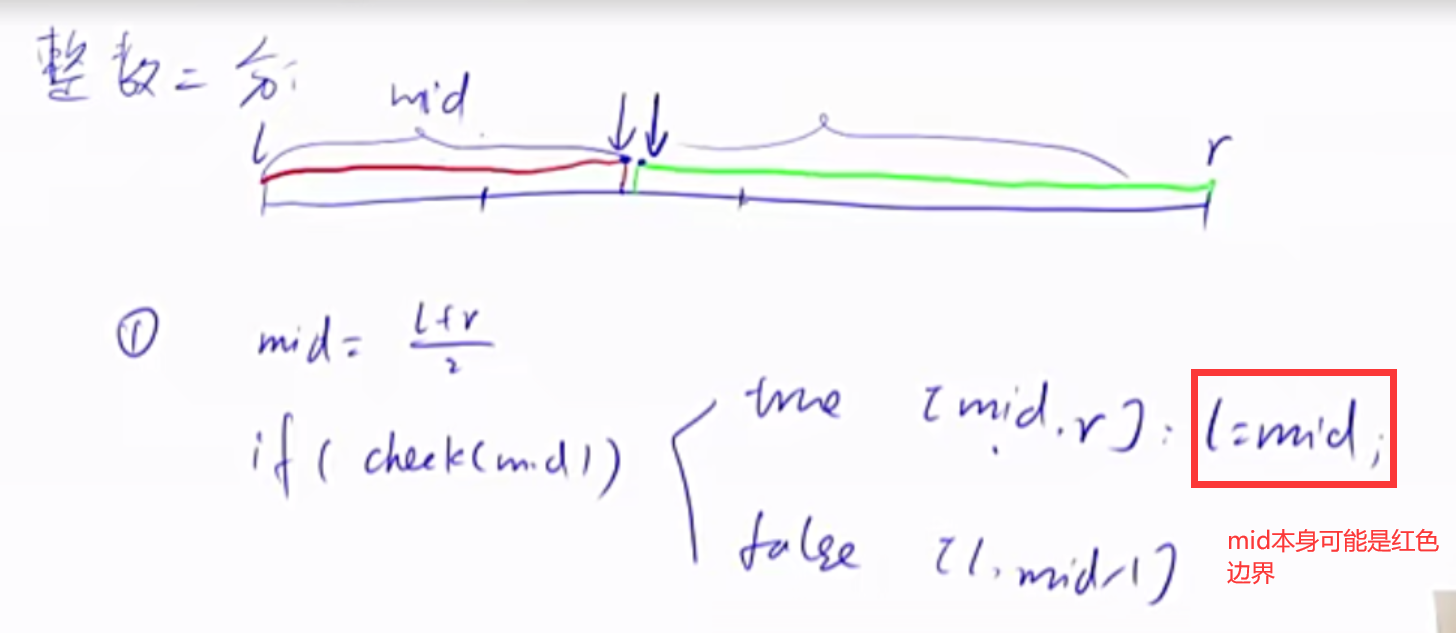
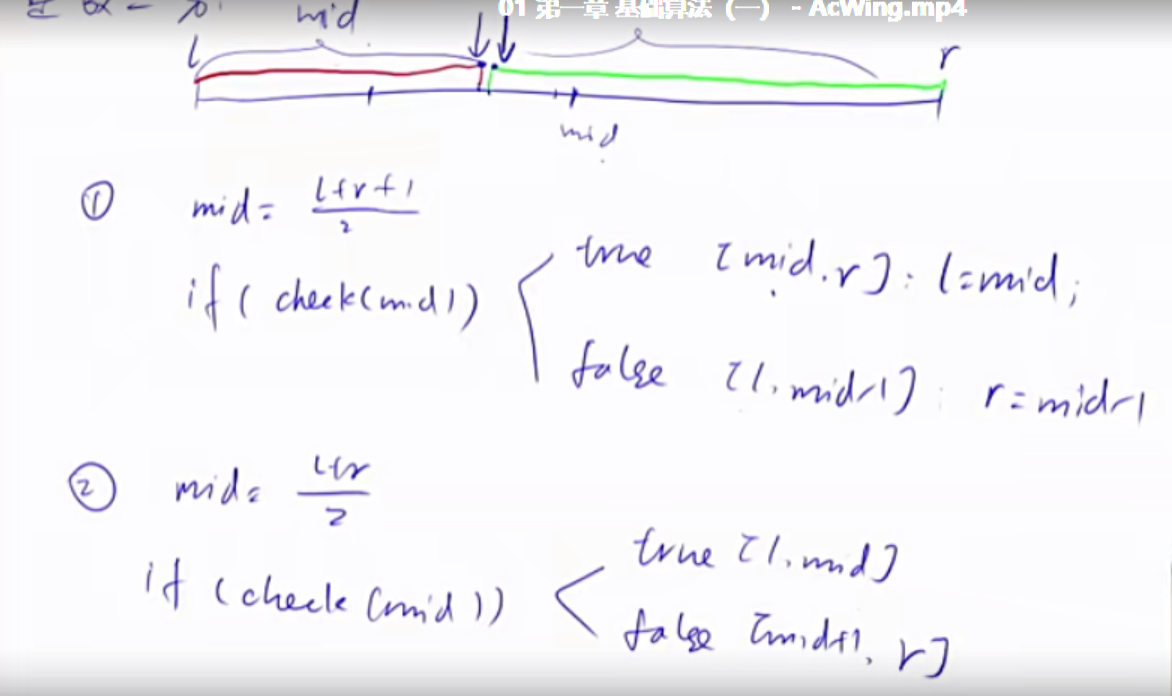
整数二分 整数二分有两个模板,在不同情况下使用,防止稍不留神写出死循环。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 bool check (int x) int bsearch_1 (int l, int r) while (l < r) { int mid = l + r >> 1 ; if (check(mid)) r = mid; else l = mid + 1 ; } return l; } int bsearch_2 (int l, int r) while (l < r) { int mid = l + r + 1 >> 1 ; if (check(mid)) l = mid; else r = mid - 1 ; } return l; }
练习题目1 二分的本质是每次都要选择答案所在的区间进行下一步的处理。二分的算法一定是有解的,就是模板可以给出一个答案的,如果这个答案不符合题目要求,这个才是无解的,这是由题目给的区间中不存在相应答案导致的。练习题目
新思路:结合map来去重。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 class Solution {public : map <int ,map <int ,int >> ma; vector <int >datain; int mid_search (int l, int r, int aim) if (datain[l] == aim) { return l; } else if (datain[r] == aim) { return r; } int mid = (l + r) / 2 ; while (r - l > 1 ) { mid = (l + r) / 2 ; if (datain[mid] >= aim) { r = mid; } else { l = mid + 1 ; } } if (datain[r] == aim) { return r; } else if (datain[l] == aim) { return l; } else { return -1 ; } } vector <vector <int >> threeSum (vector <int >& nums) vector <vector <int >>result; sort(nums.begin (), nums.end ()); datain = nums; int len = nums.size (); for (int i = 0 ; i < len; i++) { for (int j = i + 1 ; j < len; j++) { int res = 0 - (nums[i] + nums[j]); if (j + 1 >= len) continue ; int k = mid_search(j + 1 , len - 1 , res); if (k == -1 ) continue ; int cnt = nums[i] * 100 + nums[j] * 10 + nums[k]; if (ma[nums[i]][nums[j]] != 0 ) continue ; ma[nums[i]][nums[j]] = nums[k]; if (nums[i] == 0 && nums[j] == 0 ) { ma[nums[i]][nums[j]] = 1 ; } result.push_back({ nums[i],nums[j],nums[k] }); } } return result; } };
练习题目2 练习题目
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 int search (vector <int >& nums, int target) int nums_len = nums.size (); int l = 0 ; int r = nums_len; int mid = 0 ; while (r-l>1 ){ mid = (l+r)/2 ; if (target<nums[mid]){ r = mid; }else { l = mid; } } if (nums[l]==target){ return l; }else { return -1 ; } }
练习题目3 其实二分算法在写的时候最需要注意的就是区间的定义方式,采用左闭右开[left,right)的定义方式,在定义初始的l和r值时就要注意这一点,在设置二分终点时也要注意这一点,在每次对区间端点赋值的时候也要注意到这一点,始终统一写法才能保证不会写出死循环。练习题目
练习题目4 练习题目
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Solution {public : int mySqrt (int x) long l = 0 ; long r = x; long mid = 0 ; while (l<r){ mid = (l+r+1 )/2 ; if (x>=mid*mid){ l = mid; }else { r = mid-1 ; } } return l; } };
浮点数二分 浮点数二分的实现中l和r赋的新值都是mid相同。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 bool check (double x) double bsearch_3 (double l, double r) const double eps = 1e-6 ; while (r - l > eps) { double mid = (l + r) / 2 ; if (check(mid)) r = mid; else l = mid; } return l; }
练习题目
高精度加法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 vector <int > add (vector <int > &A, vector <int > &B) if (A.size () < B.size ()) return add(B, A); vector <int > C; int t = 0 ; for (int i = 0 ; i < A.size (); i ++ ) { t += A[i]; if (i < B.size ()) t += B[i]; C.push_back(t % 10 ); t /= 10 ; } if (t) C.push_back(t); return C; }
高精度减法 练习题目
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 vector <int > sub (vector <int > &A, vector <int > &B) vector <int > C; for (int i = 0 , t = 0 ; i < A.size (); i ++ ) { t = A[i] - t; if (i < B.size ()) t -= B[i]; C.push_back((t + 10 ) % 10 ); if (t < 0 ) t = 1 ; else t = 0 ; } while (C.size () > 1 && C.back() == 0 ) C.pop_back(); return C; } bool cmp (vector <int >&A,vector <int >&B) if (A.size ()>B.size ()){ return A.size ()>B.size (); } for (int i = A.size ()-1 ;i>=0 ;i--){ if (A[i]!=B[i]){ return A[i]>B[i]; } } } int main () if (cmp(A,B)){ printf ('-' ); } }
高精度乘法 A以string类型读入,B以int类型读入。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 vector <int > mul (vector <int > &A, int b) vector <int > C; int t = 0 ; for (int i = 0 ; i < A.size () || t; i ++ ) { if (i < A.size ()) t += A[i] * b; C.push_back(t % 10 ); t /= 10 ; } while (C.size () > 1 && C.back() == 0 ) C.pop_back(); return C; }
高精度除法 练习题目
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 vector <int > div (vector <int > &A, int b, int &r) vector <int > C; r = 0 ; for (int i = A.size () - 1 ; i >= 0 ; i -- ) { r = r * 10 + A[i]; C.push_back(r / b); r %= b; } reverse(C.begin (), C.end ()); while (C.size () > 1 && C.back() == 0 ) C.pop_back(); return C; }
一维前缀和
1 2 S[i] = a[1 ] + a[2 ] + ... a[i] a[l] + ... + a[r] = S[r] - S[l - 1 ]
练习题目
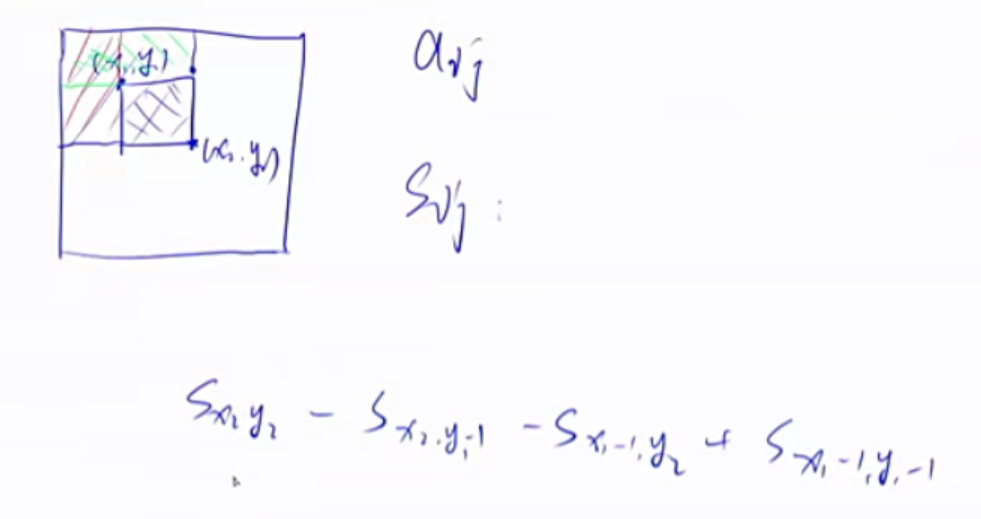
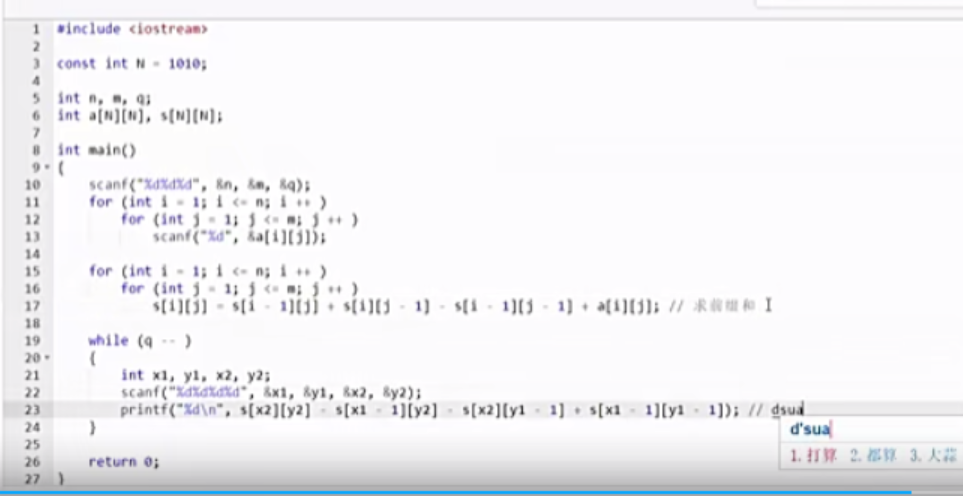
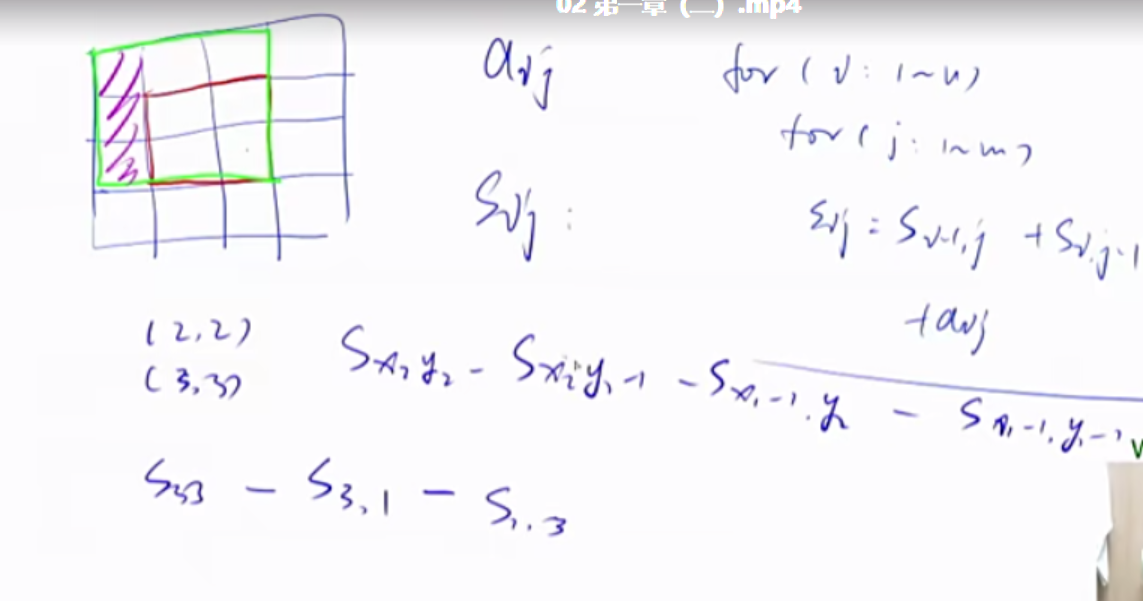
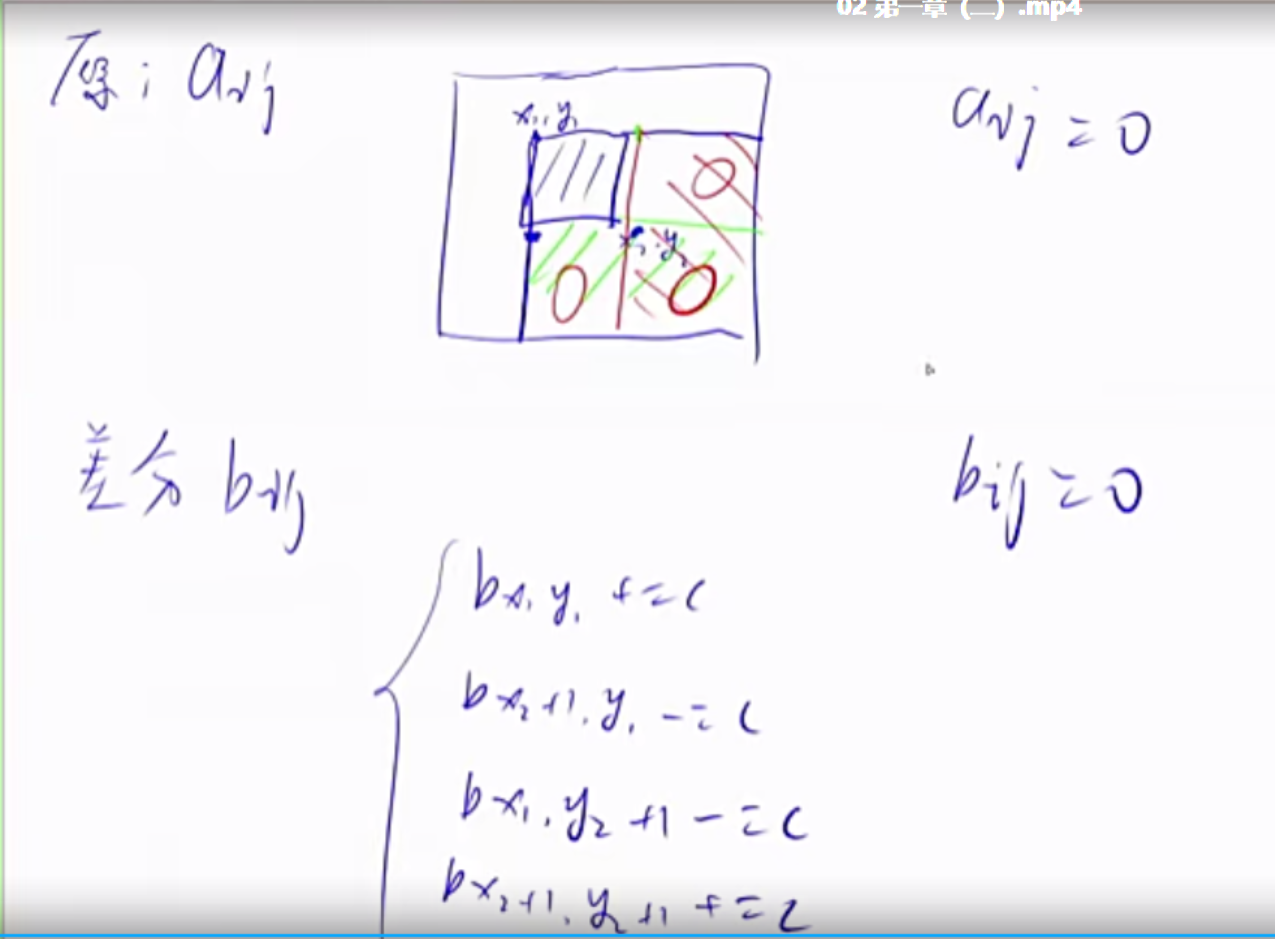
二维前缀和
1 2 3 S[i, j] = 第i行j列格子左上部分所有元素的和 以(x1, y1)为左上角,(x2, y2)为右下角的子矩阵的和为: S[x2, y2] - S[x1 - 1 , y2] - S[x2, y1 - 1 ] + S[x1 - 1 , y1 - 1 ]
练习题目
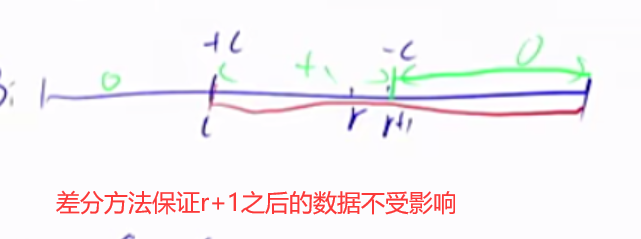
一维差分 我们有一个a数组,我们需要构造b数组,使得a数组是b数组的前缀和。
1 2 3 4 5 6 7 8 9 10 11 给区间[l, r]中的每个数加上c:B[l] += c, B[r + 1 ] -= c void insert(int l,int r,int c){ b[l]+=c; b[r+1 ]-=c; } for (int i = 1 ;i<=n;i++) insert(i,i,a[i]);for (int i = 1 ;i<=n;i++) b[i] += b[i-1 ];
二维差分 我们有一个矩阵a,我们需要构造一个矩阵b,使得矩阵a是矩阵b的前缀和矩阵。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 给以(x1, y1)为左上角,(x2, y2)为右下角的子矩阵中的所有元素加上c: S[x1, y1] += c, S[x2 + 1 , y1] -= c, S[x1, y2 + 1 ] -= c, S[x2 + 1 , y2 + 1 ] += c void insert(int x1,int y1,int x2,int y2,int c){ b[x1][y1]+=c; b[x2+1 ][y1]-=c; b[x1][y2+1 ]-=c; b[x2+1 ][y2+1 ]+=c; } for (int i = 1 ;i<=n;i++){ for (int j = 1 ;j<=m;j++){ insert(i,j,i,j,a[i][j]); } } for (int i = 1 ;i<=n;i++){ for (int j = 1 ;j<=m;j++){ b[i][j] = b[i][j-1 ]+b[i-1 ][j]+b[i][j]-b[i-1 ][j-1 ]; } }
还原原矩阵的依据:
位运算 位运算作为判断条件记得加括号 与&,或|,如
求n的第k位数字,右移一位表示不动。
1 2 求n的第k位数字: n >> k & 1 返回n的最后一位1 :lowbit(n) = n & -n
lowbit是树状数组的基本操作。在C++中是补码存储,如果n是正数,求-n的补码的规则是各位取反,末位加一,即-n = ~n+1,具体原理在第二个图中。
1 2 3 4 while (x){ x = x-lowbit(x); res++; }
人类做题的过程实际上就是DFS的过程。
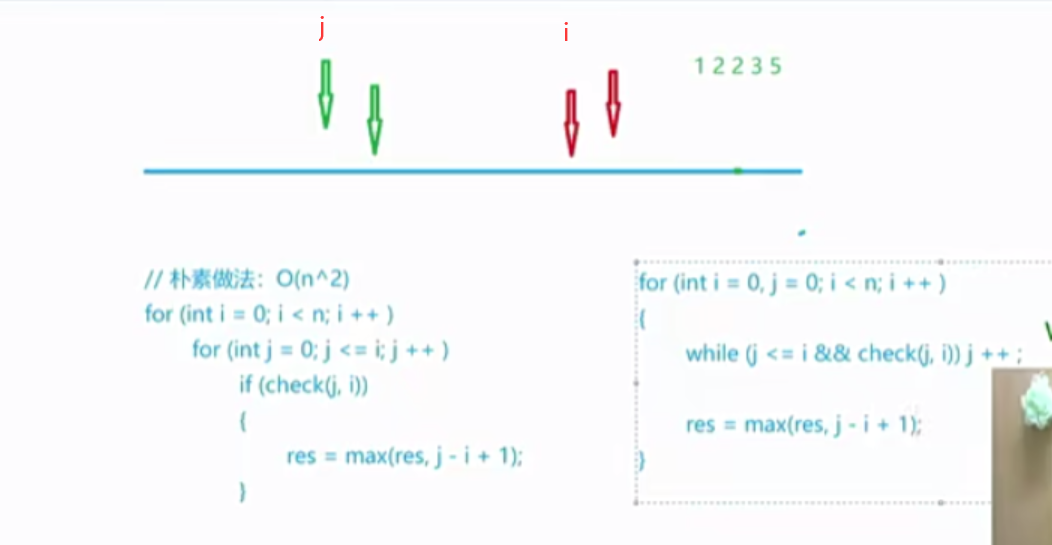
双指针算法 双指针算法的第一种形式——归并排序,一个指针指向序列A,一个指针指向序列B;第二种形式——快速排序,两个指针指向同一个序列,一个在开始的位置,一个在结束的位置。
1 2 3 4 5 6 7 8 9 10 for (int i = 0 , j = 0 ; i < n; i ++ ){ while (j < i && check(i, j)) j ++ ; } 常见问题分类: (1 ) 对于一个序列,用两个指针维护一段区间 (2 ) 对于两个序列,维护某种次序,比如归并排序中合并两个有序序列的操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #include <iostream> #include <string> using namespace std ;int main () char str[1000 ]; gets(str); int n = strlen (str); for (int i = 0 ;str[i];i++){ int j = i; while (j<n&&str[j]!=' ' ) j++; for (int k = i;k<j;k++){ cout <<str[k]; } cout <<endl ; i = j; } }
双指针算法寻找序列中的连续最长不重复子序列。
1 2 3 4 5 6 7 8 9 for (int i = 0 ,j = 0 ;i<n;i++){ s[a[i]]++; while (s[a[i]]>1 ){ s[a[j]]--; j++; } res = max (res,i-j+1 ); }
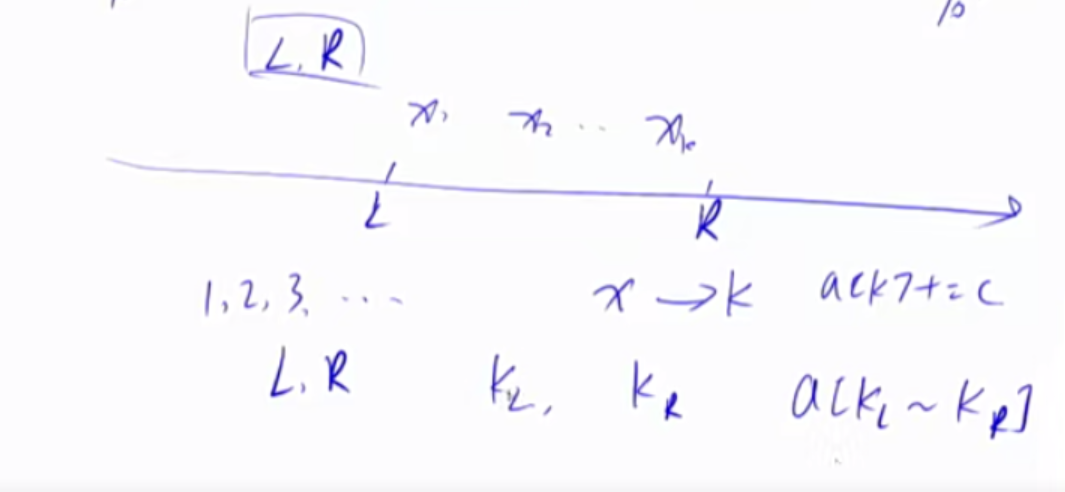
离散化 整数的离散化,保序的离散化。输入的数据范围非常大,但是个数比较少。当我们在处理过程中要以输入的数据作为下标时,我们可以采用离散化的方法把他们映射到从0开始的自然数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 vector <int > alls; sort(alls.begin (), alls.end ()); alls.erase(unique(alls.begin (), alls.end ()), alls.end ()); int find (int x) int l = 0 , r = alls.size () - 1 ; while (l < r) { int mid = l + r >> 1 ; if (alls[mid] >= x) r = mid; else l = mid + 1 ; } return r + 1 ; }
例子:区间和的查询,在数据范围小的情况下可以用前缀和来解决,在数据范围大的情况下,就需要用离散化进行一个坐标的映射,再使用前缀和处理。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 #include <iostream> #include <vector> #include <algorithm> using namespace std ;using PII = pair<int ,int >;const int N = 300010 ;int n,m;int a[N],s[N];vector <int > alls;vector <PII> add,query;int find (int x) int l = 0 ,r = alls.size ()-1 ; while (l<r){ mid = (l+r)>>1 ; if (alls[mid]>=x){ r = mid; }else { l = mid+1 ; } } return r+1 ; } int main () cin >>n>>m; for (int i = 0 ;i<n;i++){ int x,c; cin >>x>>c; add.push_back({x,c}); alls.push_back(x) } for (int i = 0 ;i<m;i++) { int l,r; cin >>l>>r; query.push_back({l,r}); alls.push_back(l); alls.push_back(r); } sort(alls.begin (),alls.end ()); alls.erase(unique(alls.begin (),alls.end ()),alls.end ()); for (auto item:add){ int x = find (item.first); a[x]+=item.second; } for (int i = 1 ;i<=alls.size ();i++){ s[i] = s[i-1 ]+a[i]; } for (auto item:query){ int l = find (item.first),r = find (item.second); cout <<s[r]-s[l-1 ]<<endl ; } }
unique函数的原理,双指针原理:如果i是第一个元素(i == 0)或者a[i]!=a[i-1],那么他就不是重复元素。就令a[j++] = a[i]练习题目
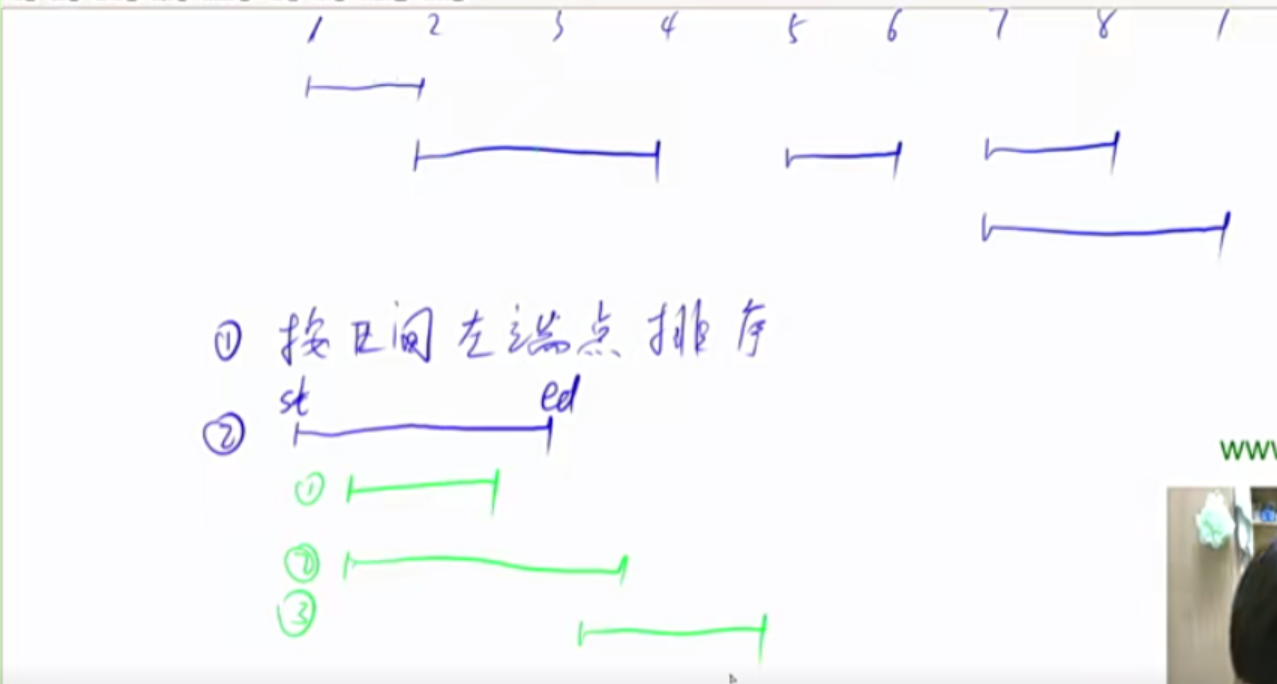
区间合并 区间合并的功能在于快速地将两个有交集的区间进行合并。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 void merge (vector <PII> &segs) vector <PII> res; sort(segs.begin (), segs.end ()); int st = -2e9 , ed = -2e9 ; for (auto seg : segs) if (ed < seg.first) { if (st != -2e9 ||segs[0 ].first == -2e9 ) res.push_back({st, ed}); st = seg.first, ed = seg.second; } else ed = max (ed, seg.second); if (st != -2e9 ) res.push_back({st, ed}); segs = res; } int main () cin >>n; for (int i = 0 ;i<n;i++){ int l,r; cin >>l>>r; segs.push_back({l,r}); } merge(segs); }
练习题目
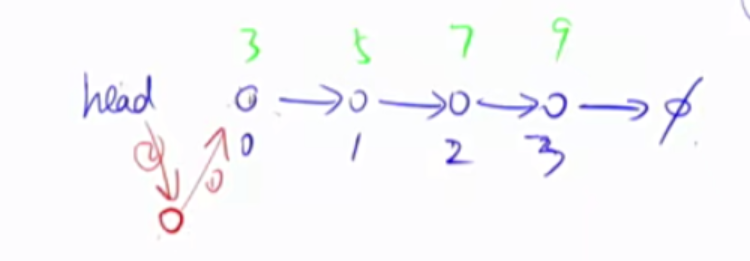
单链表 数组模拟实现(静态链表)。用的最多的是邻接表。邻接表的本质是n个链表。它的基本应用是存储图和树。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 int head, e[N], ne[N], idx;void init () head = -1 ; idx = 0 ; } void insert (int a) e[idx] = a, ne[idx] = head, head = idx ++ ; } void remove () head = ne[head]; } void add (int k,int a) e[idx] = a; ne[idx] = ne[k]; ne[k] = idx; } void remove (int k) ne[k] = ne[ne[k]]; } for (int i = head;i!=-1 ;i = ne[i]){ cout <<e[i]<<" " ; }
注意在该模板中,下标为0的是第一个插入的节点。
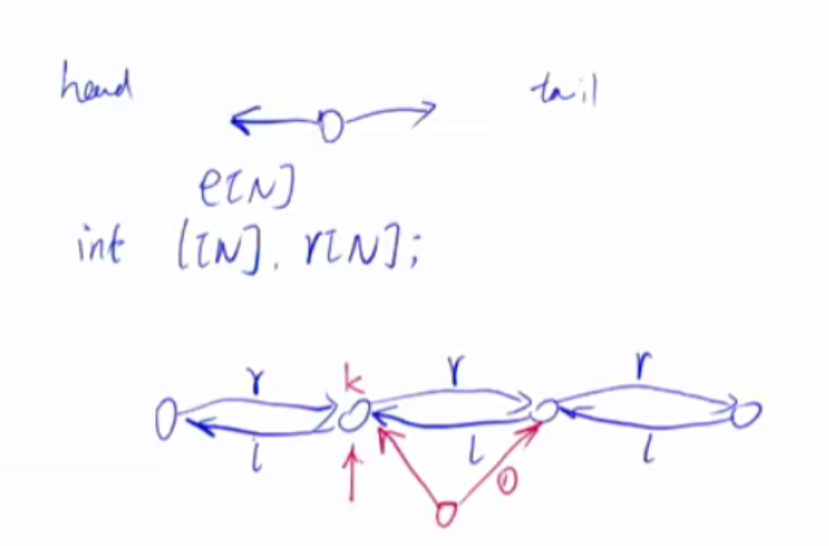
双链表 双链表的作用是优化某些问题。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 int e[N], l[N], r[N], idx;void init () r[0 ] = 1 , l[1 ] = 0 ; idx = 2 ; } void insert (int a, int x) e[idx] = x; l[idx] = a, r[idx] = r[a]; l[r[a]] = idx, r[a] = idx ++ ; } void remove (int a) l[r[a]] = l[a]; r[l[a]] = r[a]; }
模拟栈 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 int stk[N], tt = 0 ;stk[ ++ tt] = x; tt -- ; stk[tt]; if (tt > 0 ){ }
队列 普通队列 在队尾插入元素,在队头弹出元素。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 int q[N], hh = 0 , tt = -1 ;q[ ++ tt] = x; hh ++ ; q[hh]; if (hh <= tt){ }
循环队列 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 int q[N], hh = 0 , tt = 0 ;q[tt ++ ] = x; if (tt == N) tt = 0 ;hh ++ ; if (hh == N) hh = 0 ;q[hh]; if (hh != tt){ }
单调栈 单调栈的典型应用:1)链表与邻接表 2)栈与队列 3)KMP练习题目
1 2 3 4 5 6 7 常见模型:找出每个数左边离它最近的比它大/小的数 int tt = 0 ;for (int i = 1 ; i <= n; i ++ ){ while (tt && check(stk[tt], i)) tt -- ; stk[ ++ tt] = i; }
例题代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 #include <iostream> using namespace std ;const int N = 100010 ;int n;int stk[N],tt;int main () cin >>n; for (int i = 0 ;i<n;i++){ int x; cin >>x; while (tt&&stk[tt]>=x){ tt--; } if (tt) cout <<stk[tt]<<endl ; else cout <<-1 <<endl ; stk[++tt] = x; } } cin .tie(0 );ios::sync_with_stdio(false );
单调队列 保证队列里存的都是当前窗口的所有元素,在队列满了之后,每滑动一次窗口,就要先把滑出窗口的元素出队,再将滑入窗口的元素入队。练习题目
1 2 3 4 5 6 7 8 常见模型:找出滑动窗口中的最大值/最小值 int hh = 0 , tt = -1 ;for (int i = 0 ; i < n; i ++ ){ while (hh <= tt && check_out(q[hh])) hh ++ ; while (hh <= tt && check(q[tt], i)) tt -- ; q[ ++ tt] = i; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 #include <iostream> using namespace std ;const int N = 1000010 ;int n,k;int a[N],q[N];int main () scanf ("%d %d" ,&n,&k); for (int i = 0 ;i<n;i++){ scanf ("%d" ,&a[i]); } int hh = 0 ,tt = -1 ; for (int i = 0 ;i<n;i++){ if (hh<=tt&(i-k+1 >q[hh])){ hh++; } while (hh<=tt&&a[q[tt]]>=a[i]){ tt--; } q[++tt] = i; if (i>=k-1 ){ printf ("%d " ,a[q[hh]]); } if (hh<=tt&&(i-k+1 >q[hh])){ hh++; } while (hh<=tt&&a[q[tt]]<=a[i]){ tt--; } q[++tt] = i; if (i>=k-1 ){ printf ("%d " ,a[q[hh]]); } } return 0 ; }
KMP 这里写的有问题,kmp模板参考kmp
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 求模式串的Next数组: for (int i = 2 , j = 0 ; i <= m; i ++ ){ while (j && p[i] != p[j + 1 ]) j = ne[j]; if (p[i] == p[j + 1 ]) j ++ ; ne[i] = j; } for (int i = 1 , j = 0 ; i <= n; i ++ ){ while (j && s[i] != p[j + 1 ]) j = ne[j]; if (s[i] == p[j + 1 ]) j ++ ; if (j == m) { j = ne[j]; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 #include <iostream> using namespace std ;const int M = 10010 ,M = 100010 ;int n,m;char p[N],s[M];int ne[N];int main () cin >>n>>p+1 >>m>>s+1 ; next[1 ] = 0 for (int i = 2 ,j = 0 ;i<=n;i++){ while (j&&p[i]!=p[j+1 ]){ j = ne[j]; } if (p[i] == p[j+1 ]){ j++; } ne[i] = j; } for (int i = 1 ,j = 0 ;i<=m;i++){ while (j&&s[i]!=p[j+1 ]){ j = ne[j]; if (s[i]==p[j+1 ]){ j++; } if (j == n){ printf ("%d " ,i-n+1 ); j = ne[j]; } } } return 0 ; }
使用定义计算next数组时,前缀是从左到右,后缀也是从左到右看。第i个公共前缀的长度必须小于i。练习题目
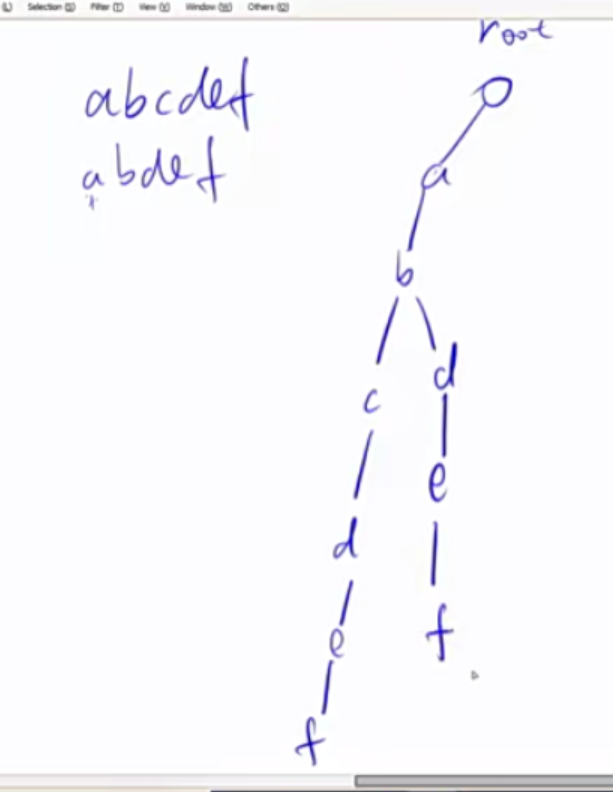
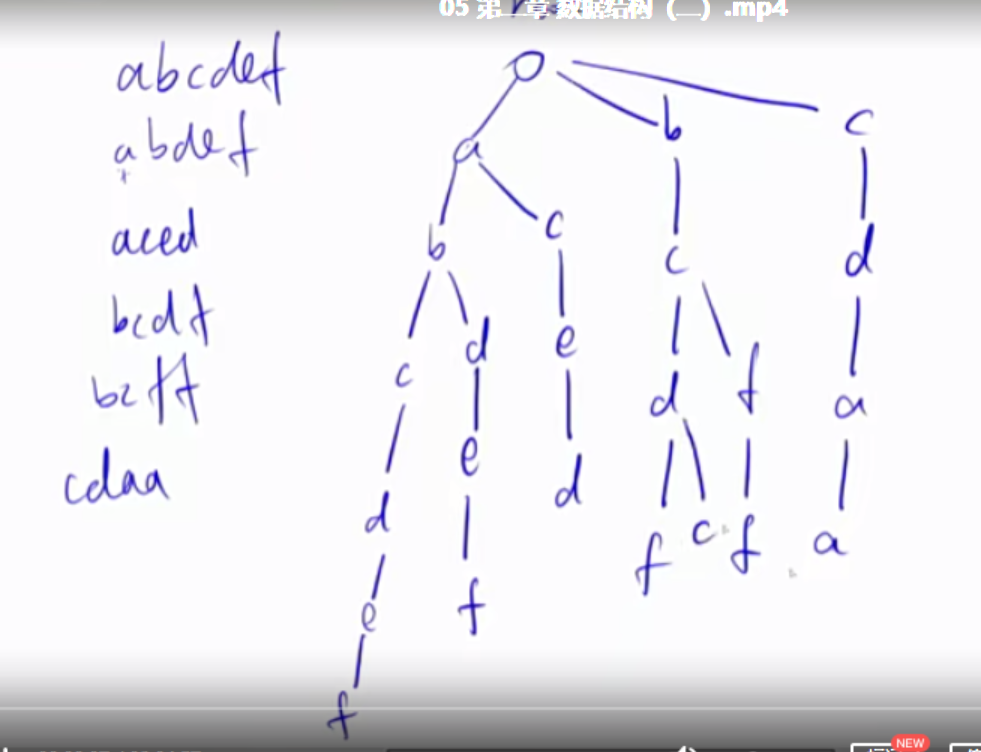
Trie树 Trie树是用来高效地存储和查找字符串集合。使用trie的题目中字符串一般要么全是小写字母,要么全是大写字母,要么全是数字。下图是一个例子,我们用该字符串集合创建一个Trie树。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 int son[N][26 ], cnt[N], idx;void insert (char *str) int p = 0 ; for (int i = 0 ; str[i]; i ++ ) { int u = str[i] - 'a' ; if (!son[p][u]) son[p][u] = ++ idx; p = son[p][u]; } cnt[p] ++ ; } int query (char *str) int p = 0 ; for (int i = 0 ; str[i]; i ++ ) { int u = str[i] - 'a' ; if (!son[p][u]) return 0 ; p = son[p][u]; } return cnt[p]; }
例题,统计字符串出现的次数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 #include <iostream> using namespace std ;const in N = 100010 ;int son[N][26 ],cnt[N],idx;void insert (char str[]) int p = 0 ; for (int i = 0 ;str[i];i++){ int u = str[i]-'a' ; if (!son[p][u]){ son[p][u] = ++idx; } p = son[p][u]; } cnt[p]++; } int query (char str[]) int p = 0 ; for (int i = 0 ;str[i];i++){ int u = str[i]-'a' ; if (!son[p][u]){ return 0 ; } p = son[p][u]; } return cnt[p]; }
练习题目 练习题目
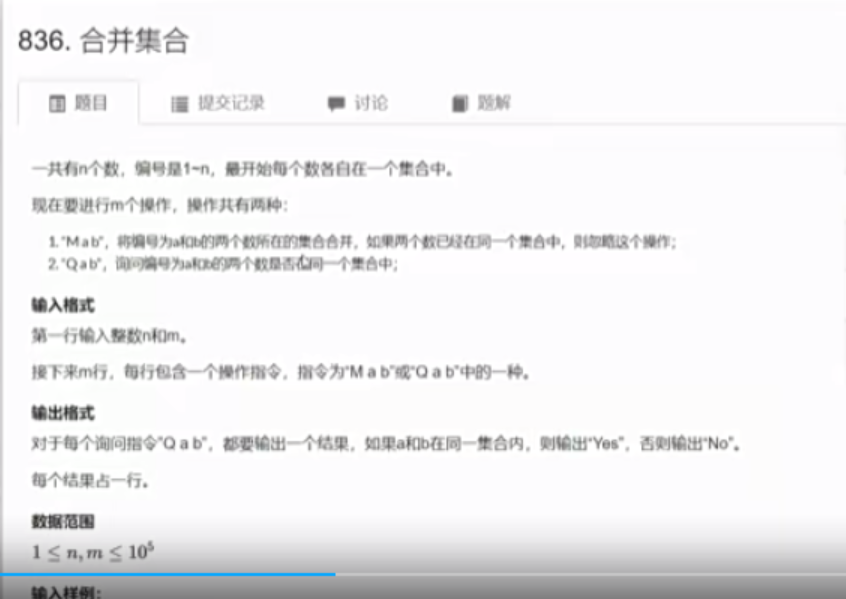
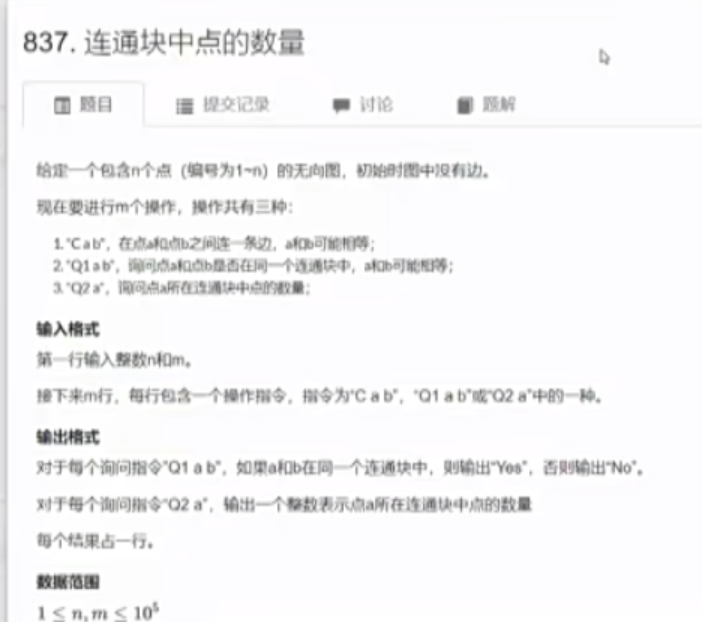
并查集 并查集的特点:1)将两个集合合并;2)询问两个元素是否在一个集合当中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 (1 )朴素并查集: int p[N]; int find (int x) { if (p[x] != x) p[x] = find (p[x]); return p[x]; } for (int i = 1 ; i <= n; i ++ ) p[i] = i; p[find (a)] = find (b); (2 )维护size 的并查集: int p[N], size [N]; int find (int x) { if (p[x] != x) p[x] = find (p[x]); return p[x]; } for (int i = 1 ; i <= n; i ++ ) { p[i] = i; size [i] = 1 ; } size [find (b)] += size [find (a)]; p[find (a)] = find (b); (3 )维护到祖宗节点距离的并查集: int p[N], d[N]; int find (int x) { if (p[x] != x) { int u = find (p[x]); d[x] += d[p[x]]; p[x] = u; } return p[x]; } for (int i = 1 ; i <= n; i ++ ) { p[i] = i; d[i] = 0 ; } p[find (a)] = find (b); d[find (a)] = distance;
例题题目如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 #include <iostream> using namespace std ;const int N = 10010 ;int n,m;int p[N];int size [N];int find (int x) if (p[x]!=x){ p[x] =find (p[x]); } return p[x]; } int main () cin >>n>>m; scanf ("%d %d" ,&n,&m); for (int i = 1 ;i<=n;i++){ p[i] = i; size [i] = 1 ; } while (m--){ char op[2 ]; int a,b; scanf ("%s %d %d" ,op,&a,&b); if (op[0 ] == 'M' ){ if (find (a)==find (b)){ continue ; } p[find (a)] = find (b); size [find (b)]+=size [find (a)]; }else if (op[0 ]=='Q' ){ if (find (a) == find (b)){ printf ("yes" ); }else { printf ("no" ); } }else { scanf ("%d" ,&a); printf ("%d\n" ,size [find (a)]); } } return 0 ; }
在一个连通块中,a可以到达b,b也可以到达a。
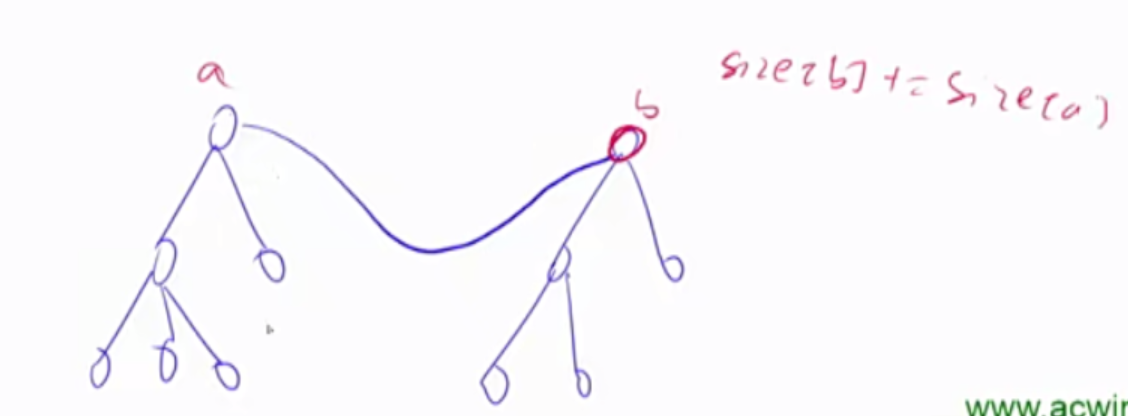
堆 堆的基本操作:1)插入一个数 2)求集合当中的最小值 3)删除最小值 (前三个STL支持) 4)删除任意一个元素 5)修改任意一个元素。
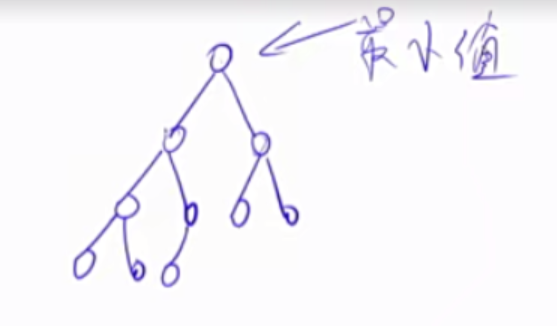
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 int h[N], ph[N], hp[N], size ;void heap_swap (int a, int b) swap(ph[hp[a]],ph[hp[b]]); swap(hp[a], hp[b]); swap(h[a], h[b]); } void down (int u) int t = u; if (u * 2 <= size && h[u * 2 ] < h[t]) t = u * 2 ; if (u * 2 + 1 <= size && h[u * 2 + 1 ] < h[t]) t = u * 2 + 1 ; if (u != t) { heap_swap(u, t); down(t); } } void up (int u) while (u / 2 && h[u] < h[u / 2 ]) { heap_swap(u, u / 2 ); u >>= 1 ; } } for (int i = n / 2 ; i; i -- ) down(i);void insert (int x) h[++size ] = x; up(size ); } return h[1 ];h[1 ] = h[size ]; size --;down(1 ); h[k] = h[size ]; size --;down(k); up(k); h[k] = x; down(k); up(k);
06
哈希表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 (1 ) 拉链法 int h[N], e[N], ne[N], idx; memset (h,-1 ,sizeof (h)); void insert (int x) { int k = (x % N + N) % N; e[idx] = x; ne[idx] = h[k]; h[k] = idx ++ ; } bool find (int x) { int k = (x % N + N) % N; for (int i = h[k]; i != -1 ; i = ne[i]) if (e[i] == x) return true ; return false ; } (2 ) 开放寻址法 int h[N]; int null = 0x3f3f3f3f ; memset (h,0x3f ,sizeof (h)); int find (int x) { int t = (x % N + N) % N; while (h[t] != null && h[t] != x) { t ++ ; if (t == N) t = 0 ; } return t; } void insert (int x) int k = find (x); h[k] = x; } void find_elem (int x) int k = find (x); if (h[k]!=null){ cout <<"Yes" <<endl ; }else { cout <<"No" <<endl ; } }
00:47:20
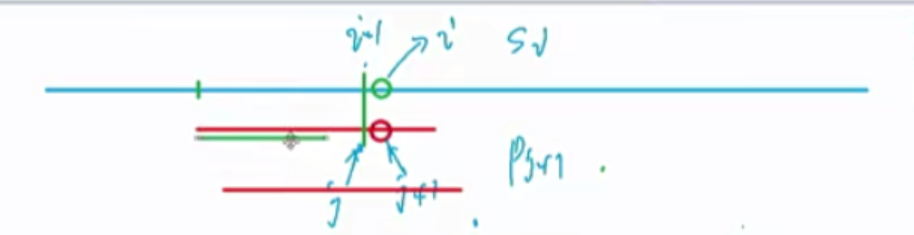
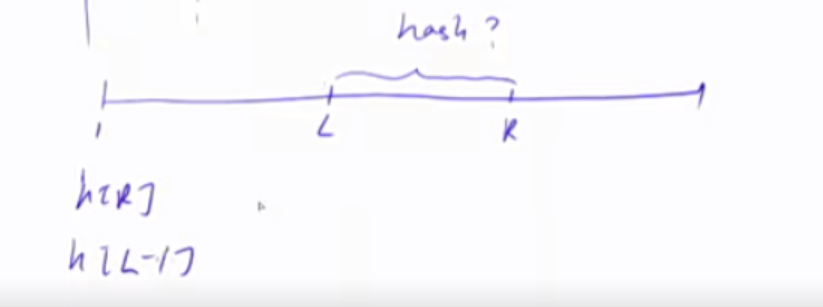
1) 把H[L-1]这一段向右平移到和H[R]对齐的位置。即$H[L-1]\times P^{R-L+1}$
由上式可得,对于一个区间长度为1的区间来说,L = R,str(i) = H(i)-H(i-1)P,因此在计算前缀和的hash时,H(i) = H(i-1)\ P+str(i)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 核心思想:将字符串看成P进制数,P的经验值是131 或13331 ,取这两个值的冲突概率低 小技巧:取模的数用2 ^64 ,这样直接用unsigned long long 存储,溢出的结果就是取模的结果 typedef unsigned long long ULL;ULL h[N], p[N]; p[0 ] = 1 ; for (int i = 1 ; i <= n; i ++ ){ h[i] = h[i - 1 ] * P + str[i]; p[i] = p[i - 1 ] * P; } ULL get (int l, int r) return h[r] - h[l - 1 ] * p[r - l + 1 ]; }
例题代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 #include <iostream> using namespace std ;using ULL = unsigned long long ;const int N = 100010 ,P = 131 ;int n,m;char str[N];ULL h[N],p[N]; UUL get (int l,int r) { return h[r]-h[l-1 ]*p[r-l+1 ]; } int main () scanf ("%d%d%s" ,&n,&m,str+1 ); p[0 ] = 1 ; for (int i = 1 ;i<=n;i++){ p[i] = p[i-1 ]*p; h[i] = h[i-1 ]*p+str[i]; } while (m--){ int l1,r1,l2,r2; scanf ("%d%d%d%d" ,&l1,&r1,&l2,&r2); if (get (l1,r1) == get (l2,r2)){ cout <<"Yes" <<endl ; }else { cout <<"No" <<endl ; } } }
KMP可以用来求字符串的循环节,但是hash不可以。其他的功能hash都可以代替KMP。
C++ STL 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 vector , 变长数组,倍增的思想:当系统为某一个程序分配空间的时候,所需时间,与空间大小无关,与请求次数有关。例如,最开始先给vector 分配一个32 的空间,当不够用的时候,下一次申请的空间大小为64 ,并将32 内的数据copy到64 中去。 size () 返回元素个数,所有容器都有 empty() 返回是否为空,所有容器都有 clear () 清空,并不是所有容器都有,queue 就没有 front()/back() push_back()/pop_back() begin ()/end () []支持随机寻址 使用迭代器来遍历 for (vector <int >::iterator i = a.begin ();i!=a.end ();i++) cout <<*i<<endl for (auto x:a) cout <<x<<endl ; 支持比较运算,按字典序 vector <int >a(4 ,3 ),b(3 ,4 ); if (a<b){ cout <<"a<b" <<endl ; } pair<int , int > 可以存储一个二元组,相当于C++定义的一个结构体,自带一个比较函数 first, 第一个元素 second, 第二个元素 支持比较运算,以first为第一关键字,以second为第二关键字(字典序) pair<int ,string >p; p = make_pair(10 ,"kongming" ); p = (20 ,"abc" ); pair<int ,pair<int ,int >>p; string ,字符串 size ()/length() 返回字符串长度 empty() clear () substr(起始下标,(子串长度)) 返回子串,当子串长度大于字符串长度时,会返回到字符串结尾。字串长度是可选参数,默认值是字符串结尾。 cout <<a.substr(1 ,2 )<<endl ; c_str() 返回字符串所在字符数组的起始地址,在使用printf 函数输出字符串时用得到。 printf ("%s\n" ,a.c_str()); 重载了+运算符,可以支持两个字符串相加,或是一个字符串和一个字符相加。 queue , 队列,没有claer()函数 #include <queue> 如果想要清空queue ,只需要重新构造一个queue q = queue <int >(); size () empty() push() 向队尾插入一个元素 front() 返回队头元素 back() 返回队尾元素 pop() 弹出队头元素 priority_queue, 优先队列,默认是大根堆,没有clear 函数 size () empty() push() 插入一个元素 top() 返回堆顶元素 pop() 弹出堆顶元素 默认是大根堆,我们如果需要小根堆,可以每次向优先队列中插入-x。 定义成小根堆的方式:priority_queue<int , vector <int >, greater<int >> q; stack , 栈 size () empty() push() 向栈顶插入一个元素 top() 返回栈顶元素 pop() 弹出栈顶元素 deque , 双端队列,队头和队尾都可以插入删除,还可以支持随机访问,是一个加强版的vector ,速度稍慢一点 size () empty() clear () front()/back() push_back()/pop_back() push_front()/pop_front() begin ()/end () [] set , map , multiset , multimap , 基于平衡二叉树(红黑树),动态维护有序序列 如果在set 中插入重复元素,这个操作将会被忽略。 size () empty() clear () begin ()/end () 迭代器支持++, -- 返回前驱和后继,时间复杂度 O(logn) set /multiset insert() 插入一个数 logn的复杂度 find () 查找一个数 count() 返回某一个数的个数 erase() (1) 输入是一个数x,删除所有x O(k + logn) k是x的个数 (2 ) 输入一个迭代器,删除这个迭代器 lower_bound()/upper_bound() lower_bound(x) 返回大于等于x的最小的数的迭代器 这个包括x upper_bound(x) 返回大于x的最小的数的迭代器 这个不包括x map /multimap ,除了size ,empty之外,其他操作包括 ++ --操作复杂度都是logn。 insert() 插入的数是一个pair,map 可以像数组那种对一个键值对赋值,访问也可以用数组方式。 erase() 输入的参数是pair或者迭代器 find () [] 注意multimap 不支持此操作。 时间复杂度是 O(logn) lower_bound()/upper_bound() unordered_set , unordered_map , unordered_multiset , unordered_multimap , 哈希表 #include <unordered_map> 和上面类似,增删改查的时间复杂度是 O(1 ) 不支持 lower_bound()/upper_bound(), 迭代器的++,--,因为内部是无序的。 bitset , 压位 C++里面的bool 类型的大小是一个字节。如果我们需要1024 个bool 类型的变量,就需要1024 *8b it,但是如果我们使用1b it来记录一个bool 值,就只需要1024b it。 bitset <10000> s; ~, &, |, ^ >>, <<//移位 ==, != [] count() 返回有多少个1 any() 判断是否至少有一个1 none() 判断是否全为0 set () 把所有位置成1 set (k, v) 将第k位变成v reset() 把所有位变成0 flip() 等价于~ flip(k) 把第k位取反
具体使用:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 #include <iostream> #include <cstring> #include <cstdio> #include <algorithm> #include <vector> using namespace std ;vector <int >a(10 );vector <int >a(10 ,3 );vector <int >a[10 ];
07
树与图的遍历
1 2 3 4 5 6 7 8 9 10 int dfs (int u) st[u] = true ; for (int i = h[u]; i != -1 ; i = ne[i]) { int j = e[i]; if (!st[j]) dfs(j); } }
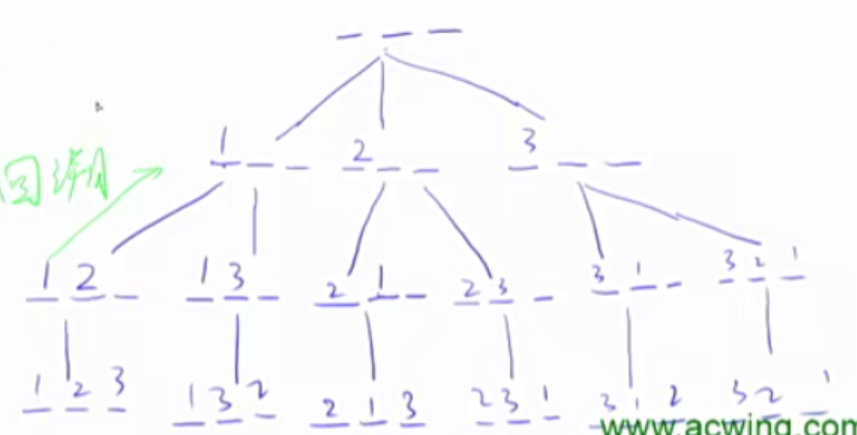
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 #include <iostream> using namespace std ;const int N = 10 ;int n;int path[N];bool st[N];void dfs (int u) if (u == n){ for (int i = 0 ;i<n;i++){ cout <<path[i]<<" " ; return ; } } for (int i = 1 ;i<=n;i++){ if (!st[i]){ path[u] = i; st[i] = true ; dfs(u+1 ); st[i] = false ; } } } int main () cin >>n; dfs(0 ); return 0 ; }
n皇后问题思路二:对每个格子进行dfs,有放下和不放下两种选择,放下的时候要注意检查是否满足条件。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 #include <iostream> const int N = 20 ;int n;char g[N][N];bool col[N],dg[N],udg[N],row[N];void dfs (int x,int y,int s) if (y == n){ y = 0 ; x++; } if (x == n){ if (s == n){ for (int i = 0 ;i<n;i++){ cout <<g[i]; } cout <<endl ; } return ; } dfs(x,y+1 ,s); if (!row[x]&&!col[y]&&!dg[x+y]&&!udg[x-y+n]){ g[x][y] = 'Q' ; row[x] = col[y] = dg[x+y] = udg[x-y+n] = true ; dfs(x,y+1 ,s+1 ); row[x] = col[y] = dg[x+y] = udg[x-y+n] = false ; g[x][y] = '.' ; } }
00:55:07
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 queue <int > q;st[1 ] = true ; q.push(1 ); while (q.size ()){ int t = q.front(); q.pop(); for (int i = h[t]; i != -1 ; i = ne[i]) { int j = e[i]; if (!st[j]) { st[j] = true ; q.push(j); } } }
BFS例题答案
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 #include <iostream> #include <algorithm> #include <queue> #include <cstring> using namespace std ;using PII = pari<int ,int >;const int N = 110 ;int n,mint g[N][N];int d[N][N];PII prev[N][N]; queue <int > q;int BFS () PII start = {0 ,0 }; q.push(start); memset (d,-1 ,sizeof (d)); d[0 ][0 ] = 0 ; int dx[4 ] = {-1 ,0 ,1 ,0 },dy[4 ] = {0 ,1 ,0 ,-1 }; while (!q.empty()){ auto t = q.top(); q.pop(); for (int i = 0 ;i<4 ;i++){ int x = t.first+dx[i],y = t.second+dy[i]; if (x>=0 &&x<n&&y>=0 &&y<m&&g[x][y] == 0 &&d[x][y]!=-1 ){ d[x][y] = d[t.first][t.second]+1 ; prev[x][y] = t; q.push({x,y}); } } } int x = n-1 ,y = m-1 ; while (x||y){ cout <<x<<" " <<y<<endl ; auto t = prev[x][y]; x = t.first,y = t.second; } return d[n-1 ][m-1 ]; } int main () cin >>n>>m; for (int i = 0 ;i<n;i++){ for (int j = 0 ;j<n;j++){ cin >>g[i][j]; } } cout <<BFS()<<endl ; }
01:17:08
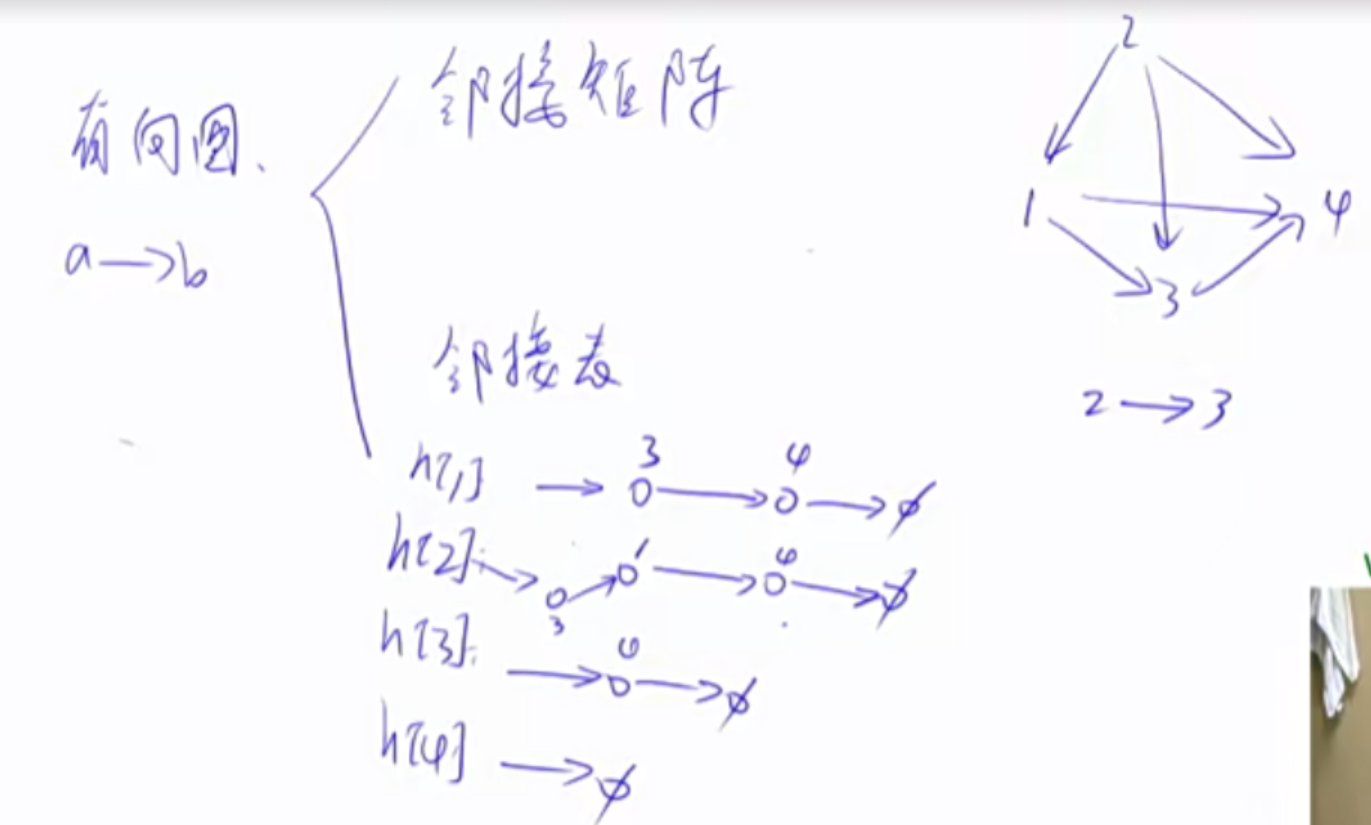
树与图的存储 树是特殊的图。树是无环连通图。因此我们只会探讨图。图分为有向图和无向图。无向图是一种特殊的有向图。要存储一个无向图ab,则需要建立两条边,a->b和b->a。
1 2 3 4 5 6 7 8 9 10 11 12 int h[N], e[N], ne[N], idx;void add (int a, int b) e[idx] = b, ne[idx] = h[a], h[a] = idx ++ ; } idx = 0 ; memset (h, -1 , sizeof h);
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 #include <iostream> #include <cstring> #include <algorithm> const int N = 100010 ,M = N/2 ;int ans = N;int st[N];int h[N],e[M],idx;void add (int a,int b) e[idx] = b,ne[idx] = h[a],h[a] = idx++; } int dfs (int u) st[u] = true ; for (int i = h[u]; i != -1 ; i = ne[i]) { int j = e[i]; if (!st[j]) dfs(j); } } int main () memset (h,-1 ,sizeof h); cin >>n; for (int i = 0 ;i<n-1 ;i++){ int a,b; cin >>a>>b; add(a,b),add(b,a); } dfs(1 ); cout <<ans<<endl ; return 0 ; }
例题的答案
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 int dfs (int u) st[u] = true ; int sum = 1 ; int res = 0 ; for (int i = h[u];i!=-1 ;i = ne[i]){ int j = e[i]; if (!st[j]){ int s= dfs(j); res = max (res,s); sum = s+sum; } } res = max (res,n-sum); ans = min (ans,res); return sum; }
01:47:05
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 #include <iostream> #include <cstring> #include <algorithm> using namespace std ;const int N = 100010 ;int n,m;int h[N],e[N],ne[N],idx;int d[N],q[N];int main () cin >>n>>m; memset (h,-1 ,sizeof h); for (int i = ) }
图的bfs例题。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 #include <iostream> #include <cstring> #include <algorithm> using namespace std ;const int N = 100010 ;int n, m;int h[N], e[N], ne[N], idx;int d[N], q[N];void add (int a, int b) e[idx] = b; ne[idx] = h[a]; h[a] = idx++; } int bfs () int hh = 0 , tt = 0 ; q[0 ] = 1 ; memset (d, -1 , sizeof d); while (hh <= tt) { int t = q[hh++]; for (int i = h[t]; i != -1 ; i = ne[i]) { int j = e[i]; if (d[j] == -1 ) { d[j] = d[t] + 1 ; q[++t] = j; } } } return d[n]; } int main () cin >> n >> m; memset (h, -1 , sizeof h); for (int i = 0 ; i < m; i++) { int a, b; cin >> a >> b; add(a, b); } cout << bfs() << endl ; return 0 ; }
图的bfs的经典应用就是求拓扑序。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 #include <iostream> #include <algorithm> #include <cstring> using namespace std ;const int N = 100010 ;int n, m;int h[N], e[N], ne[N], idx;int q[N], d[N];void add (int a, int b) e[idx] = b; ne[idx] = h[a]; h[a] = idx++; } bool topsort () int hh = 0 , tt = -1 ; for (int i = 1 ; i <= n; i++) { if (!d[i]) { q[++t] = i; } } while (hh <= tt) { int t = q[hh++]; for (int i = h[t]; i != -1 ; i = ne[i]) { int j = e[i]; d[j]--; if (d[j] == 0 ) { q[++tt] = j; } } } return tt == n-1 } int main() { cin >> n >> m; memset (h, -1 , sizeof h); for (int i = 0 ; i < m; i++) { int a, b; cin >> a >> b; add(a, b); d[b]++; } if (topsort()) { for (int i = 0 ; i < n; i++) { cout << q[i] << " " ; } } else { cout << -1 << endl ; } return 0 ; }
拓扑排序要注意的是,条件是头节点,计算的度数是被条件限制的对象。
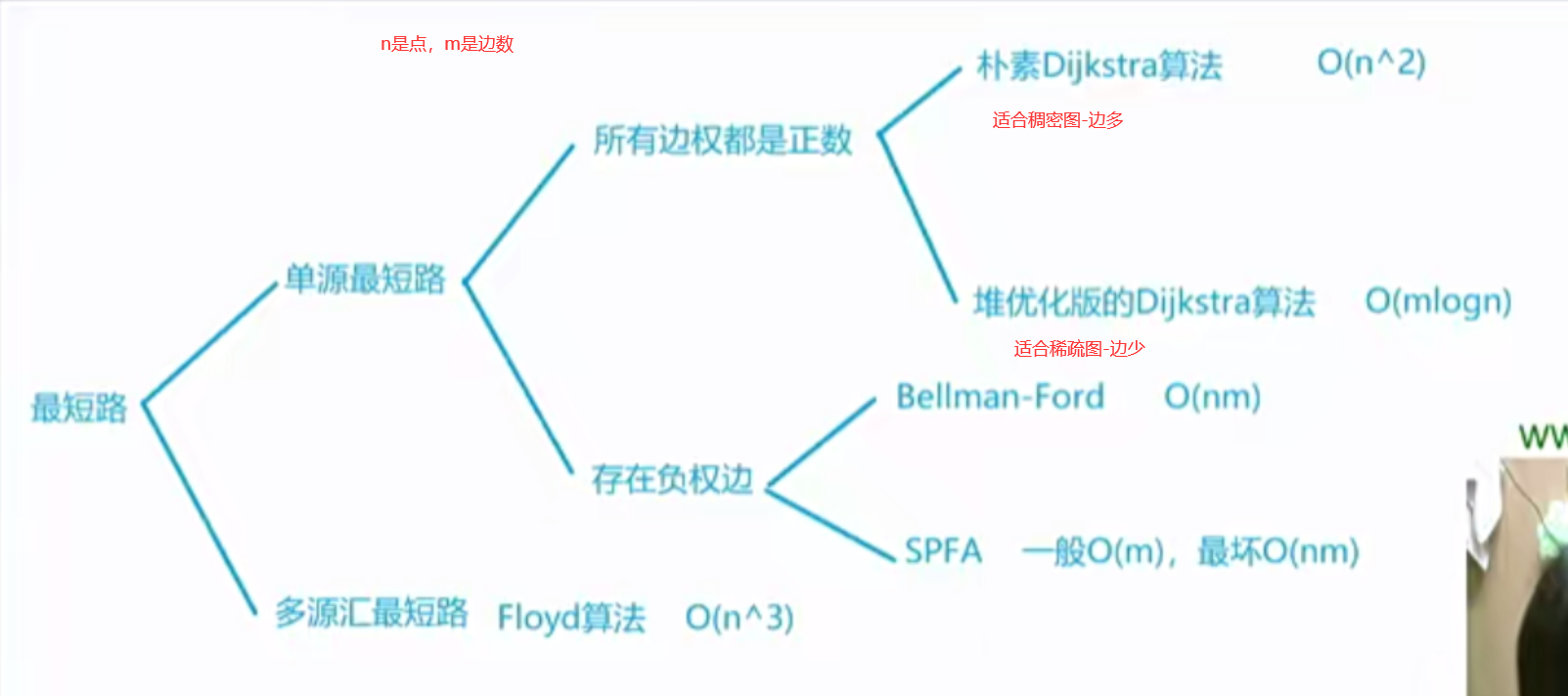
朴素dijkstra算法 最短路问题通常分为两类。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 int g[N][N]; int dist[N]; bool st[N]; int dijkstra () memset (dist, 0x3f , sizeof dist); dist[1 ] = 0 ; for (int i = 0 ; i < n - 1 ; i ++ ) { int t = -1 ; for (int j = 1 ; j <= n; j ++ ) if (!st[j] && (t == -1 || dist[t] > dist[j])) t = j; for (int j = 1 ; j <= n; j ++ ) dist[j] = min (dist[j], dist[t] + g[t][j]); st[t] = true ; } if (dist[n] == 0x3f3f3f3f ) return -1 ; return dist[n]; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 #include <iostream> #include <cstring> #include <algorithm> using namespace std ;const int N = 510 ;int n,m;int g[N][N];int dist[N];bool st[N];int dijkstra () memset (dist,0x3f ,sizeof dist); dist[1 ] = 0 ; for (int i = 0 ;i<n;i++){ int t = -1 ; for (int j = 1 ;i<=n;j++){ if ((!st[j])&&(t == -1 ||dist[t]>dist[j])){ t = j; } } if (t == n) break ; st[t] = true ; for (int j = 1 ;j<=n;j++){ dist[j] = min (dist[j],dist[t]+g[t][j]); } } if (dist[n] == 0x3f3f3f3f ){ return -1 ; }else { return dist[n]; } } int main () scanf ("%d%d" ,&m,&n); memset (g,0x3f ,sizeof g); while (m--){ int a,b,c; scanf ("%d%d%d" ,&a,&b,&c); g[a][b] = min (g[a][b],c); } int t = dijkstra(); printf ("%d\n" ,t); return 0 ; }
堆优化的dijkstra算法 堆有两种实现方式,第一种是手写堆(前面有讲过),第二种方式是使用优先队列。priority_queue。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 #include <iostream> #include <cstring> #include <algorithm> #include <queue> using namespace std ;using pair<int ,int > = PII;const int N = 100010 ;int n,m;int h[N],w[N],e[N],ne[N],idx;int dist[N];bool st[N];void add (int a,int b,int c) e[idx] = b; w[idx] = c; ne[idx] = h[a] h[a] = idx++; } int dijkstra () memset (dist,0x3f ,sizeof dist); dist[1 ] = 0 ; priority_queue<PII,vector <PII>,greater<PII>> heap; heap.push({0 ,1 }); while (heap.size ()){ auto t = heap.top(); heap.pop(); int ver = t.second(),distance = t.first(); if (st[ver]) continue ; for (int i = h[ver];i!=-1 ;i = ne[i]){ int j = e[i]; if (dist[j]>dist[t]+w[i]){ dist[j] = distance+w[i]; heap.push({dist[j],j}); } } } if (dist[n] == 0x3f3f3f3f ){ return -1 ; }else { return dist[n]; } } int main () scanf ("%d%d" ,&m,&n); memset (h,-1 ,sizeof h); while (m--){ int a,b,c; scanf ("%d%d%d" ,&a,&b,&c); add(a,b,c); } int t = dijkstra(); printf ("%d\n" ,t); return 0 ; }
Bellman-Ford算法 BF算法存边直接定义一个结构体,a,b,w就可以,不需要邻接表,临界矩阵。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 int n, m; int dist[N]; struct Edge // 边,a 表示出点,b 表示入点,w 表示边的权重{ int a, b, w; }edges[M]; int bellman_ford () memset (dist, 0x3f , sizeof dist); dist[1 ] = 0 ; for (int i = 0 ; i < n; i ++ ) { for (int j = 0 ; j < m; j ++ ) { int a = edges[j].a, b = edges[j].b, w = edges[j].w; if (dist[b] > dist[a] + w) dist[b] = dist[a] + w; } } if (dist[n] > 0x3f3f3f3f / 2 ) return -1 ; return dist[n]; }
例题。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 #include <iostream> #include <cstring> #include <algorithm> using namespace std ;const int N = 510 ,M = 100010 ;int n,m;int dist[N],backcup[N];struct Edge { int a,b,w; }edges[M]; int bellman_ford () memset (dist, 0x3f , sizeof dist); dist[1 ] = 0 ; for (int i = 0 ;i<k;i++){ memcpy (backup,dist,sizeof dist); for (int j = 0 ;j<m;j++){ int a = edges[j].a,b = edges[j].b,w = edges[j].w; dist[b] = min (dist[b],backup[a]+w); } } if (dist[n]>0x3f3f3f3f /2 ){ return -1 ; } } int main () scanf ("%d%d%d" ,&m,&n,&k); for (int i = 0 ;i<m;i++){ int a,b,c; scanf ("%d%d%d" ,&a,&b,&c); edges[i] = {a,b,w}; } int t = bellman_ford(); if (t == -1 ){ cout <<"impossible" <<endl ; }else { cout <<t<<endl ; } return 0 ; }
spfa 算法(队列优化的Bellman-Ford算法) 只有a变小了,b才会变小,因此我们用一个队列,专门来存储变小过的a,然后以此为根据来更新变小的b。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 int n; int h[N], w[N], e[N], ne[N], idx; int dist[N]; bool st[N]; int spfa () memset (dist, 0x3f , sizeof dist); dist[1 ] = 0 ; queue <int > q; q.push(1 ); st[1 ] = true ; while (q.size ()) { auto t = q.front(); q.pop(); st[t] = false ; for (int i = h[t]; i != -1 ; i = ne[i]) { int j = e[i]; if (dist[j] > dist[t] + w[i]) { dist[j] = dist[t] + w[i]; if (!st[j]) { q.push(j); st[j] = true ; } } } } if (dist[n] == 0x3f3f3f3f ) return -1 ; return dist[n]; }
关键改动。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 cnt[N]; int spfa () memset (dist,0x3f ,sizeof dist); dist[1 ] = 0 ; queue <int >q; q.push(1 ); for (int i = 1 ;i<=n;i++){ st[i] = true ; q.push(i); } st[1 ] = true ; while (q.size ()){ int t = q.front(); q.pop(); st[t] = false ; for (int i = h[t];i!=-1 ;i = ne[i]){ int j = e[i]; if (dist[j]>dist[t]+w[i]){ dist[j] = dist[t]+w[i]; cnt[j] = cnt[t]+1 ; if (cnt[j]>=n){ return true ; } if (!st[j]){ q.push(j); st[j] = true ; } } } } if (dist[n] == 0x3f3f3f3f ) return -1 ; else return dist[n]; return false ; }
spfa判断图中是否存在负环。原理是抽屉原理。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 int n; int h[N], w[N], e[N], ne[N], idx; int dist[N], cnt[N]; bool st[N]; bool spfa () queue <int > q; for (int i = 1 ; i <= n; i ++ ) { q.push(i); st[i] = true ; } while (q.size ()) { auto t = q.front(); q.pop(); st[t] = false ; for (int i = h[t]; i != -1 ; i = ne[i]) { int j = e[i]; if (dist[j] > dist[t] + w[i]) { dist[j] = dist[t] + w[i]; cnt[j] = cnt[t] + 1 ; if (cnt[j] >= n) return true ; if (!st[j]) { q.push(j); st[j] = true ; } } } } return false ; }
在实现过程中注意h的初始化,ne的初始化,idx的初始化,cnt的初始化,dist的初始化,vt的初始化。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 #include <iostream> #include <cstring> #include <queue> #define N 2020 #define num_dege 6010 using namespace std ;queue <int >que;int vt[N], dist[N];int T;int h[N], e[num_dege], ne[num_dege], w[num_dege],idx;int cnt[num_dege];int n, m;void add (int a, int b, int w) e[idx] = b; ::w[idx] = w; ne[idx] = h[a]; h[a] = idx++; } bool spfa () memset (dist, 0x3f , sizeof dist); vt[1 ] = true ; dist[1 ] = 0 ; que.push(1 ); while (!que.empty()) { int t = que.front(); que.pop(); vt[t] = 0 ; for (int i = h[t]; i != -1 ; i = ne[i]) { int j = e[i]; if (dist[j] > dist[t] + w[i]) { dist[j] = dist[t] + w[i]; cnt[j] = cnt[t] + 1 ; if (cnt[j] >= n) { return true ; } if (!vt[j]) { que.push(j); vt[j] = true ; } } } } return false ; } int main () cin >> T; while (T--) { memset (ne, -1 , sizeof ne); memset (h, -1 , sizeof h); memset (vt, 0 , sizeof vt); memset (cnt, 0 , sizeof cnt); idx = 0 ; cin >> n >> m; int a, b, w; for (int i = 0 ; i < m; i++) { cin >> a >> b >> w; if (w >= 0 ) { add(a, b, w); add(b, a, w); } else { add(a, b, w); } } if (spfa()) { cout << "YES\n" ; } else { cout << "NO\n" ; } } return 0 ; }
floyd算法 Floyd是多源汇最短路。邻接矩阵存储所有的边。三重循环。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 初始化: for (int i = 1 ; i <= n; i ++ ) for (int j = 1 ; j <= n; j ++ ) if (i == j) d[i][j] = 0 ; else d[i][j] = INF; void floyd () for (int k = 1 ; k <= n; k ++ ) for (int i = 1 ; i <= n; i ++ ) for (int j = 1 ; j <= n; j ++ ) d[i][j] = min (d[i][j], d[i][k] + d[k][j]); }
原理:三维状态表示d[k,i,j]只经过1-k这些中间点,从i到达j的最短距离。d[k,i,j] = d[k-1,i,k]+d[k-1,k,j]。我们发现第一维可以去掉。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 #include <cstring> #include <iostream> #include <algorithm> using namespace std ;const int N = 210 ,INF = 1e9 ;int n,m,Q;ind d[N][N]; void floyd () for (int k = 1 ;k<=n;k++){ for (int i = 1 ;i<=n;i++){ for (int j = 1 ;j<=n;j++){ d[i][j] = min (d[i][j],d[i][k]+d[k][j]) } } } } int main(){ scanf ("%d %d %d" ,&n,&m,&Q); for (int i = 1 ;i<=n;i++){ for (int j = 1 ;j<=n;j++){ if (i == j)d[i][j] = 0 ; else d[i][j] = INF; } } while (m--){ int a,b,w; scanf ("%d%d%d" ,&a,&b,&w); d[a][b] = min (d[a][b],w); } floyd(); while (Q--){ int a,b; scanf ("%d%d" ,&a,&b); if (d[a][b] > INF/2 ) cout <<"impossible" <<endl ; else printf ("%d" ,d[a][b]); } return 0 ; }
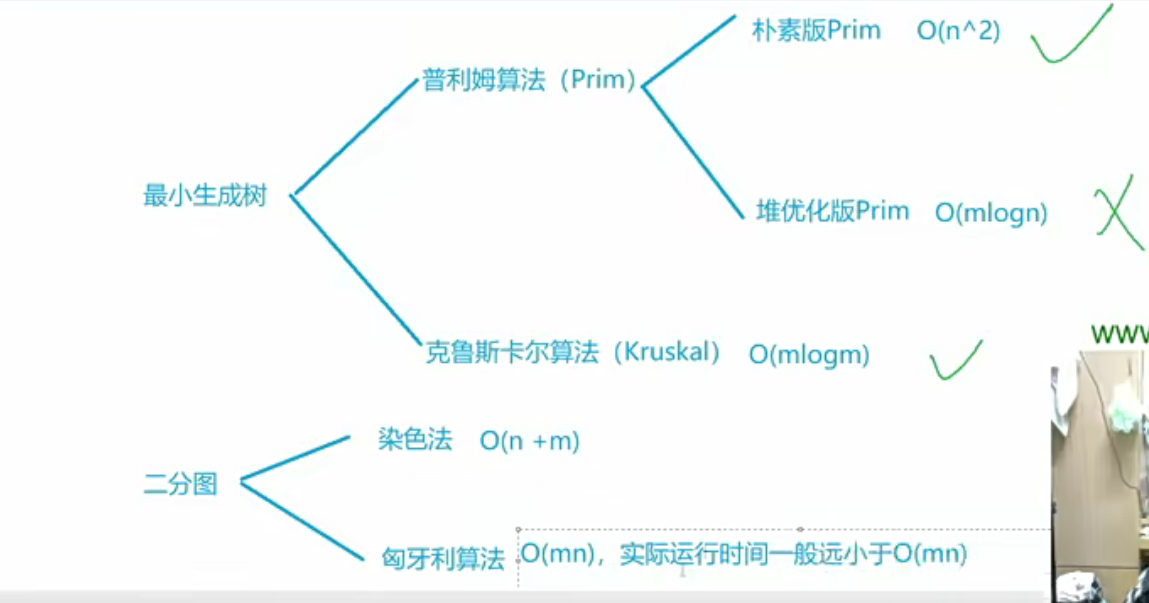
朴素版prim算法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 int n; int g[N][N]; int dist[N]; bool st[N]; int prim () memset (dist, 0x3f , sizeof dist); int res = 0 ; for (int i = 0 ; i < n; i ++ ) { int t = -1 ; for (int j = 1 ; j <= n; j ++ ) if (!st[j] && (t == -1 || dist[t] > dist[j])) t = j; if (i && dist[t] == INF) return INF; if (i) res += dist[t]; st[t] = true ; for (int j = 1 ; j <= n; j ++ ) dist[j] = min (dist[j], g[t][j]); } return res; }
cost先累加,再更新。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 #include <iostream> #include <cstring> #include <algorithm> using namespace std ;const int N = 530 ,INF = 0x3f3f3f3f ;int n,m;int g[N][N];int dist[N];bool st[N];int prim () memset (dist,0x3f ,sizeof dist); int res = 0 ; for (int i = 0 ;i<n;i++){ int t = -1 ; for (int j = 1 ;j<=n;j++){ if (!st[j]&&(t == -1 ||dist[t]>dist[j])){ t = j; } } if (i&&dist[t] == INF){ return INF; } if (i){ res += dist[t]; } for (int j = 1 ;j<n;j++){ dist[j] = min (dist[j],g[t][j]) } st[t] = true ; } return res; } int main () scanf ("%d %d" ,&m,&n); memset (g,0x3f sizeof g); while (m--){ int a,b,c; scanf ("%d%d%d" ,&a,&b,&c); g[a][b] = g[b][a] = min (g[a][b],c); } int t = prim(); if (t == INF) cout <<"不存在生成树" ; else cout <<t; }
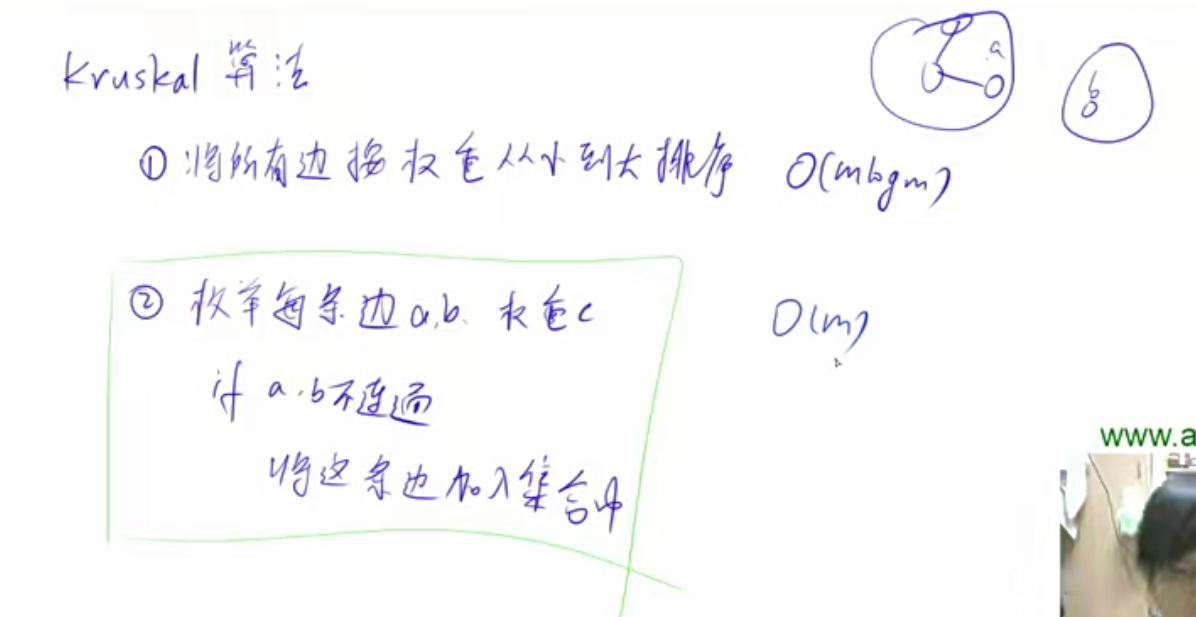
Kruskal算法 算法思路如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 int n, m; int p[N]; struct Edge // 存储边{ int a, b, w; bool operator < (const Edge &W)const { return w < W.w; } }edges[M]; int find (int x) if (p[x] != x) p[x] = find (p[x]); return p[x]; } int kruskal () sort(edges, edges + m); for (int i = 1 ; i <= n; i ++ ) p[i] = i; int res = 0 , cnt = 0 ; for (int i = 0 ; i < m; i ++ ) { int a = edges[i].a, b = edges[i].b, w = edges[i].w; a = find (a), b = find (b); if (a != b) { p[a] = b; res += w; cnt ++ ; } } if (cnt < n - 1 ) return INF; return res; }
例题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 #include <iostream> #include <algorithm> using namespace std ;const int N = 200010 ;int n,m;int p[N];struct Edge { int a,b,w; bool operator <(const Edge &w) const { return w<w.w; } }edges[N]; int find (int x) if (p[x]!=x){ x = find (p[x]); } return p[x]; } int main () scanf ("%d%d" ,&m,&n); for (int i = 0 ;i<m;i++){ int a,b,w; scanf ("%d%d%d" ,&a,&b,&w); edges[i] = {a,b,w}; } sort(edges,edges+m); for (int i = 1 ;i<=n;i++){ p[i] = i; } for (int i = 0 ;i<m;i++){ int a = edges[i].a,b = edges[i].b,w = edges[i].w; a = find (a),b = find (b); if (a!=b){ p[a] = b; res = res +w; cnt++; } } if (cnt<n-1 ) cout <<"不连通" <<endl ; else cout <<res<<endl ; }