1 知行合一
1.1 data
数据:事务的一些属性。
信息:数据经过一些处理之后才能称之为信息。
数据类型:连续型,二进制型。
数据存储:物理结构,逻辑结构。
主要问题:各种类型的数据之间的转化,数据中的错误和冲突。
1.2 Big data
大数据的特征是数据量大(Volume)、产生速度非常快(Velocity)、数据的类型(Variety)越来越多。
2 从数据到知识
2.1 open data
法律公开:允许商业或非商业的使用,没有限制。
技术公开:公开的数据方便大家下载,并能够方便地使用。
2.2 data mining
数据挖掘是从大量的、不完整的和嘈杂的数据中自动提取有趣的和有用的隐含数据的过程。
并不是一个全自动的过程:
1)需要人参与。
2)控制知识。
3)数据收集和预处理。
近义词:知识发现。
2.3 from data to intelligence
data(database)-information(preprocessing)-knowledge(data mining)-decision support(decision models)
3 分类问题
分类是将个体基于一个或多个特征和以前的训练集的标记信息进行分组的过程。
算法:
1)决策树
2)k近邻
3)神经网络
4)支持向量机
数据集一般分成两部分,训练集和测试集。训练集用来生成模型,测试集用来验证模型。
3.1 混淆矩阵 confusion matrix

例如我们在识别男女性别是,把男同学识别为男-true positive,把男同学识别为女-false negative,把女同学识别为男-false positive,把女同学识别为女-true negative。
模型的准确率为(TP+TN)/(P+N)。
3.2 ROC曲线 Receiver Operating Characteristic
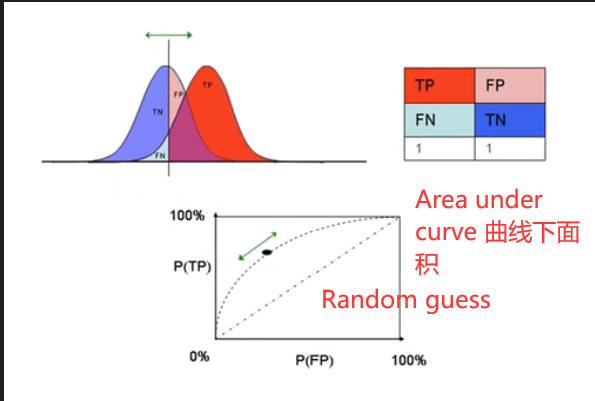
以男女同学身高为例,如果我们将男同学和女同学的身高阈值定为1m的话,那么所有男同学都会被判定为男,但是所有女同学也会被判定为男,则TP=1,FP=1。如果我们将男同学和女同学的身高阈值定为2.5m的话,那么所有的女同学也会被判定为女,但是所有男同学也会被判定为女,则TP=0,FP=0。
图中AUC值越接近于1越好。
3.3 lift analysis
在生活中我们要对100个客户打电话进行促销,如果100个客户中,有8个是真正的客户,那么我们随机从100个客户中选出10人(10%),那么可能是真正客户的概率为8%,但是如果我们通过建模将客户的购买意向从高到低进行排序,那么我们从100个客户中选出10人(10%),可能是真正客户的概率为40%。
那么随机的话是0.8%,经过模型后再挑10%那么挑到的真正用的人数量是3.2%(40%*8%),提升了4倍。
4 聚类及其它数据挖掘问题
在分类(有监督学习)中有标签,聚类中(无监督学习)是没有标签的,并没有类似好人或是坏人这样的标签。当对人的身高体重属性进行聚类时,聚类的结果是体型相似的人聚在一起。
4.1 k-means
距离度量:
1)欧式距离。
2)曼哈顿距离。
3)马氏距离。
算法:
1)k-means相关讲解。
2)Sequential Leader(序列数据的算法)。Sequential Leader Clustering可以处理流数据。K-Means如果看成是把一群人聚集到教室再进行分类的话,那Sequential Leader Clustering就是对每一个进来的同学进行一个分类,所以Sequential Leader Clustering不需要迭代运算,只需要遍历一遍数据集就可以了,值得一提的是这种算法不需要设定k值。Sequential Leader Clustering需要手动设置一个阈值。
3)Affinity Propagation。K-Medoids相关K-Medoids(中心点)算法不选用平均值,转而采用 簇中位置最中心的对象,即中心点(medoids) 作为参照点,算法步骤也和 K-means 类似,其实质上是对 K-means算法的改进和优化。Affinity Propagation聚类算法简称AP, 是基于数据点间的”信息传递”的一种聚类算法。算法的基本思想是将全部样本看作网络的节点,然后通过网络中各条边的消息传递计算出各样本的聚类中心。聚类过程中,共有两种消息在各节点间传递,分别是吸引度( responsibility)和归属度(availability) 。AP算法通过迭代过程不断更新每一个点的吸引度和归属度值,直到产生m个高质量的Exemplar(类似于质心),同时将其余的数据点分配到相应的聚类中。相关实现。
4.2 层次聚类 Hierarchical Clustering
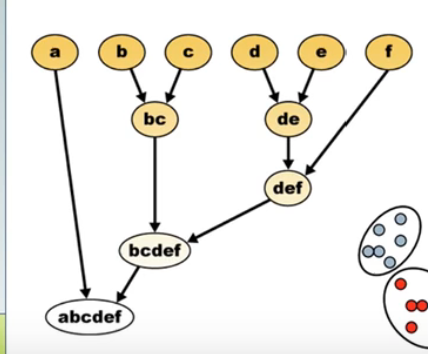
从上面n个小类,逐渐合并,最终变成了一个类。
4.3 关联规则 Association rule
例如通过购物小票发现,买了牛奶和面包的人,一般会买黄油这个结论。
4.4 回归 Regression
线性回归的“线性”,指的是参数和变量之间是线性的。因变量y对于未知的回归系数(β0,β1 …. βk)是线性的详细讲解
4.5 过拟合和欠拟合 overfit
训练刚开始的时候,模型还在学习过程中,处于欠拟合区域。随着训练的进行,训练误差和测试误差都下降。在到达一个临界点之后,训练集的误差下降,测试集的误差上升了,这个时候就进入了过拟合区域——由于训练出来的网络过度拟合了训练集,对训练集以外的数据却不work。详细讲解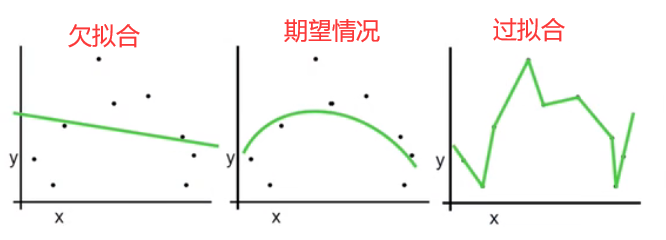
4.6 数据预处理 data preprocessing
常见问题:
1)属性值缺失
2)不同的编码/命名方案
3)不可行的数值
4)不一致数据
5)离群值
数据质量:
1)准确性
2)完备性
3)一致性
4)可解释性
5)时效性
数据清洗:
1)补充缺失值
2)纠正不一致的数据
3)识别离群值和噪声数据
数据集成:组合不同来源的数据
数据转化:
1)归一化
2)聚合
3)类型转换
数据简化:
1)特征抽取
2)抽样
5 隐私保护与并行计算
5.1 隐私保护 privacy protection

回答true的是两种情况:
1)选择第一个问题,吸食大麻的人
2)选择第二个问题,不吸食大麻的人
5.2 云计算 cloud computing
在平时服务器使用需求较小,在节假日服务器使用需求较大,为了能够维持正常工作,我们可能需要购买多台服务器,但是在平时,就会有服务器资源的浪费(需求没有这么多)。有了云服务器后,算力变成了一种资源,当有节假日来临时,我们只需要去云服务提供商那里租用服务器,当需求较小时,我们可以动态调整租用的数量。
6 数据清洗
数据预处理:
1)数据清洗
2)数据转换
3)数据描述
4)特征选择
5)特征提取
脏数据:
1)不完整数据
2)噪声数据
3)不一致的数据
4)冗余数据
5)其他的一些问题,如数据类型和数据集本身不平衡等等。
6.1 缺失数据 missing data
数据并不总是可用的:
1)样本的一个或多个属性可能是空值。
2)许多数据挖掘算法不能直接处理缺失值。
3)数据缺失可能会引起重大问题。
造成数据缺失的可能原因:
1)设备故障
2)未提供数据
3)数据是不适用的。例如一个学生不会有工资这一属性。
数据缺失的类型:
1)完全随机缺失。老师抱着100份卷子,结果风刮跑了40份,则这40份为完全随机缺失。
2)有条件的随机缺失。例如统计同学的体重,可能女同学会不愿意填上自己的体重。
3)非随机缺失。缺失的原因复杂。
6.2 如何处理缺失 how to handle missing data
忽略缺失数据:
1)删除缺少的样本/属性
2)是最简单最直接的方法
3)当缺失率低时效果良好
手动填充缺失数据:
1)重新采集数据
2)领域知识
3)乏味/不可行
自动填写缺失数据:
1)全局常量,填补固定的值。
2)均值或者中位数。
3)最可能的值。
6.3 异常点和离群点 anomaly vs. outlier
如果我们统计中国人的身高这一数据,那么姚明的身高数据属于离群点,而不是异常点。异常点的出现一般要证明有某种异常发生,如巨人症等原因导致的身高很高。
7 异常值与重复数据检测
7.1 局部离群因子 local outlier factor
distance[k](B)是在离B第k近的点处作为半径画一个圆。
但在实际判断时,我们确定的离群点是相对于其他点而言的,也就是说,如果点A距离它的近邻较远,而A的近邻B距离B的近邻较近,那么A就有可能是离群点,具体量化标准如下:
最后需要手动设置一个条件阈值。
7.2 重复数据 Duplicate data
滑动窗口的思想。每次窗口向后滑动的时候,新进入窗口的数据需要和滑动窗口中的其他数据去比较。使用这个方法是基于这条假设:重复的数据总是相邻的。
为了满足这一前提,我们需要按照key值对记录进行排序。这个key值必须保证重复的记录key值相同或是相差很小,这样才能保证排序后重复的数据会相邻。
8 类型转换与采样
经过数据清洗,我们有了一个没有错误的数据集,接下来的工作有:
1)仍然需要标准化
2)类型转换
3)归一化
4)采样
8.1 数据类型 attribute types
连续型:真实值,如温度、高度、重量……
离散型:整数,例如人数……
序数型:排名,例如(优,中,差)……
名称型:符号,例如(老师,工人,推销员)……对于此类数据的编码,比较复杂,例如红(0),绿(1),蓝(2)这样编码,也就默认了红绿之间的距离小于红蓝。可以采用one-hot编码,红色(001),蓝色(010),绿色(100),这三种颜色的汉明距离相同。
字符串型:文本信息,例如“西安电子科技大学”……
8.2 采样 sampling
数据库/数据中心可以存储TB级的数据。
处理限制:CPU,内存,I/O……
用采样来降低时间复杂度。
在统计中,使用抽样是因为获取整个数据集是昂贵的。但是在大数据中使用采用的原因是数据量太大,一次无法全部处理,所以会从数据集中抽取10%的数据作为样本进行处理。
聚合:
改变数据的规模,我们只需要知道某个客户在一个月中一共打了多少电话,并不关心他打给谁,打了多长时间等等,这就是对数据的聚集的过程。
采样也可以被用于调整类的分布,平衡数据集的数据。例如在西电,男女比例悬殊,我们可以通过采样,来平衡数据集中样本的男女比例,以此避免在后续的数据分析过程中犯错误。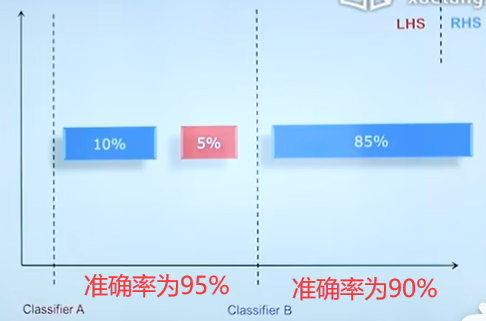
对于上图中A,B两个分类器,A的准确率比B高,但是在实际使用过程中,我们更希望分类器可以分辨出红色块数据(例如是可能患癌症的人),整体的准确率就不能很好的量化这两个分类器的表现。因此我们要用以下指标。
G-mean指标:
即在所有应该为positive的数据中,判断结果为positive的比例。
即在所有应该为negative的数据中,判断结果为negative的比例。
F-measure指标:
准确率即在所有判断为positive的数据中,确实是positive的比例。例如在搜索引擎上搜索文章,返回的结果中有多少是我真正需要的。
召回率即在所有应该为positive的数据中,判断为positive的比例。例如在搜索引擎上搜索文章,我需要的100篇文章中被顺利找到的文章有多少。
8.3 向上采样 over sampling
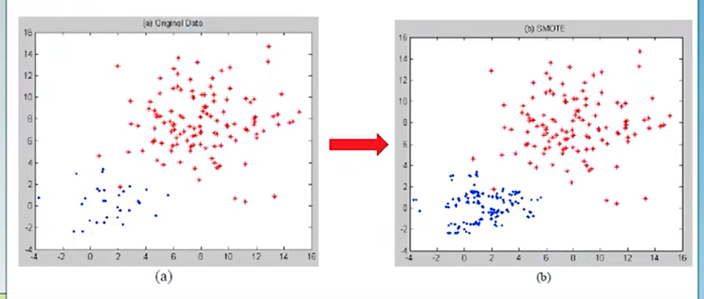
在上图数据集中,如果红颜色的点远远多于蓝颜色的点,如果直接进行分类,很多分类器会犯错。我们可以在采样的时候多采样蓝颜色的点,具体的采样方法是对于颜色样本点A,我们找到他的近邻B,然后在A和B之间的区域中随机生成一个点,有点类似于插值的方法。
8.4 边界采样 boundary sampling
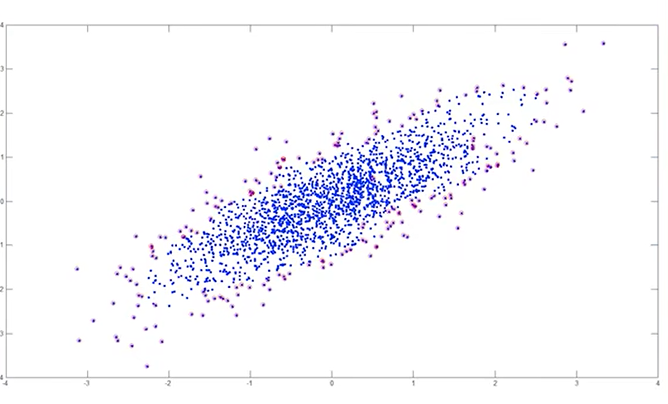
在上图数据集中,我们观察发现边界点的价值远远大于中间的点,那么在采样的过程中,我们只需要提取边缘点,就可以达到和使用全部数据集相同的效果,从而节省大量的计算资源。
9 数据描述与可视化
9.1 标准化 normalization
不同单位下数值的大小会不同,因此需要一些标准化的操作。
Min-Max 标准化(作用是把数据映射到01区间):
例如收入的范围是12000到98000,那么73600会被映射到
这种方法适用于数据有明确的上下界。对于没有明确上下界的数据,可以采用Z-score的方法进行标准化。Z-score的原理是计算样本点偏离了均值多少个σ。
Z-score 标准化(μ:mean,σ:标准差)
9.2 数据描述 data description
均值:算数平均值 = 数据总和/数量,特性是容易受到一两个大的值的影响。
中位数:即用位于50%位置的样本的水平来描述数据集的整体水平。
众数(在正态分布情况下均值、中位数、众数是重合的):
1)一个列表中最频繁出现的值。
2)可用于非数值数据。
方差:多样性程度,是比较密集还是相对分散。
皮尔逊相关系数
1)如果r>0,A和B是正相关。
2)如果r=0,A和B不是线性相关。
3)如果r<0,A和B负相关。
其中n-1是样本数据的自由度。当样本数据的个数为n时,若样本平均数 x拔 确定后,则附加给n个观测值的约束个数就是1个,一次只有n-1个数据可以自由取值,其中必有一个数据不能自由取值。按照这一逻辑,如果对n个观测值附加的约束个数为k个,自由度则为n-k。例如假设样本有3个值,即x1=2,x2=4,x3=9,则当 x拔 =5确定后,x1、x2、x3只有两个数据可以自由取值,另一个则不能自由取值,比如x1=6,x2=7,那么x3必然取2,而不能取其他值。
两个变量之间的皮尔逊相关系数定义为两个变量的协方差除以他们标准差的乘积,协方差的定义见“主成分分析法”部分。
我个人觉得比较容易理解的步骤是:我们一般用欧式距离(向量间的距离)来衡量向量的相似度,但欧式距离无法考虑不同变量间取值的差异。举个例子,变量a取值范围是0至1,而变量b的取值范围是0至10000,计算欧式距离时变量b上微小的差异就会决定运算结果。而Pearson相关性系数可以看出是升级版的欧氏距离平方,因为它提供了对于变量取值范围不同的处理步骤。因此对不同变量间的取值范围没有要求,最后得到的相关性所衡量的是趋势,而不同变量量纲上的差别在计算过程中去掉了,等价于z-score标准化。在低维度可以优先使用标准化后的欧式距离或者其他距离度量,在高维度时Pearson相关系数更加适合。
在上图中,调查了1500人,其中20%的人喜欢下象棋,80%的人不喜欢。如果喜欢下象棋和喜欢科幻小说没有关系的话,那么在喜欢科幻小说的450人中,会有20%也就是90人喜欢下象棋,80%也就是360人不喜欢下象棋,但是实际情况却不是这样,为了衡量观察到的数据与期望的数据的差异,我们可以使用红框中的公式来量化。(卡方分布)
卡方检验:卡方值描述两个事件的独立性或者描述实际观察值与期望值的偏离程度。卡方值越大,表名实际观察值与期望值偏离越大,也说明两个事件的相互独立性越弱。
9.3 数据可视化 data visualization
一维数据:圆饼图,曲线图,柱状图。
二维数据、三维数据也可以使用matlab绘制一些图。
高维数据:
1)Box Plots(matlab) 箱型图,每一维单独进行可视化。
2)Parallel Coordinates 平行坐标思想。
3)CiteSpace 可视化文献。
推荐的可视化软件Gephi。
10 特征选择
10.1 类分布 class distributions
通过绘图来观察某个属性是否能够比较明显的区分两个类型。
可以使用熵(entropy)来量化我们根据已知属性,对自己判断的有多大把握。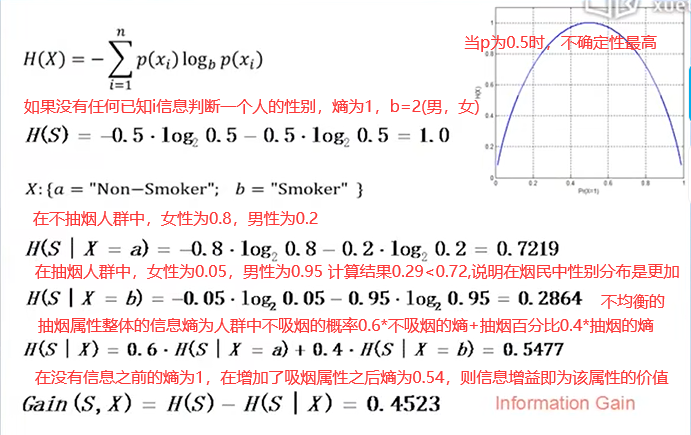
10.2 特征子集搜索 feature subset search
分支定界的思想(branch and bound)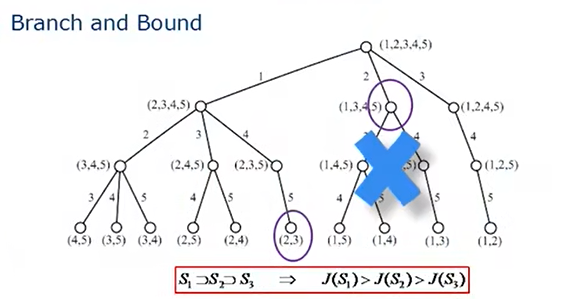
如果现在有5个属性,我们需要找到最优的两元组,首先定义一个指标J,如果S2是S1的子集的话,那么J(S2)小于J(S1)。随着属性越来越少,属性集的J值会越来越低。(单调性的假设)
如果在搜索树中,J(S({2,3}))已经大于J(S({1,3,4,5})),那么S({1,3,4,5})后面的分支就不需要遍历了,因为他们的J值一定小于S({1,3,4,5})这个节点的J值。
J值排在前K个的特征。
序列前向选择。目前我找到两个最好的,为了顺利找到三个属性,我们把其余的属性分别和已经确定的两个属性拼在一起计算J值。
序列后向选择。我们有10个属性,每次删掉一个对J值影响最小的属性。
使用优化算法:
1)模拟退火
2)禁忌搜索
3)遗传算法
11 主成分分析
11.1 特征提取 feature extraction
特征选择是指从n个属性中选择m个属性,特征提取不是简单的从属性中进行挑选,而是对原始的属性做了某种变换。
11.2 主成分分析 principal component analysis
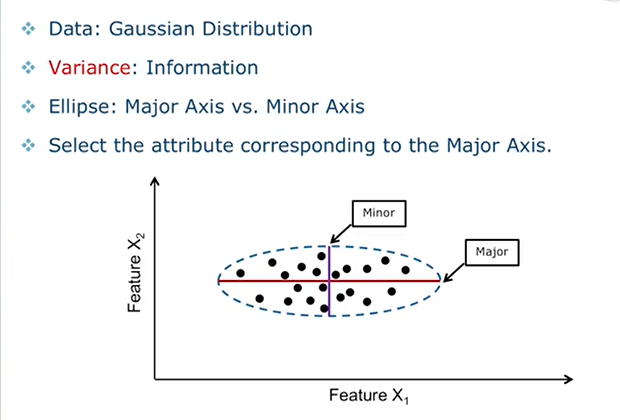
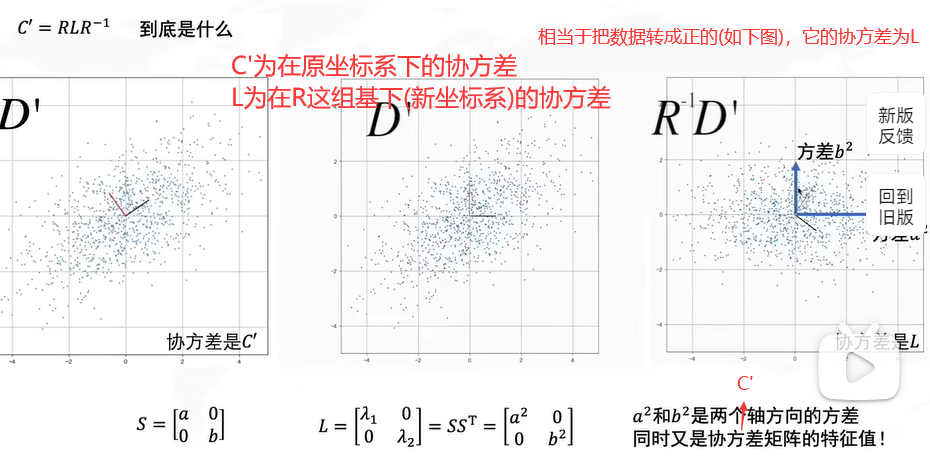
我们用方差来衡量信息是因为如果所有人的身高都是一样的,那么就无法从中获取信息。所以方差大代表信息丰富。
如果我们要从两个属性中选择一个,那么一般情况下我们更倾向于选择方差大的属性,例如在上图这种情况下,我们选择Feature x1更为合适。
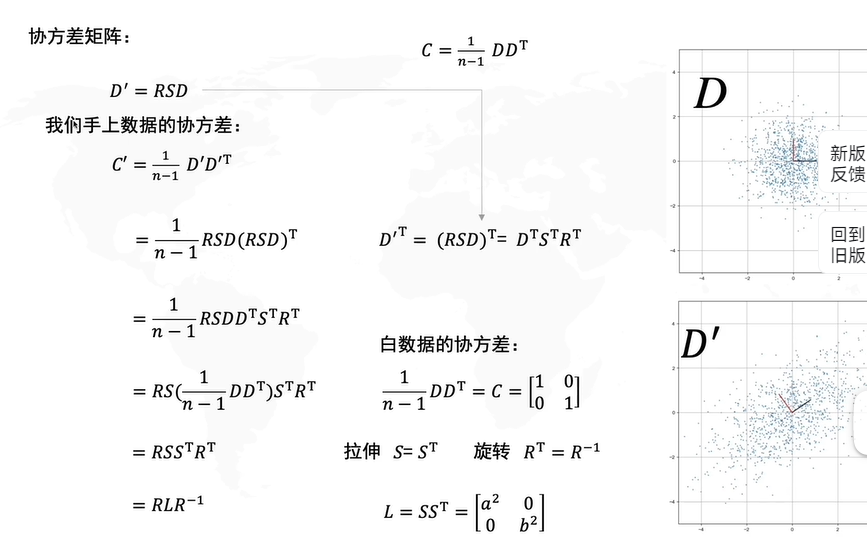
但对于不是平行于坐标轴的数据,我们需要对坐标轴进行一个变换(旋转),这样就使得数据的分布变得像上图一样的便于选择。具体变换方法如下: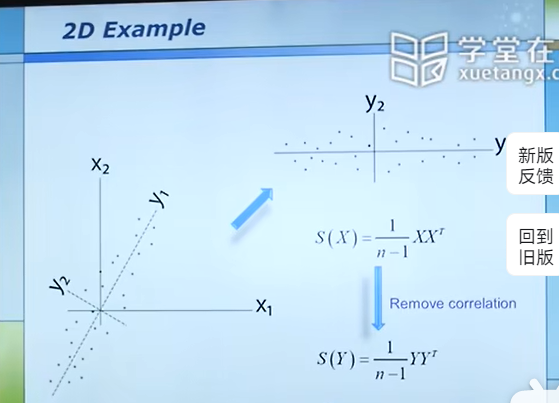
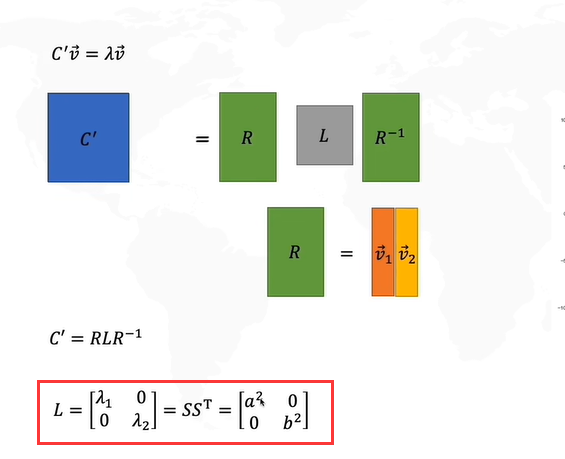
我们的目标是使得S(Y)的对角线是非零的,其余位置都是0。
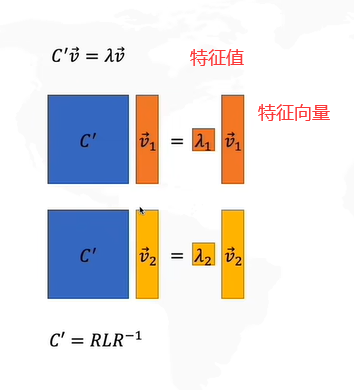
我们pca的目的是为了在投影之后,每一个样本和原来的位置之间尽可能地接近。最终pca在做的事情就是把原始数据投影到特征向量上,该向量是特征值最大的那一个特征向量。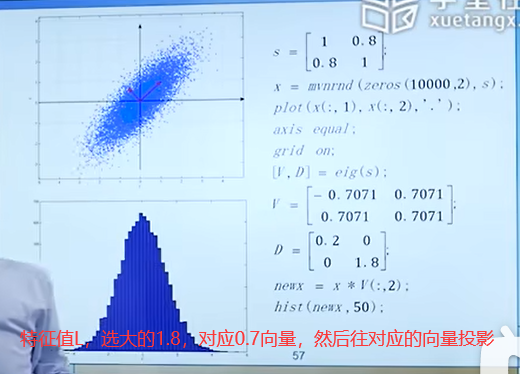
接下来是pca的详细推导过程和求解过程: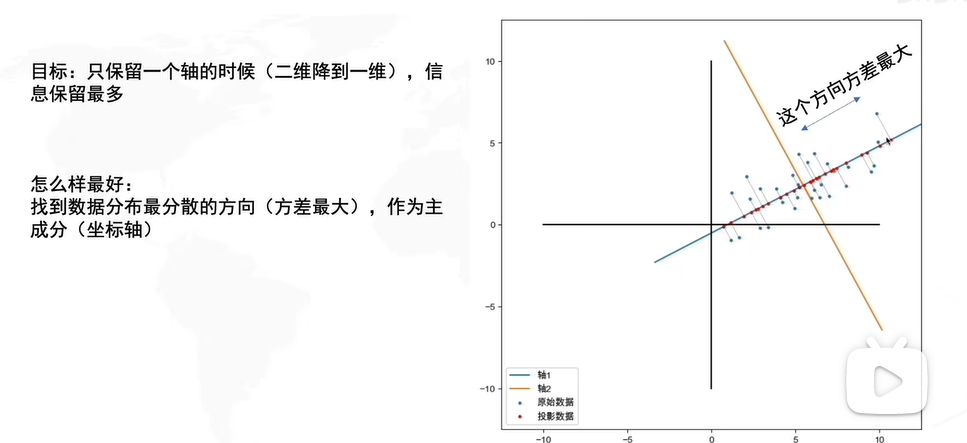
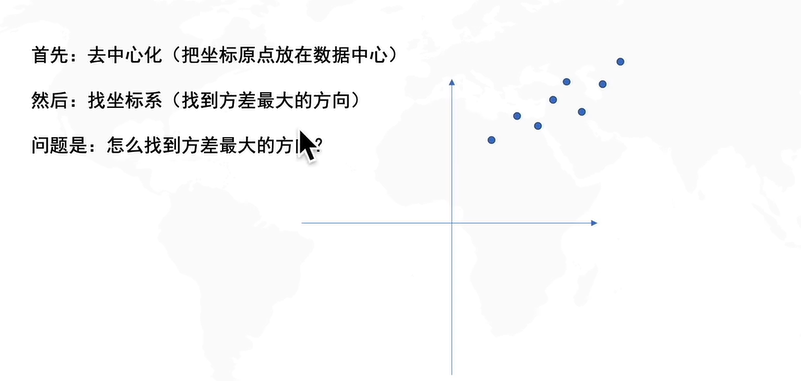
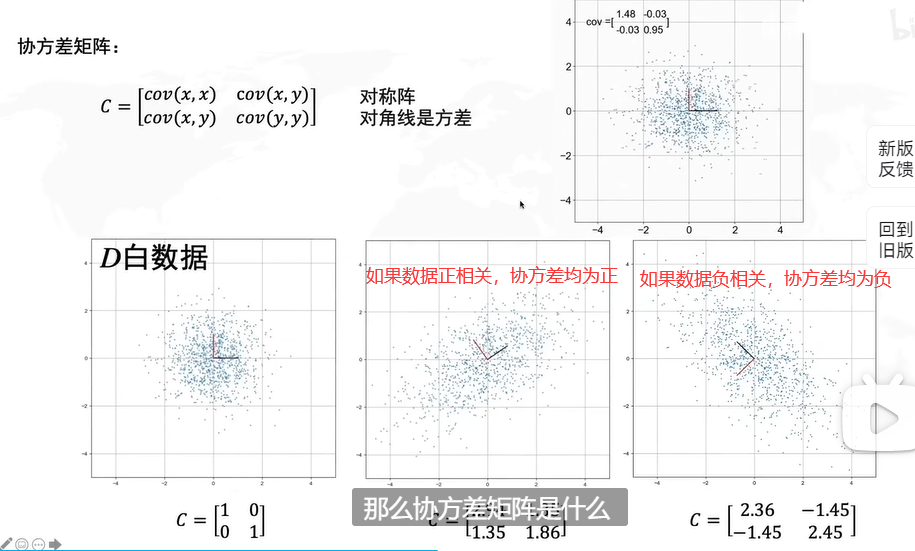
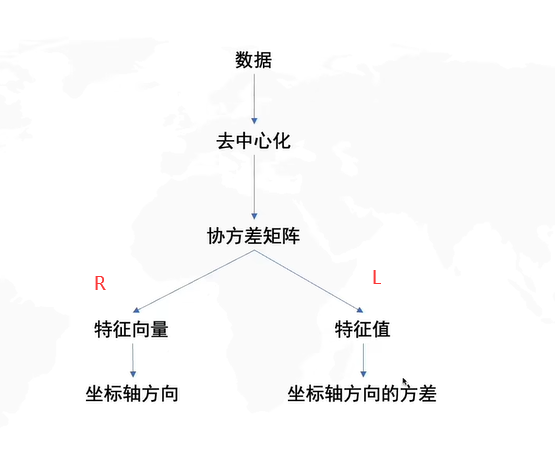
如果不进行去中心化,即把原点放在数据的中心,才能发现方差最大的角度,这个角度是PCA的主要目的。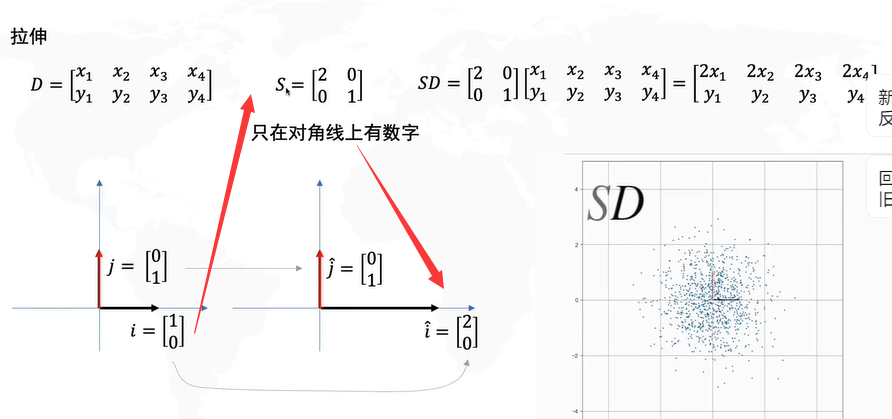
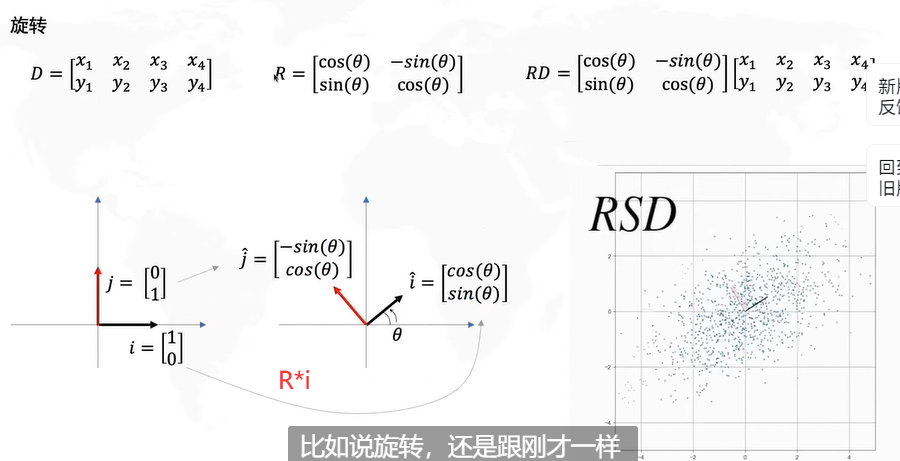
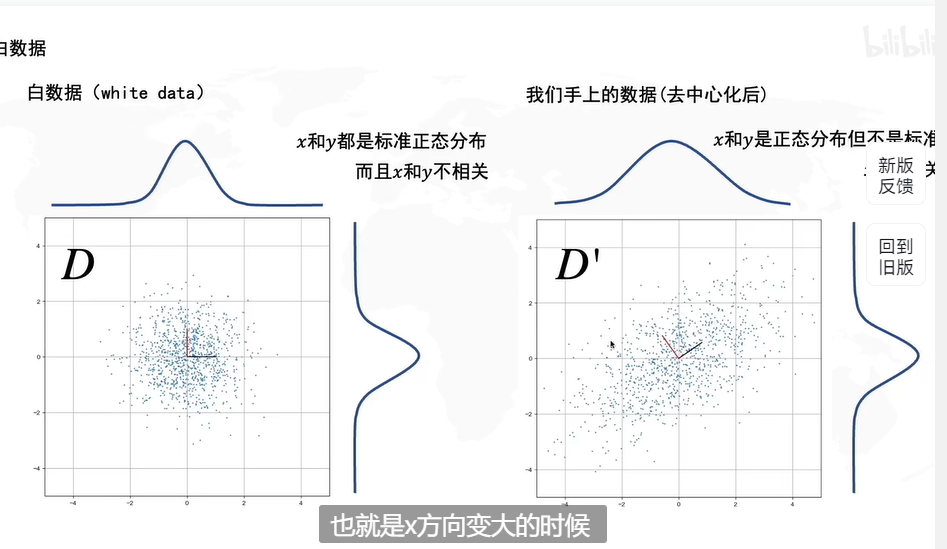
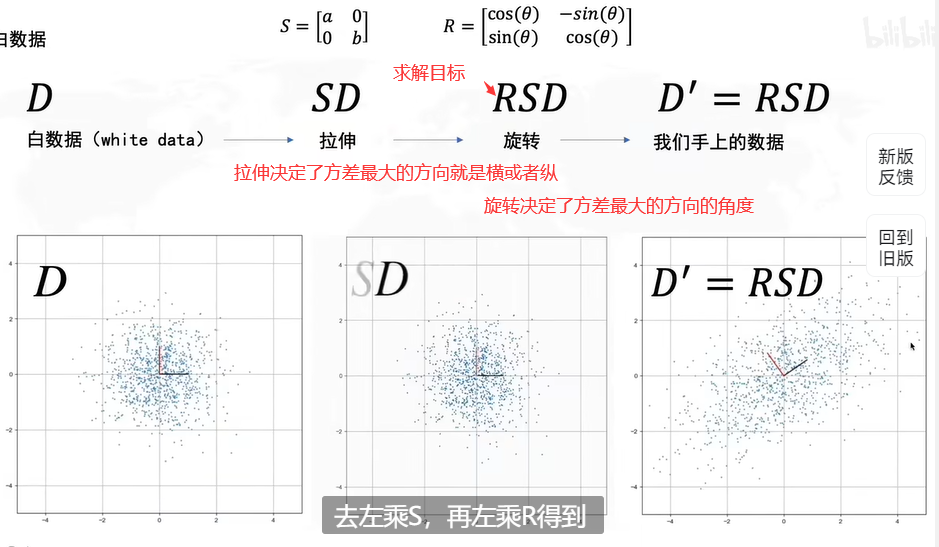

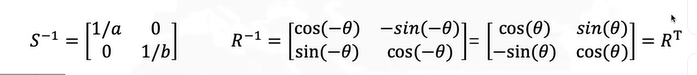
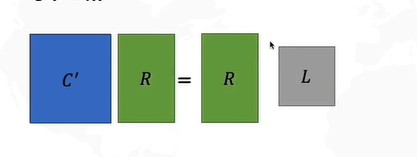
怎么求解R呢?协方差矩阵的特征向量就是R。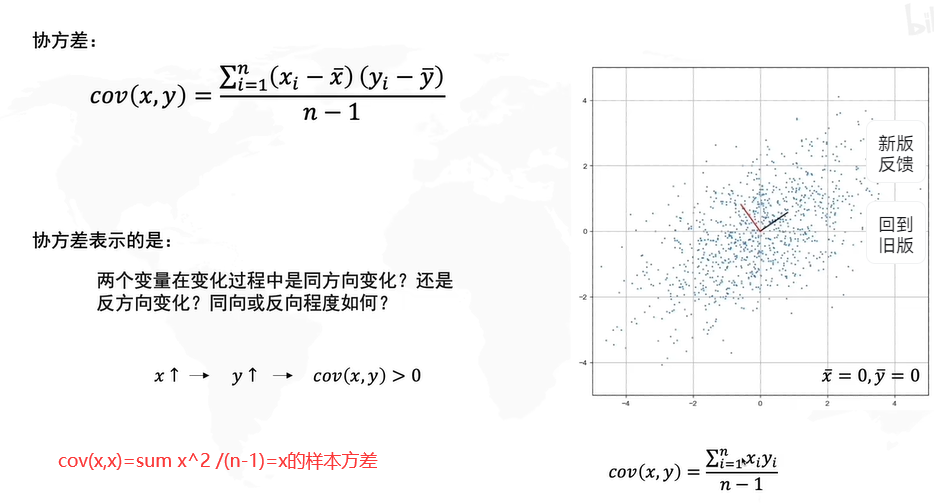

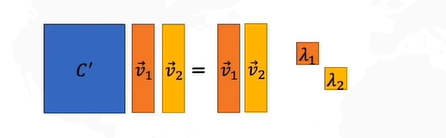
参考视频
拉格朗日乘数法
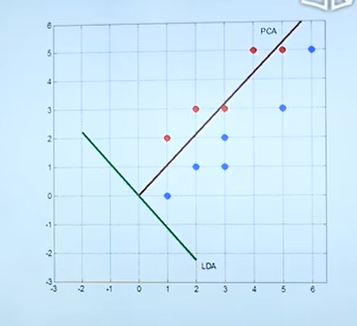
12 线性判别分析
12.1 线性判别分析 Linear Discriminant Analysis
PCA是非监督学习,它在确定投影方向时不会考虑分类。经过投影之后可能导致原来可以分开的数据在PCA之后分不开了。
对于有标签的数据,我们要采用线性判别分析。LDA在进行数据降维的同时,会保留类的区分信息。
什么样的数据称为分的比较开呢?不同的类之间的距离很远,同一个类的数据距离很近。我们可以用Fisher判别来量化分开的程度。



12.2 C-Class LDA

Sw矩阵就是计算各个类的散度,完了加起来就好。
Sb矩阵中μ是所有样本的均值。然后用每一个类的μi-μ,再乘上(μi-μ)的转置,前面需要加一个系数Ni,为该类中样本的个数。
n个类的投影可以投影到n-1个方向。如3个类可以投影到两个方向(两个特征向量),但是这两个方向不一定正交。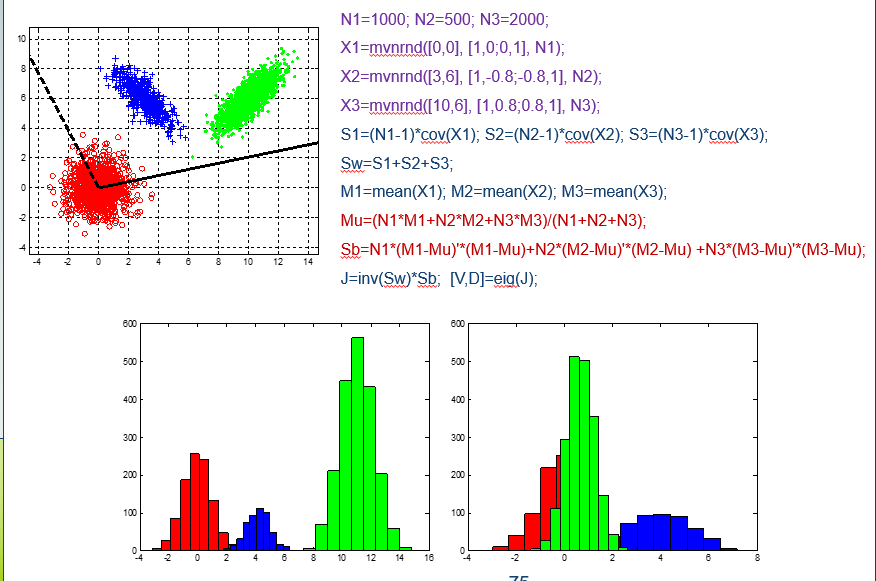
12.3 Limitations of LDA
Sb矩阵的rank最大就是C-1。例如在2分类问题中,矩阵rank=1,只有一个特征值不为0的特征向量。
Sw可能是奇异矩阵。奇异矩阵的逆矩阵是不存在的。当样本点的个数低于维度,那么生成的Sw矩阵就不是满秩的,也就不存在逆矩阵。在实际问题中,一个图像的维度是256*256,但是却没有足够多的样本,此时Sw就会变成奇异的。所以此时可能需要先用PCA方法降维,然后再使用LDA方法。
LDA的目标函数是
如果μ1=μ2,不管怎么投影,都会重合。
13 贝叶斯奇幻之旅
13.1 分类 Classification
分类是一种有监督的学习。对于数据都有相应的标签。
分类问题可以看成一个函数,输入是样本的各种属性,输出是样本所属的类别。
13.1 贝叶斯理论 Bayes Theorem

14 朴素是一种美德
14.1 朴素贝叶斯分类器 Navie Bayes Classifier
基于贝叶斯原理的分类器,本质上就是基于后验概率的分类,比如一个属性,我们计算属于A类的后验概率和属于B类的后验概率,哪一个后验概率大,就属于哪一类。
在比较后验概率的过程中,贝叶斯公式的分母都是相同的,我们在比较大小的过程中,只需要比较分子即可。
贝叶斯分类的难点在于先验概率的确定。所以采用了一种简化的方式。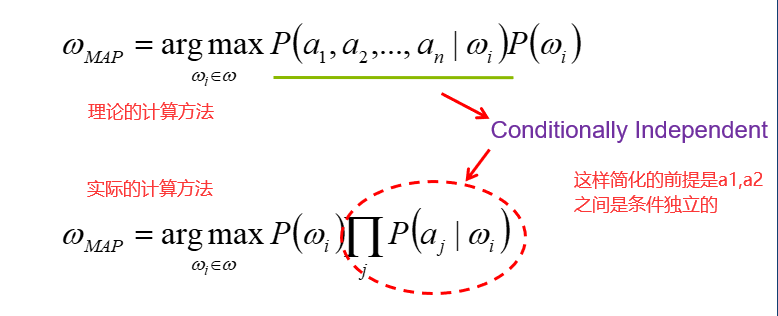
14.2 独立 independence

独立≠相关。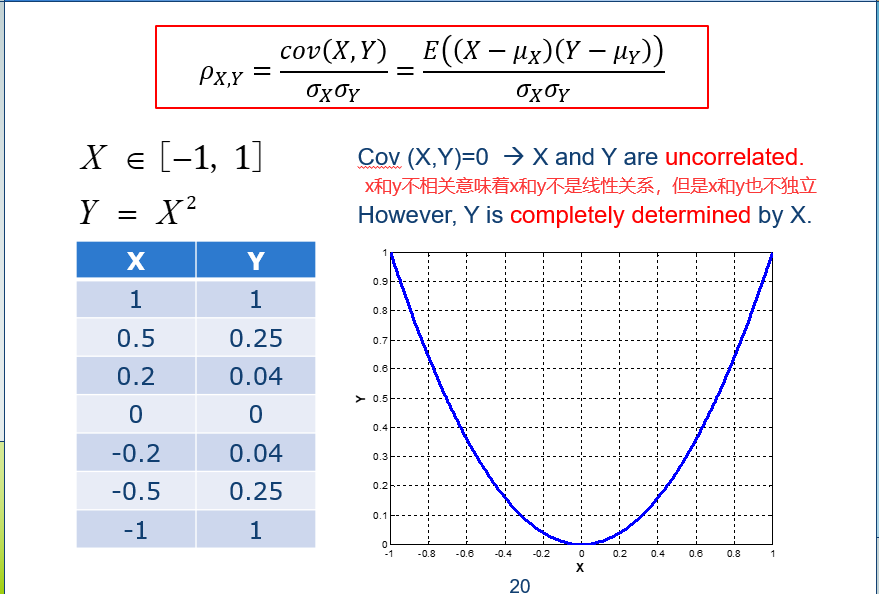
在使用贝叶斯方法解决问题时,如果我们有一个数据库,里面记录了男同学的一些特征,比如头发长度,一般为短,女同学的特征,比如长头发……如果我们输入的数据是一个长头发的男同学,在系统中会认为男同学是长发这个先验概率为0,在进行一系列乘法之后,结果全为0,就会导致长头发是男同学这一后验概率为0。为了避免出现上述问题,我们采用下图中的式子对概率进行一个Laplace平滑。

14.3 文本表示 text representation

15 数据、规则与树
15.1 决策树 decision making
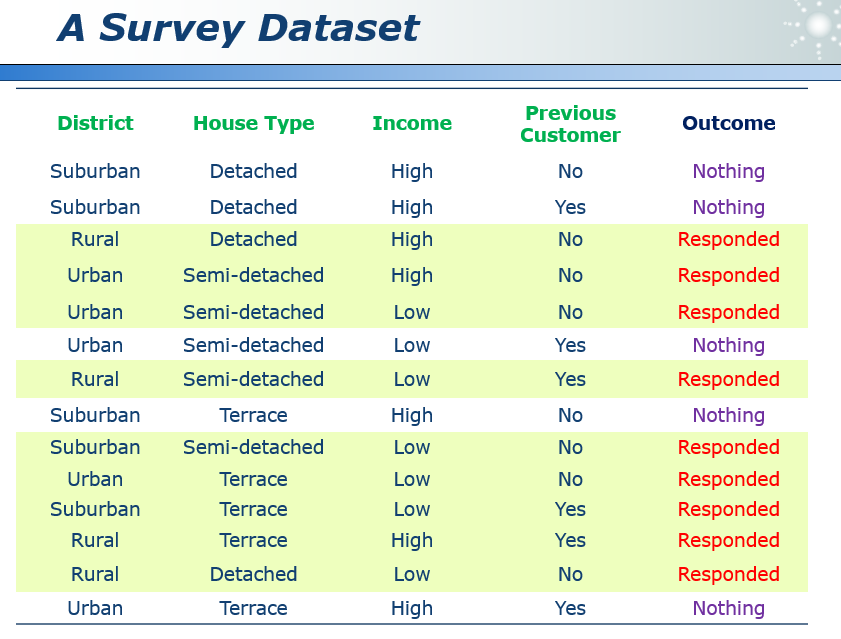
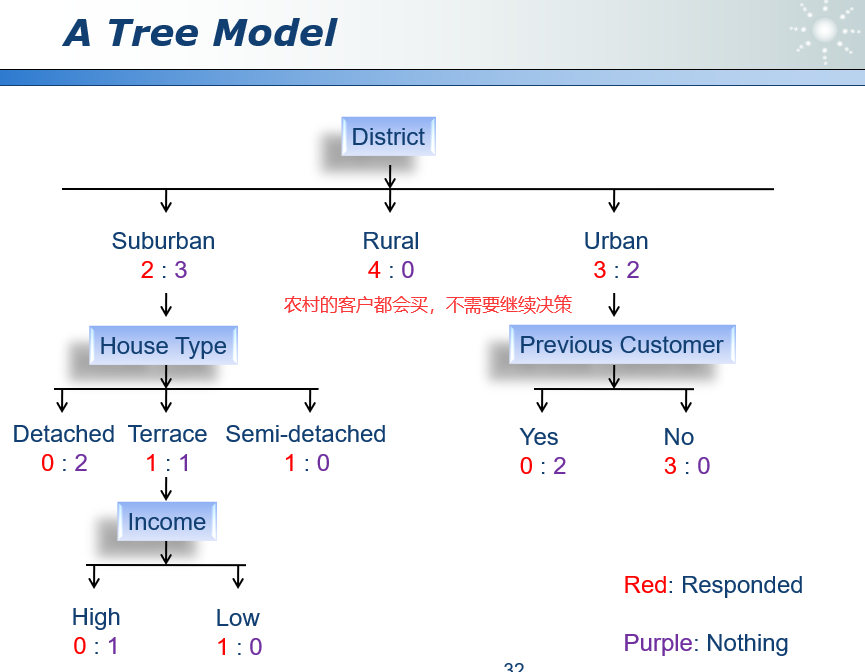
这个树的结构不唯一。
建树可以帮助我们更容易地发现规则。
一个数据集可以生成许多可能地树。
我们更喜欢使用简单的树。
16 植树造林学问大
16.1 ID3
首先我们需要考虑使用哪些属性作为决策的依据,我们需要把比较强大(更具有区分度)的属性放在树的上面的位置。那么我们需要一个指标来量化这些属性的区分度,这个指标就是熵,主要是用来衡量一个系统的不确定性。(详见10)。

因为ID3涉及到建树,所以算法框架一定是递归结构的。
首先,我们要从大量属性中挑选出效果最好的那一个,作为根节点,然后向下递归,建立当前节点的子集。如果子集样本是纯的,也就是都指向一种决策,那么就打上对应标签。如果子集样本不纯,则需要继续向下递归,属性是随机选择的,并没有按照增益排序。(用过的属性不能再用)如果属性全部用完了,还是不纯,那么就需要少数服从多数。
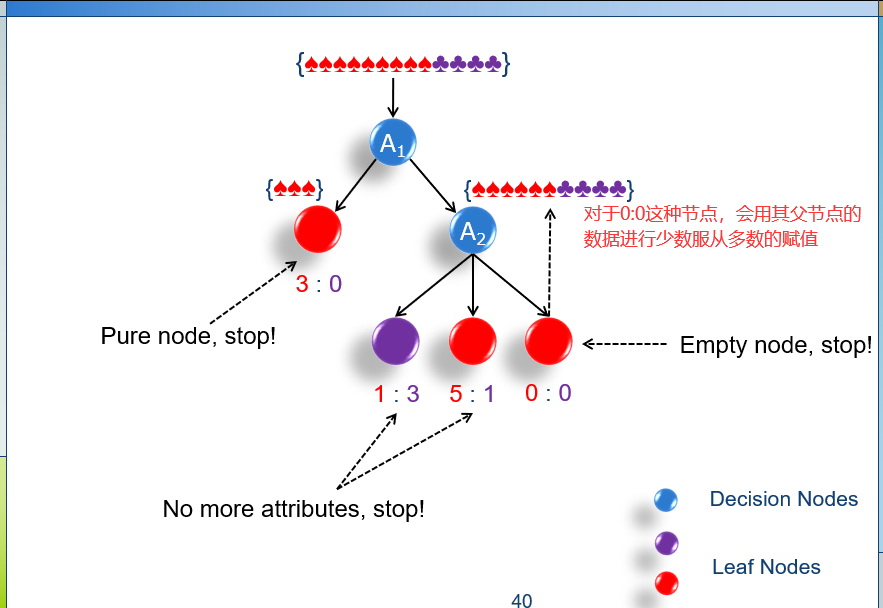
16.2 过拟合 overfitting
如果有两个分类器A和B,A在训练集上的误差比B要小,但是A在测试集上的误差比B大,那么分类器A过拟合了。
防止过拟合:
1)限制树的高度。
2)不对建树过程有任何限制,但是对树进行剪枝操作,以提高它的泛化能力。(在测试集上的性能)
16.3 剪枝 pruning
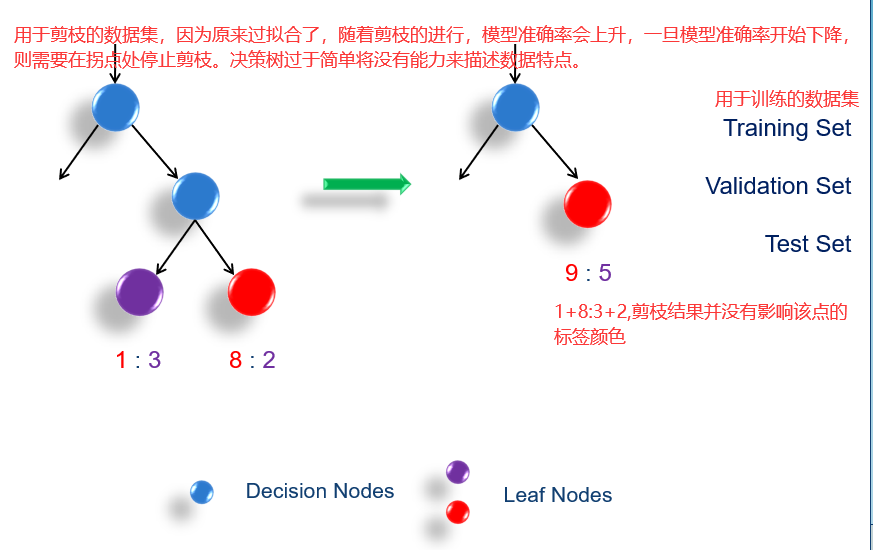
16.4 熵偏差 Entropy Bias
算法会倾向于把不确定性降低最大的属性,例如当判断一个人的性别时,身份证号可以直接将不确定性降低到0,但是我们不太喜欢这种会把数据分的特别碎的属性,近乎是一个人一条规则,这样的属性很容易就会过拟合。
因此我们需要引入惩罚机制(penalize),如果一个属性把样本数据分的类越多,那么惩罚值越大。
16.5 连续属性 Continuous Attributes
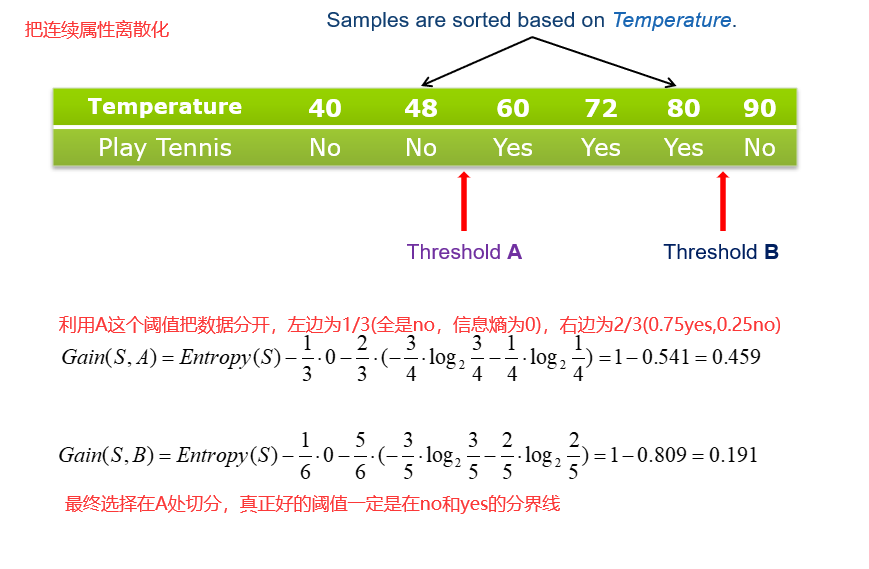
17 智慧之源神经元
大脑的存储和计算全部都是分布式的。两种研究方向:
1)使用ANN研究和模拟生物学习过程。ANN人工神经网络(感知机算法,BP算法),只有输入层、输出层、隐藏层。隐藏层数据根据需要而定,每层神经元与下一层神经元全连接,不存在同层及跨层之间的连接。CNN,卷积神经网络,引入了局部连接。更多讲解
2)获取高效的机器学习算法,无论这些算法与生物过程的相似程度如何。
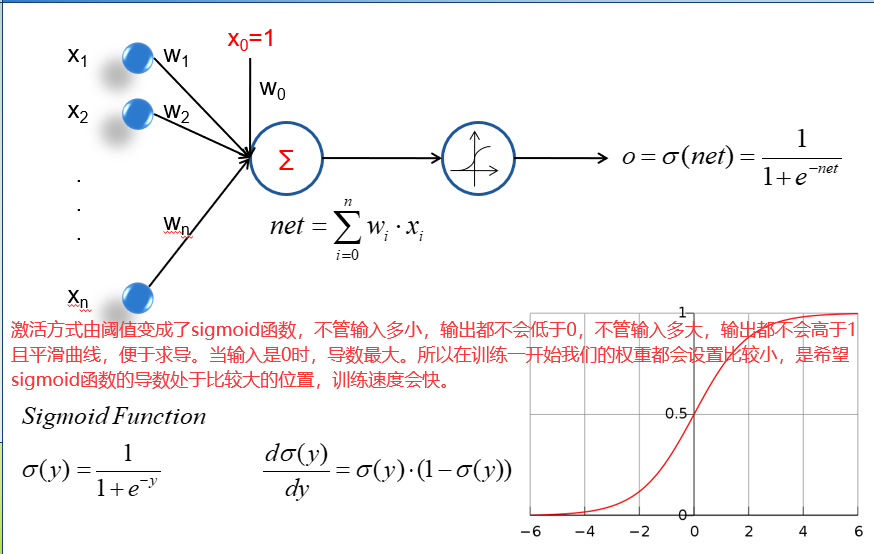
17.1 神经元 perceptrons
一个神经元有若干个输入,其实就是n个属性。然后每个属性的输入值和属性的权重做一个向量的内积。特别注意的是神经元会有一个w0的输入对应的s0=1,相当于一个偏置值。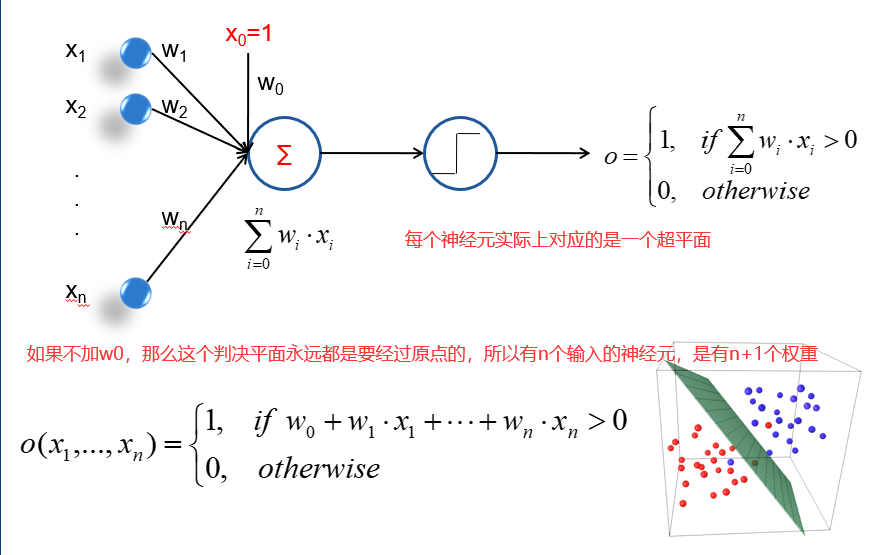
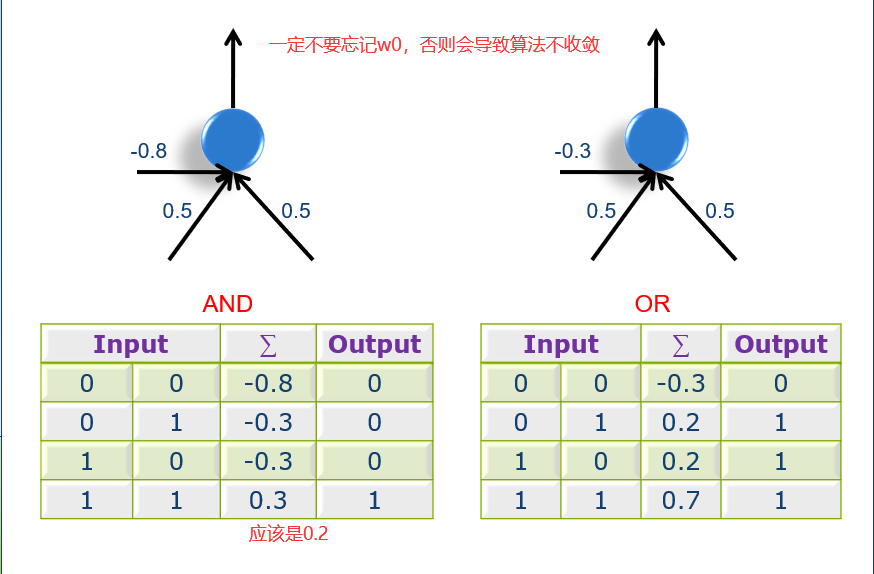
学习进度
18 会学习的神经元
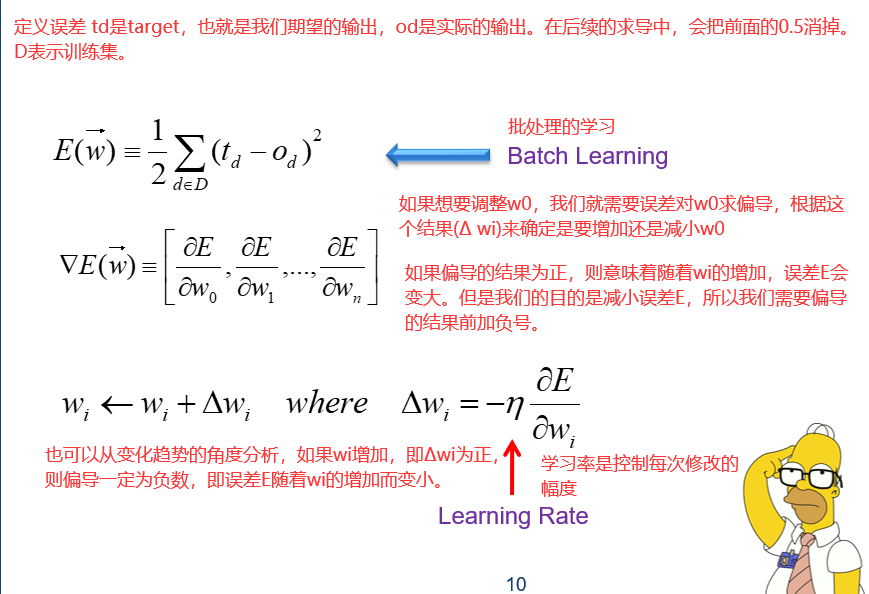

batch learning(批量学习)
Stochastic Learning(知错就改),特点是每次计算出Δw之后立即修改。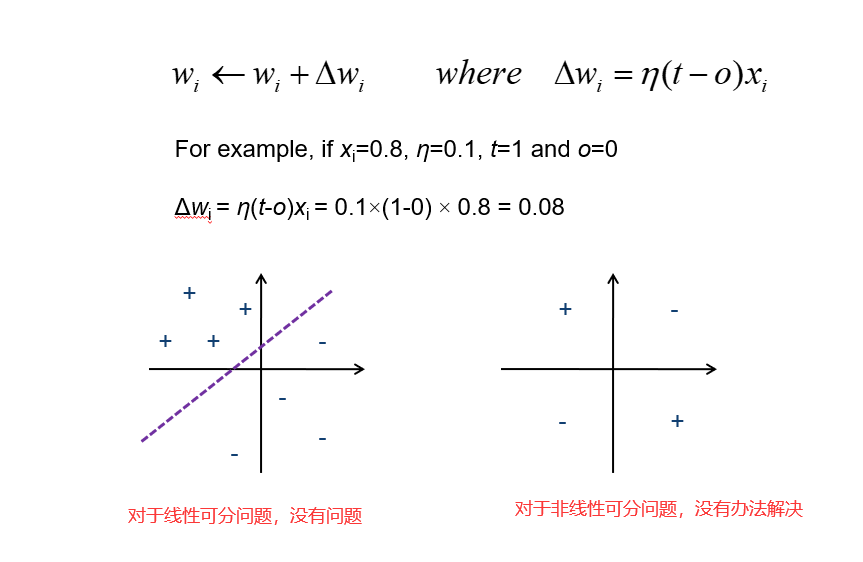
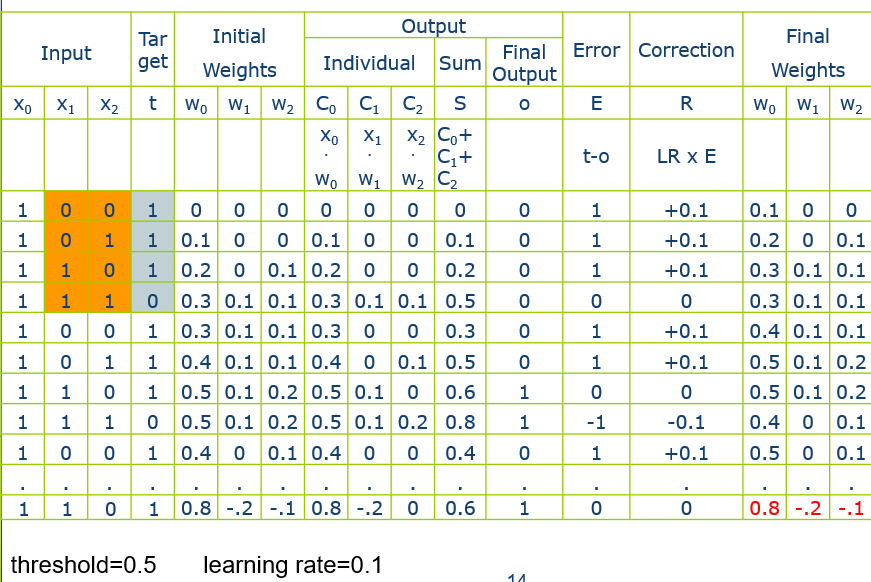
19 从一个到一群
19.1 多层感知机 Multilayer Perceptron
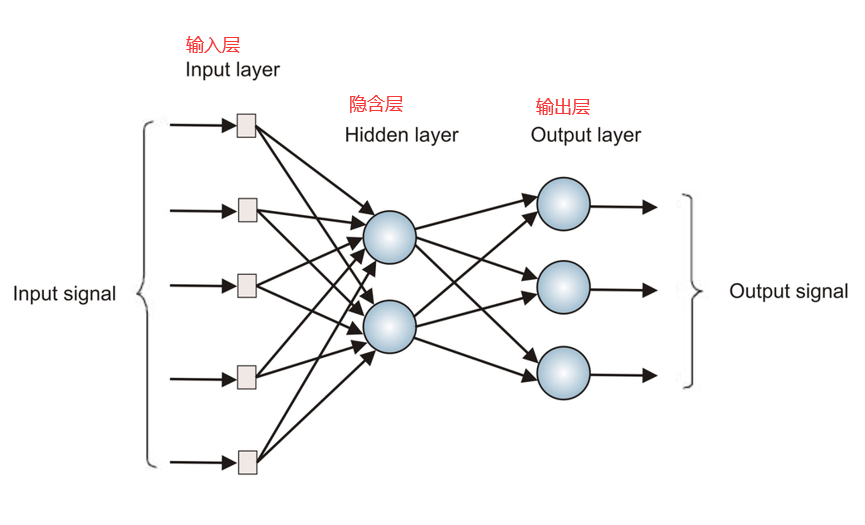
多层感知机主要是为了解决线性不可分问题。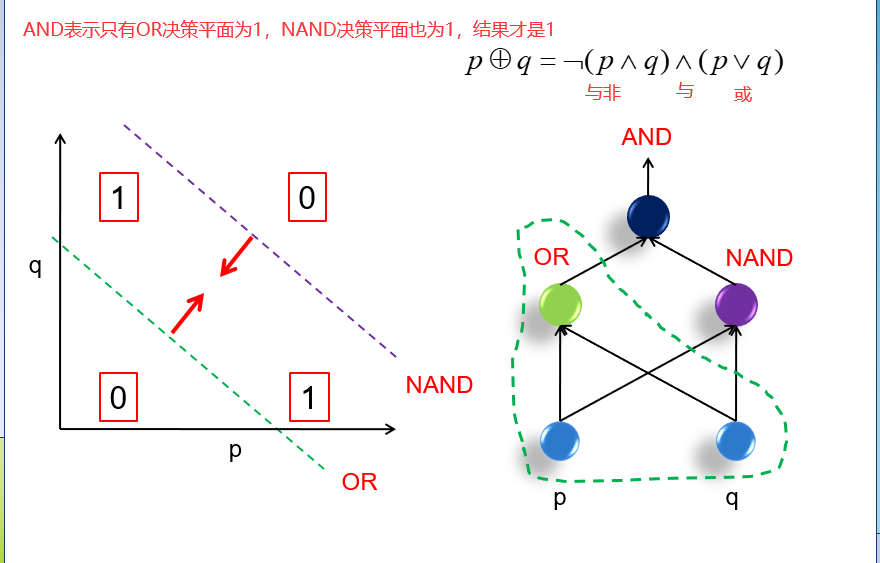
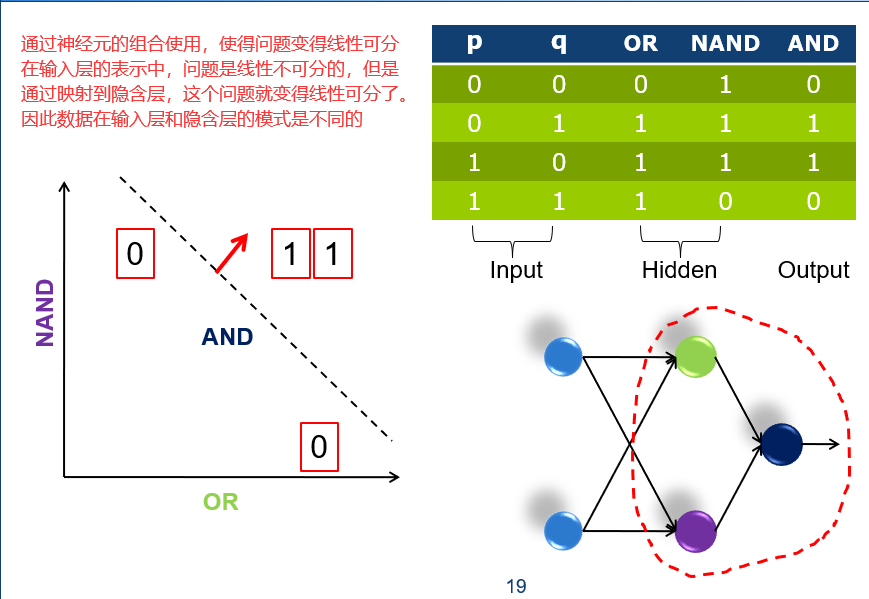
20 层次分明,责任到人
20.1 误差反向传播算法 Backpropagation Rule
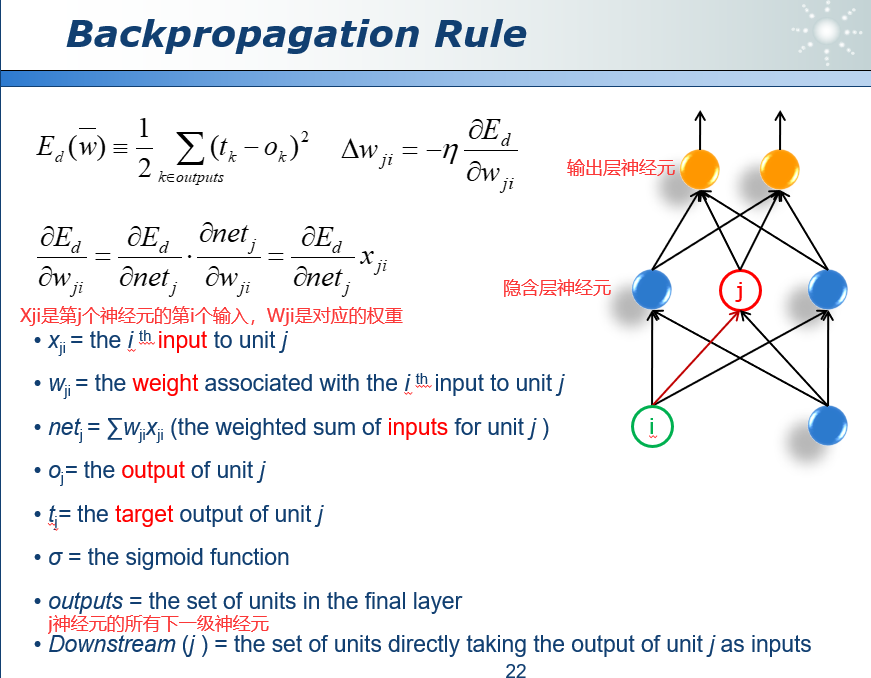
具体见19。
我们有下面推导: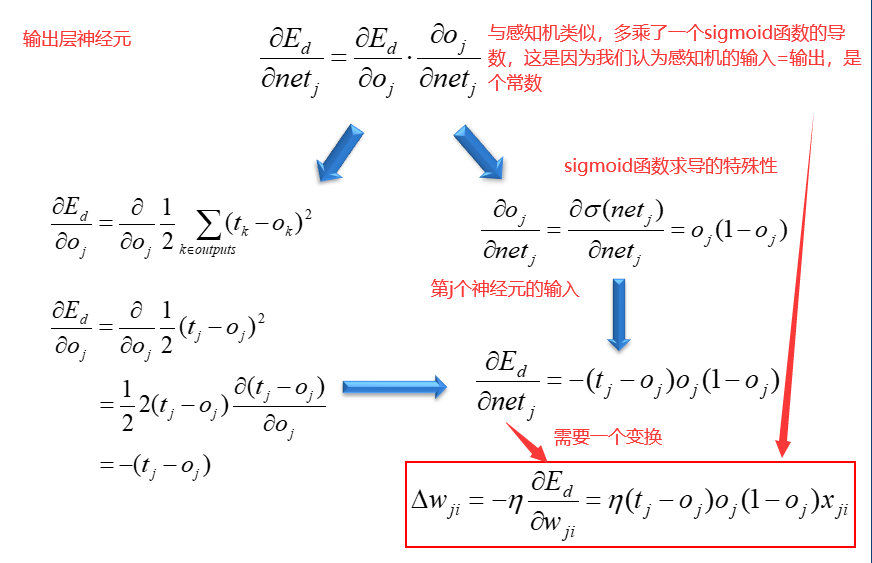
对于隐含层的误差,我们用输出层的误差反馈回来来计算。就像是一个公司的领导,派出两个助手去完成一件工作,当这个工作产生差错时,差错会计算在领导的头上。
但是领导的误差并不是简单的下属误差相加,我们会对每个下属的误差赋权重,如果下属A对领导的话言听计从,那么误差权重会大,反之,则会小。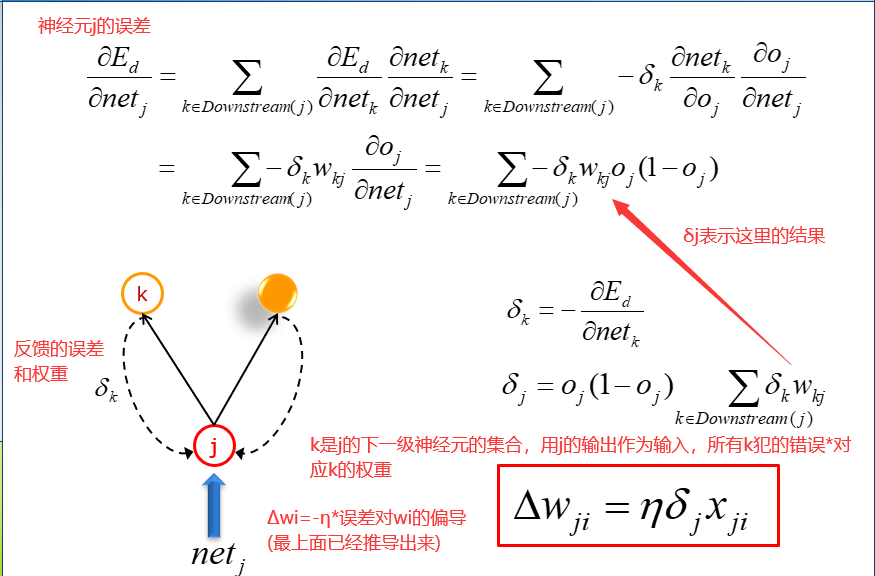
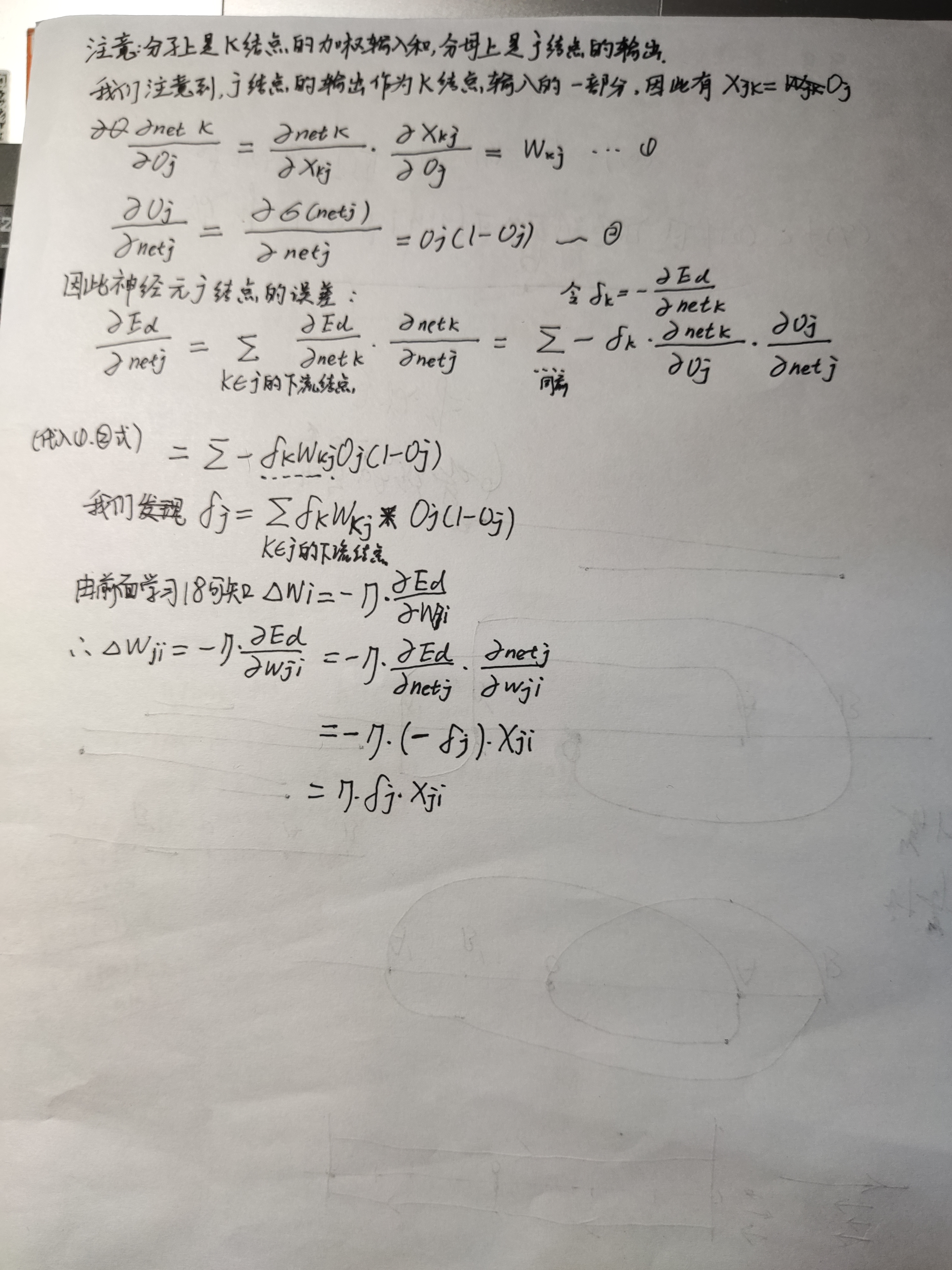
所以在使用网络的时候,是前馈网络,在训练的时候,计算误差是从output到隐藏层。
BP网络是基于求导法则,因此如果数据有局部最优点,那么可能在训练过程中,网络的误差就稳定了,不再降低。因此需要具有不同初始权重的多次实验。
20.2 过学习 overfitting
在遇到局部最优点时加冲量,就像是一个小车从山坡上往下滑,即使是平地,我们可以加一股力量,帮助小车继续前进。也就是红框中公式写的,在n时刻的修改量还与n-1时刻的修改量有关。
学习率我们一般设置成0.05,0.1,0.2,不能太大,也不能太小。这就类似于我们在走路时迈出的步伐大小,如果步幅太小,那么容易掉到坑里,如果步幅太大,那么容易直接跨过了较优解,那么网络的误差就会产生震荡,w增大后,Δw表明w应该减小,w减小后,Δw表明应该增大。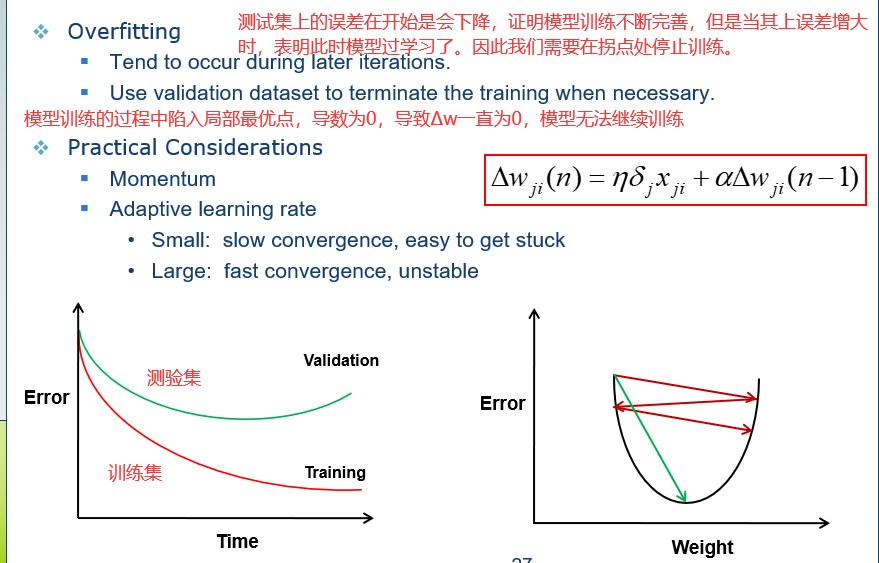
21 管中窥豹,抛砖引玉
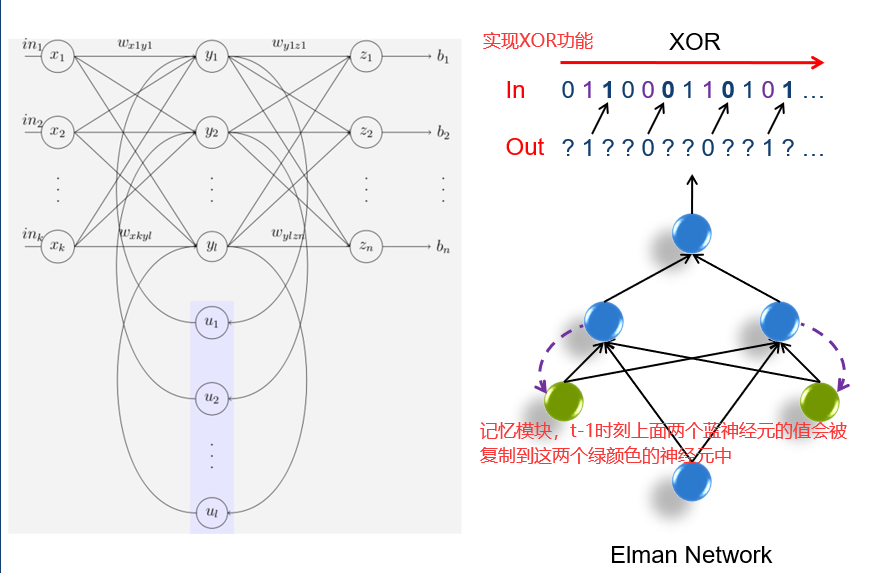
21.1 Elman网络
21.2 Hopfield网络
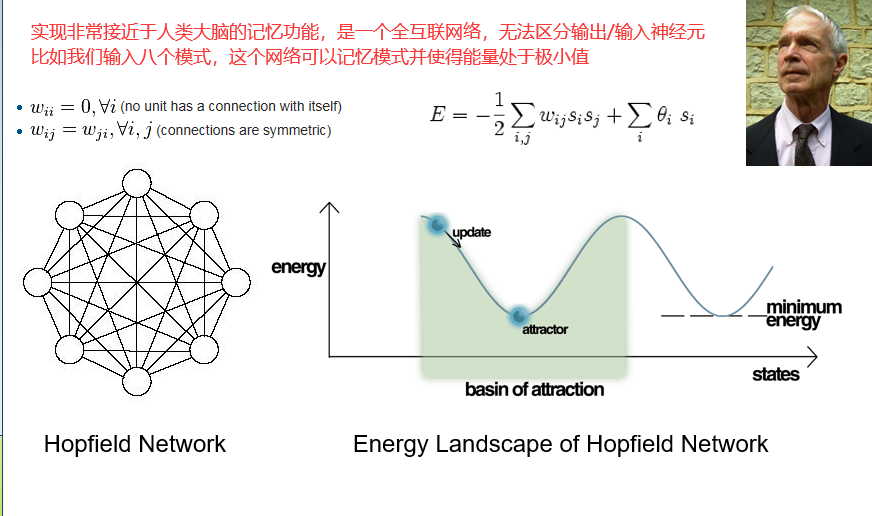
21.3 什么时候使用ANN
训练时间可能会比较长,但是在使用时反应速度很快。与决策树相比,可解释性降低,因为全是权重,如没有办法向别人解释为什么网络判断这个东西为苹果。
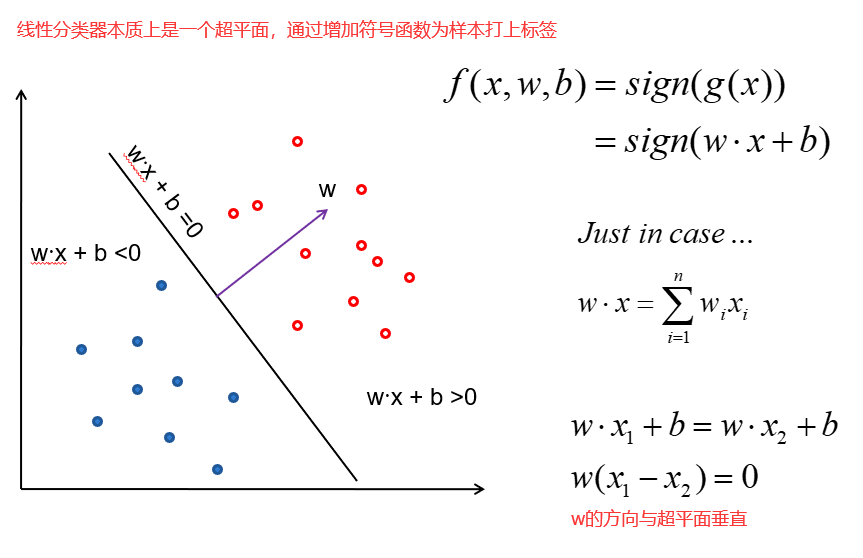
22 最大间隔
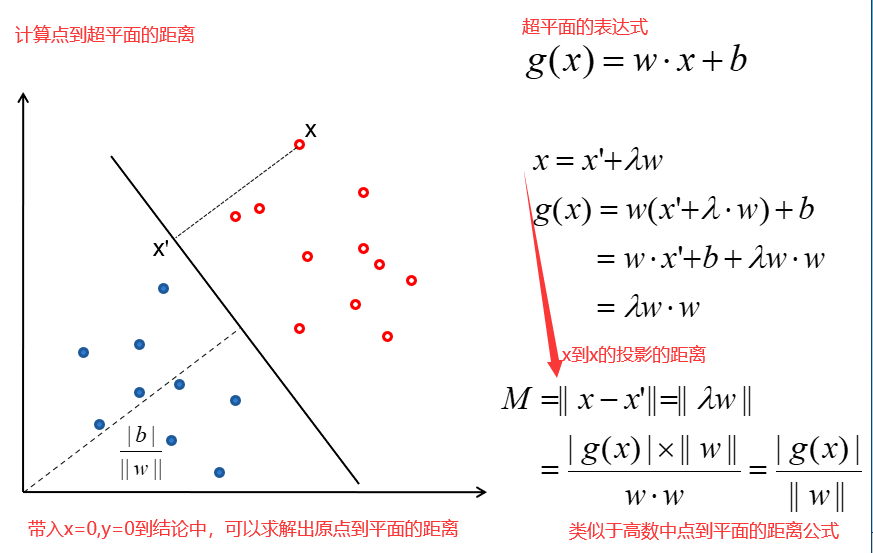
高数中点到平面的距离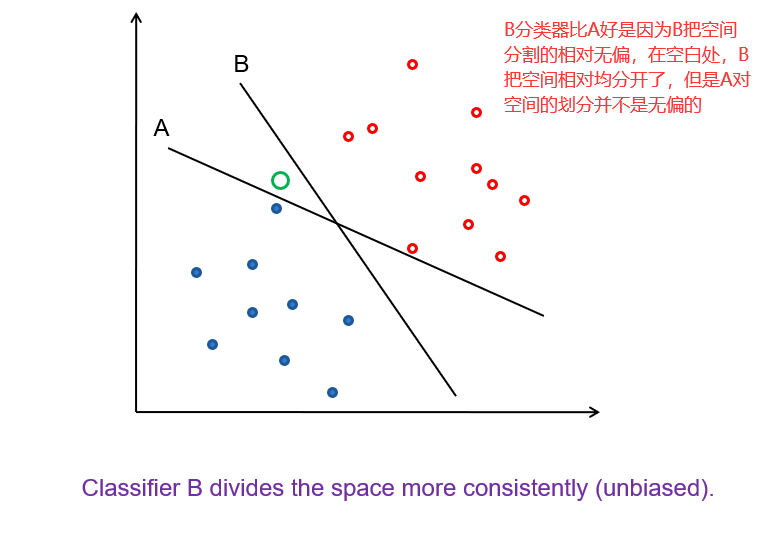
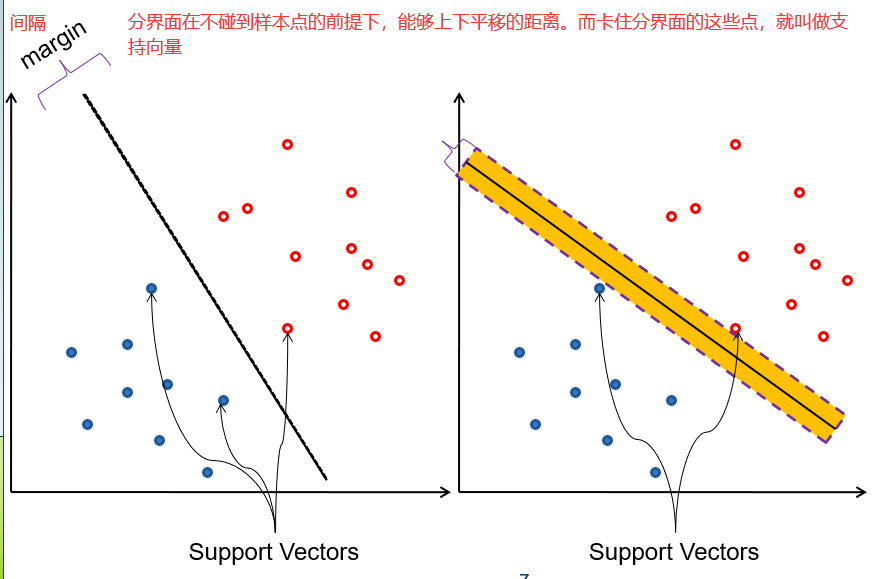
margins(间隔):就是一个分界面可以移动的范围。间隔越大代表分类器的容错能力越强。margin的宽度就好比马路的宽度,如果margin比较小,那么车稍稍偏离路线就掉到路边了,但是如果margin比较大,即使车稍稍偏离路线,也依然可以顺利通过。
在SVM算法中,真正有用的是处于分界面的点,也就是能够限制分界面移动范围的点,其他的点就直接被扔掉。所以SVM最早就是一个线性分类器。它和一般线性分类器的区别在于,可以最大化margin。这种SVM通常又被称为Linear Support Vector Machines(LSVM)线性支持向量机。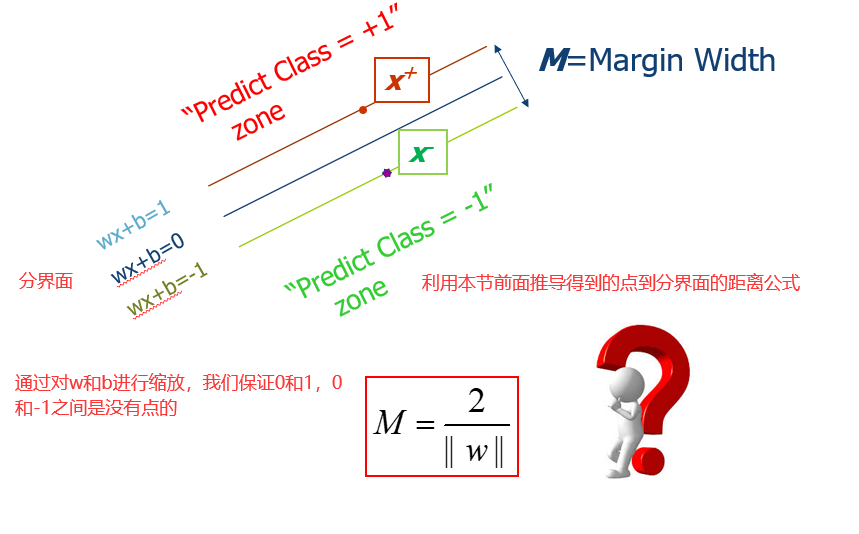
23 线性SVM
23.1 间隔 margin
我们有两个目标:
首先要把所有样本都分到正确的类中,样本的标签分为+1和-1两种,他们的要求分别为:
概括上面两种情况得
其次,实现margin的最大化。
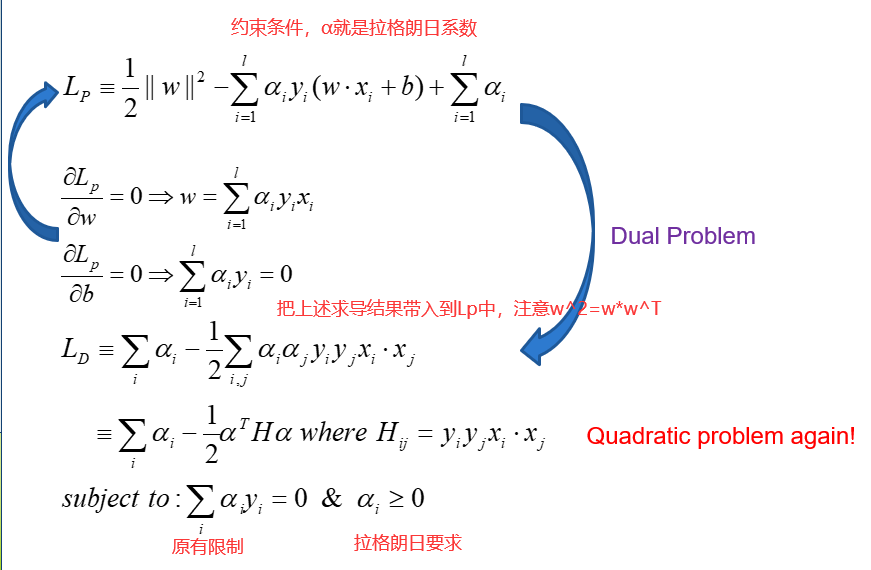
从上图中我们解出了很多α的值,大部分都是0,只有一小部分非零,这些α值对应的点就是支持向量。这是因为
如果α为0,那么w也为0了,就对结论没有任何贡献了。

23.2 软间隔 soft margin
实际中有些样本我们可能没有办法严格要求分界面内没有点,所以我们把要求放宽一点。就好比我们在期末考试中需要达到60分及格,但是由于课程难度比较大,所以我们放宽要求,每人在现有基础上加上10分。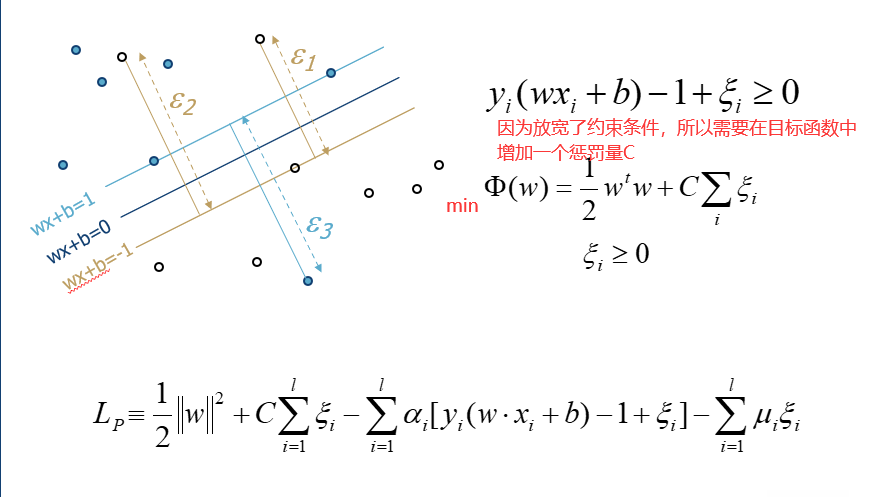

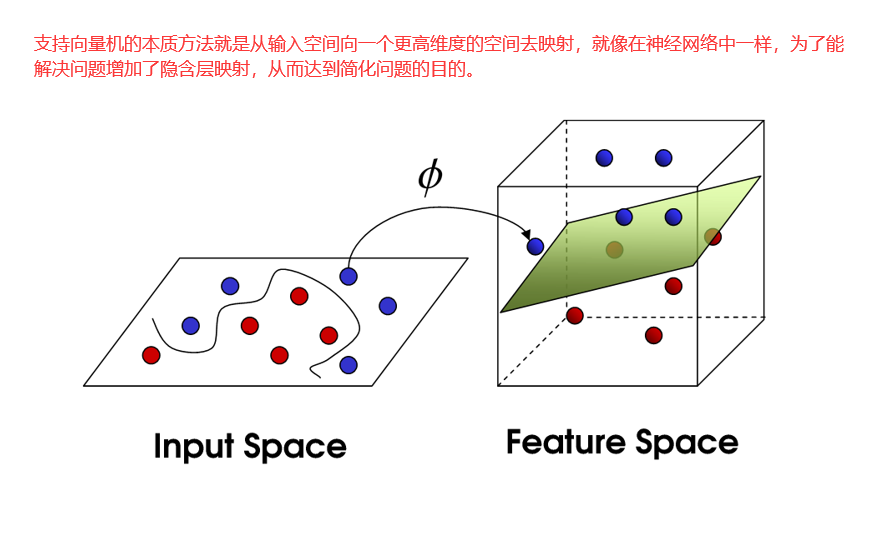
24 数学家的把戏
软间隔并不能解决线性不可分问题。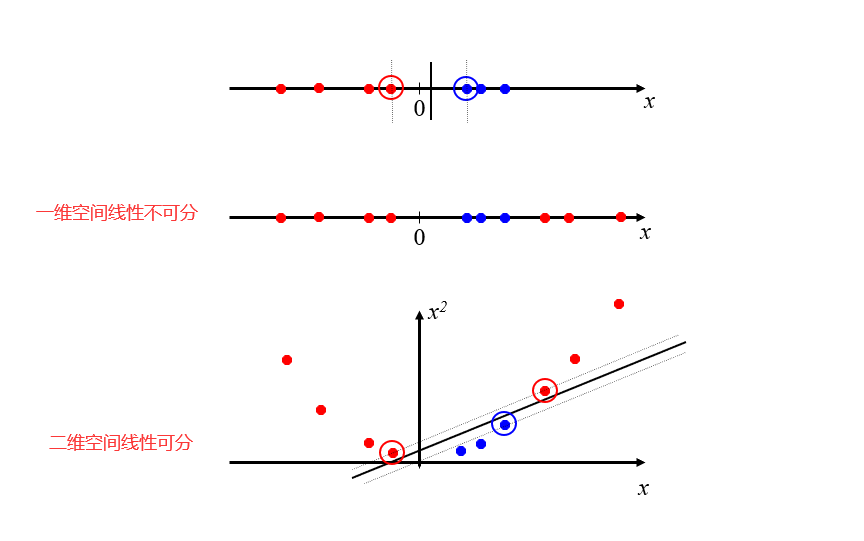
我们把映射到的新的空间称为Feature Space(特征空间)



线性分类器依赖于向量之间的点积。如果每个数据点通过某种变换映射φ:x→φ(x)到高维空间,点积变为φ(x1)φ(x2)
核函数是对应于某个feature space中的内积的函数:
例如
因此SVM既利用了高维空间数据比较好分的特点,又巧妙地避开了高维空间数据计算量比较大的缺点。

string kernel

支持向量机更多讲解
25 致敬真神
25.1 模型能力 model capacity
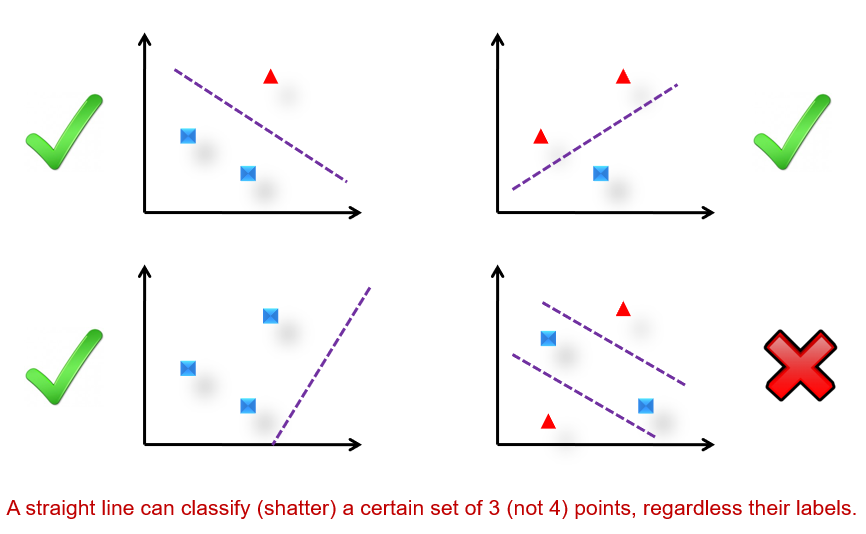
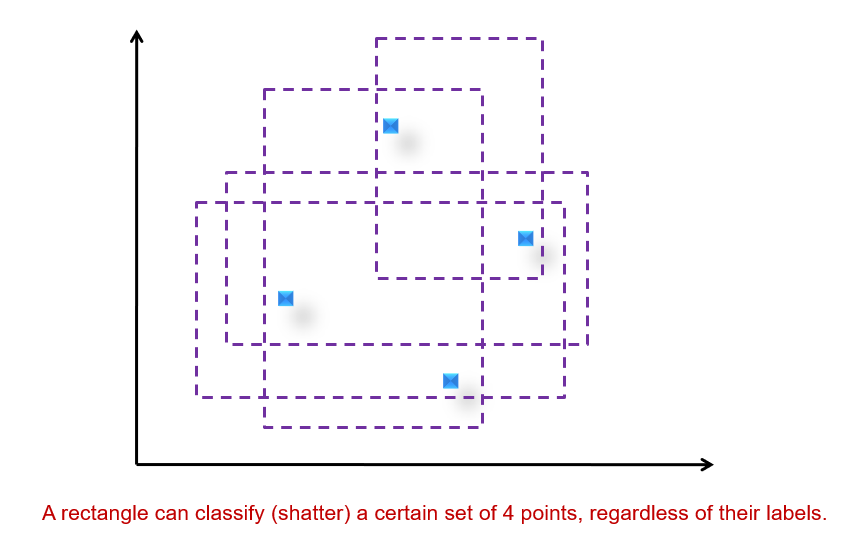
VC 维度(dimension):存在h个点,不管h个点的标签是什么,模型都可以将这h个点很好地分开,那么模型的vc维度是h。
对于超平面来说,在n维空间中的vc维度是n+1(上图的例子)。
对于决策树来说,它的中间节点的个数就决定了它的vc维度。换句话说,一个树如果越复杂,就可以认为它的vc维度越高。
对于SVM来说,取决于使用的核函数。
虽然超平面的VC维度才是n+1,但是在实际数据挖掘问题中,我们首先假设数据都是有规律的,也就是相同标签的样本数据总是倾向于靠在一起的。
26 无监督学习
分割类型的聚类
1)k-means方法。
2)sequential leader方法是序列数据的算法。(见4,27也有)
3)基于模型的方法。
4)基于密度的方法。
分层的方法。
聚类分析就是寻找一簇一簇相似的样本。在一个(intra-cluster)簇内部样本点相对比较相似,在簇和簇之间(inter-cluster),样本点的差距相对比较大一点。
聚类是非监督学习,分类是监督学习。非监督学习没有标签,而且非监督学习是数据驱动的。
因为聚类是无监督学习,所以它没有传统意义上的对错之分。
聚类的应用:
1)市场营销:对具有相似行为的顾客群体进行划分。
2)地震研究:对每次发生地震的地点进行聚类,得到容易发生地震的区域。
要求:
1)可扩展性。
2)能够发现任意形状的集群。
3)相关领域知识的最低要求。
4)处理噪声和离群点的能力。
5)对输入记录的顺序不敏感。
6)结合用户定义的约束。
7)可解释性和可用性。
实际问题中,对坐标进行进行缩放可能会影响到聚类的结果。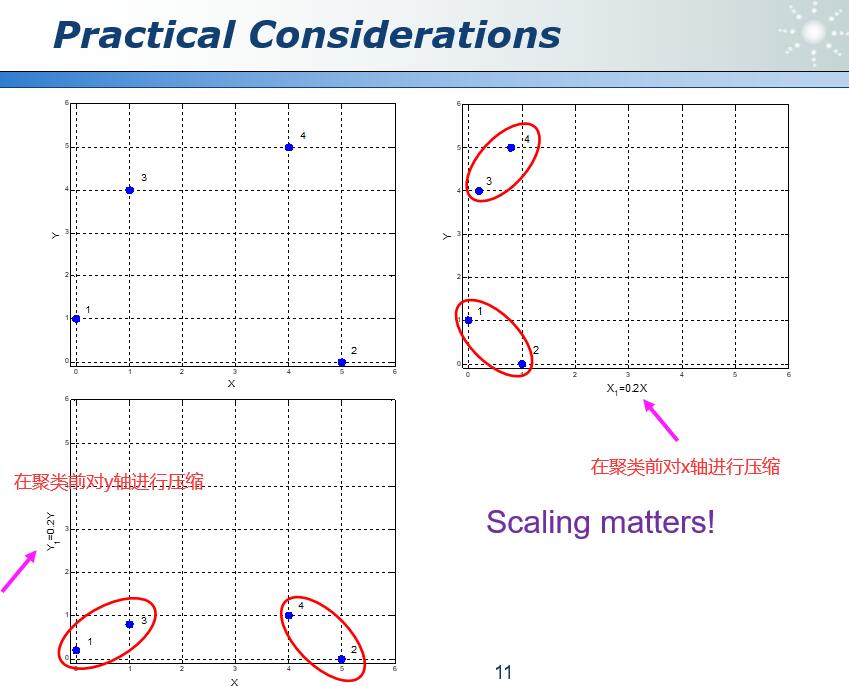
27 K-Means
27.1 K-means
聚类时每个样本点没有标签,但是对于聚类的过程必须有一个评价标准。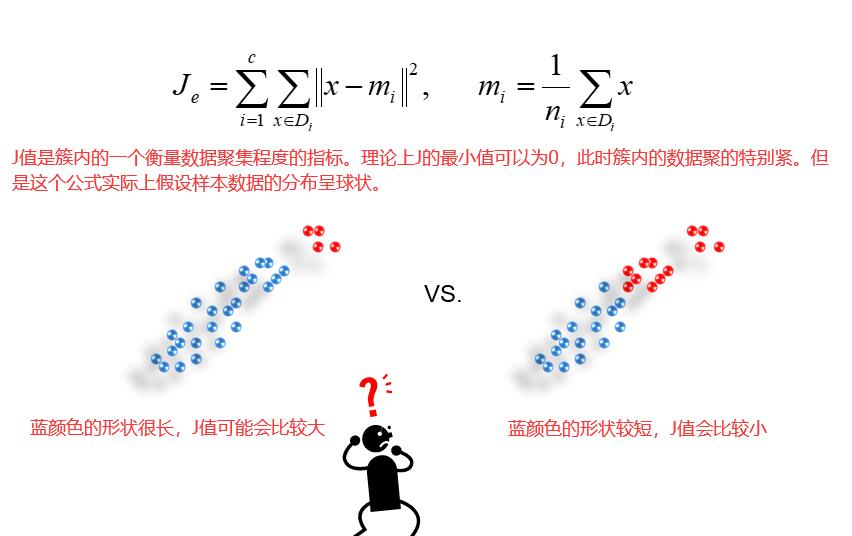
matlab Silhouette函数
可以直观看到或是解释聚类效果的一个函数。a是点i到同一簇中其他点的平均距离。b是点i到其他簇的平均距离中最小的那一个。
当a=0时,s取得最大值为1。当b<a时,s为负数。可能出现负值的情况如下图: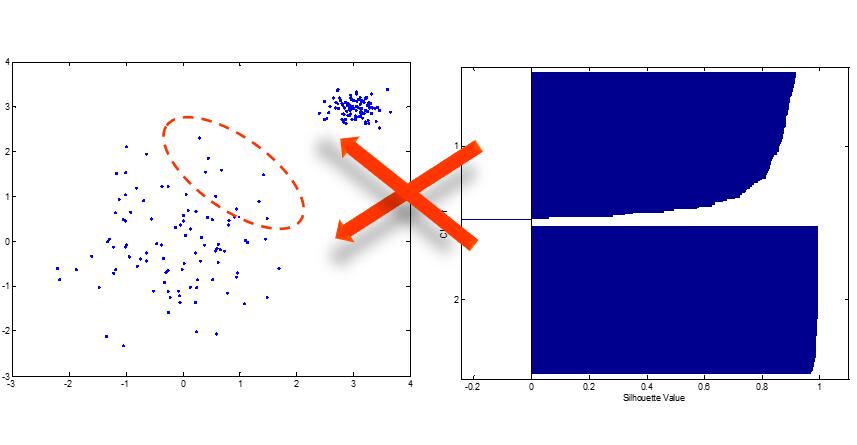

K-means的优点:
1)简单且适用于常规不相交的群(簇的形状不是特别复杂)
2)算法收敛速度快
3)相对高效且可扩展O(tkn)t是迭代次数,k是中心点的个数,n是样本点的个数。
K-means的缺点:
1)需要提前指定K的值。这很困难,并且相关的领域知识可能会有所帮助。
2)可能收敛到局部最优。在实践中,尝试不同的初始中心点。
3)可能对噪声点和离群点敏感。这是因为均值对噪点很敏感,中位数可能会改善这个情况。
4)不适用于非凸形状的簇,一般适用于球星的簇。
27.2 Sequential Leader Clustering
Sequential Leader Clustering可以处理流数据。
1)它不需要迭代,算法执行一次就可以得到结果。
2)它不需要确定K值。但是需要设置一个簇的阈值。
在确定阈值时,需要谨慎。
28 期望最大法
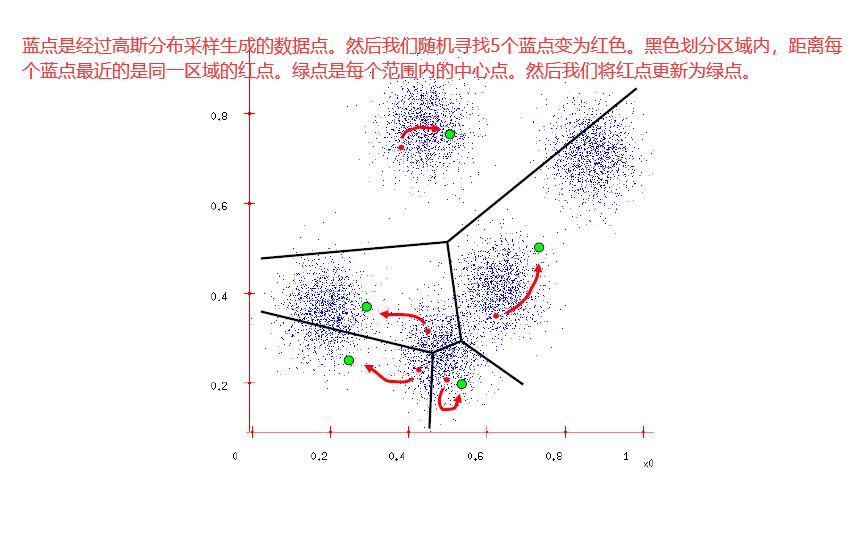
上文中提到的聚类,都是分割类型的聚类,也就是对数据集进行一次划分。而基于模型的聚类的目的并不是对数据分类,而是使用模型对样本进行逼近,得到样本数据的概率密度分布,从而能够生成和样本数据分布类似的数据集。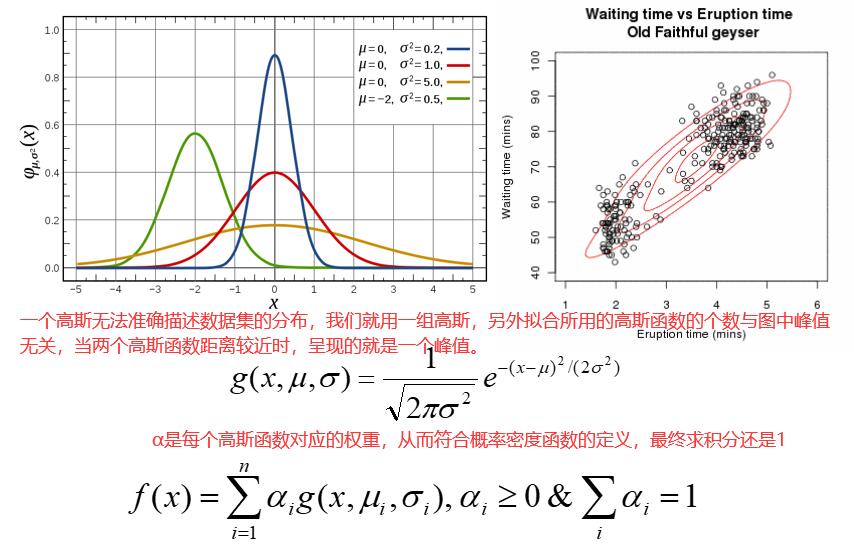
对于K-means来说,我们希望返回的结果是每个簇的均值。
28.1 期望最大化算法 EM
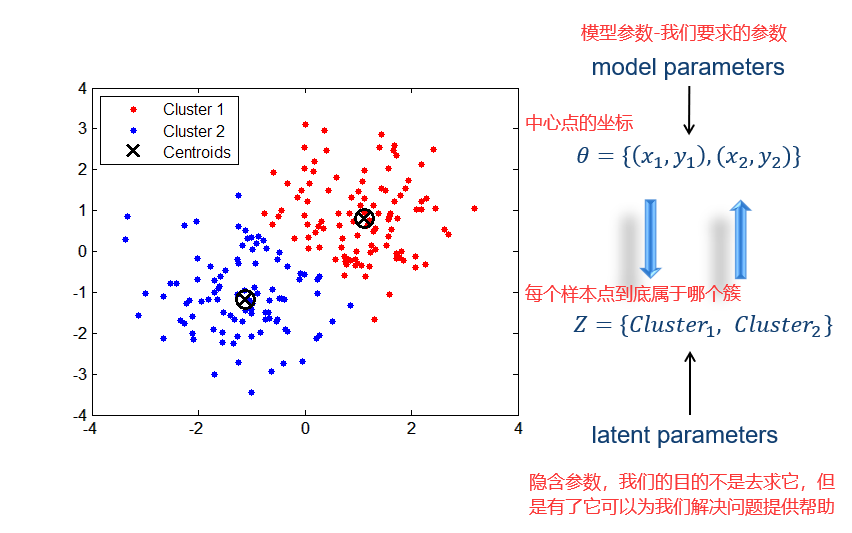
θ和Z这两个参数我们都不知道,但是假设我们知道了θ,那么我们就能求出Z,然后我们对Z内的样本点求平均,就可以得到θ,这就是K-means的思想。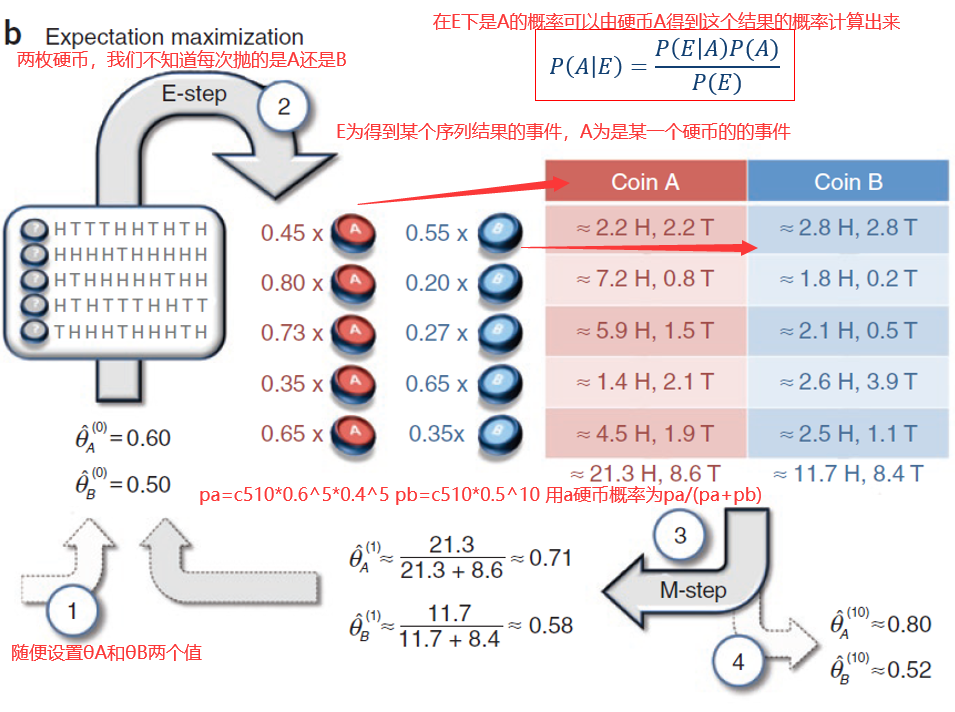
在EM算法中,我们开始并不知道θ,但是我们随机生成了θ,并带入到已有的样本中,根据计算得到的结果,不断修正θ值,最终当算法收敛时,就可以求出真正的θ了。但是初始值如果差距过大,类似与K-means算法,就会收敛到局部最优解,而不是全局最优。
把EM算法应用在高斯上:假设为一维高斯,而且方差是固定的,只有两种参数需要计算,一个是均值μ,一个是每个高斯函数对应的权重α。
29 密度与层次
聚类算法中有两点比较重要,一是它能不能处理非规则形状的簇,二是它能不能处理噪点。为了解决这两个问题,产生了基于密度的聚类方法。它是一种可以生成任意形状的簇的聚类方法。同时抗噪能力较强。且不需要预先设置k值。有点类似于人类的视觉。
29.1 DBSCAN
它是一种允许样本存在噪声的基于密度的空间聚类。
密度:指定半径内的点数。
核心点:高密度点。
边界点:密度低但在核心点附近的点。
噪声点:既不是核心点也不是边界点。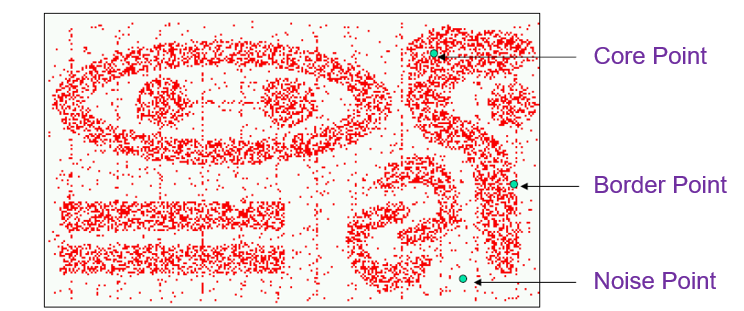
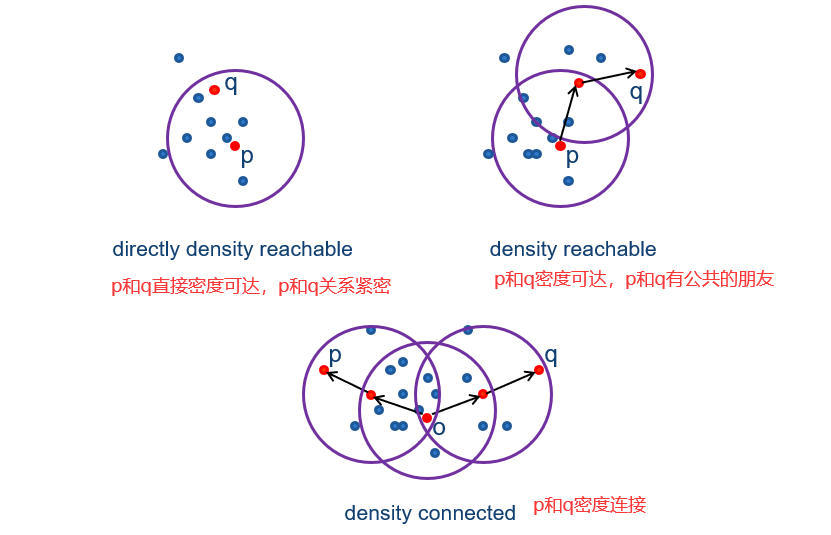
DBSCAN定义:
1)簇被定义为密度连接点的最大集合。每个核心点递归的进行膨胀。
2)从一个随机选择的未知的点p开始。
3)如果p是核心点,则通过将所有密度可达的点逐渐添加到当前点集的操作来构建集群。
4)噪声点被丢弃。
29.2 层次聚类
层次聚类生成一组嵌套的树状簇。
层次聚类可以可视化为树状图。
1)层次聚类可以把样本数据聚成1-n类(n是样本数据个数),我们可以从需要的簇的个数处对聚类结果进行切割。
2)无需提前指定k。
3)可以对应于一些有意义的分发,例如生物中的界门纲目科属种。
实现层次聚类有很多方法,下文介绍的是聚合型的层次聚类。也就是自下(叶子)而上(根)的方法。
然后在最底层,每个样本点是一个簇。
然后我们算出所有两两簇之间的距离,以距离矩阵的形式存储结果。然后从中间选择出距离最小的两个簇,把它们合并,直到只有一个簇。
计算簇之间距离的方法:
1)Single Link(单链路):点与点的最小距离。
2)Complete Link(完整链路):点与点之间的最大距离。
30 支持度与置信度
关联规则主要内容:
1)频繁集。(例如高数和高数辅导书经常被同时购买)
2)关联规则。(购买面包的客户,一般都会购买牛奶)
3)顺序模式(Sequential Patterns)
30.1 Market-Based Problems
在交易记录数据库中寻找商品之间的关联。
item(物品):牛奶,面包,巧克力,黄油……
transaction(交易):所有物品的非空子集。即一组商品的集合。
交叉销售:向现有客户销售额外的产品或服务。向上销售,如给目标为10w商品的客户销售15w的商品。
捆绑销售:同时购买某两件商品就享受85折。
商场布局设计:牙膏牙刷的位置设计。
可以将baskets&item问题抽象到文本处理问题中,basket→sentence,items→words。
数据库D是一组交易的记录。I为所有商品的集合。
关联规则的定义为:
itemset:商品的集合,项集。k-itemset,有k件商品的集合。
31 支持度与置信度
31.1 项集的支持度 Support of an Itemset
一个项集的支持度就是项集在交易记录中出现的频率。如果这个项集的比例太低,那么我们研究这个项集的意义就不大。通常来说当项集越来越大时,它的支持度会逐渐变小(单调不增,买了牛奶的人是0.25,那么买了牛奶面包的人绝对不会大于0.25)。
31.2 关联规则的支持度&置信度 support&confidence of Association rule
类似于项集的概念。如x→y这条关联规则的支持度,就是同时购买x和y商品的频率。
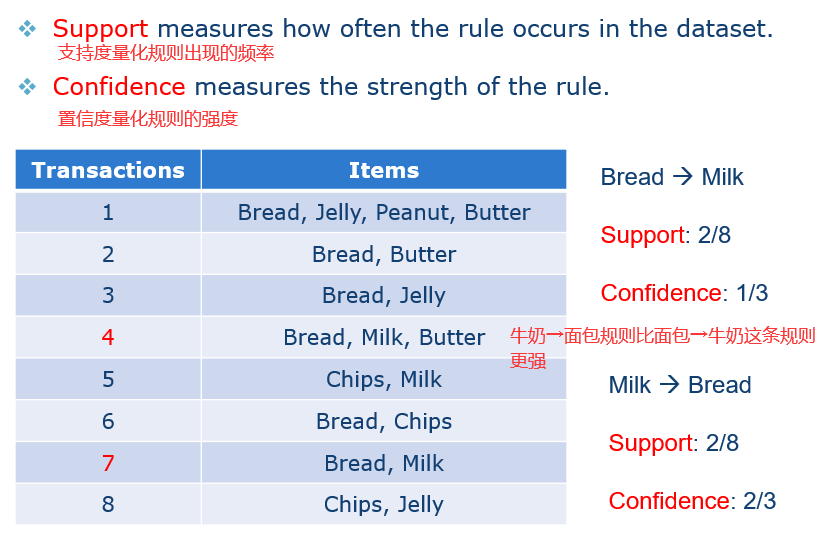
31.3 频繁项集和强规则
我们需要一条规则,它既要频繁,又要强。支持度和置信度受到阈值的限制:
1)最小支持度σ。
2)最小置信度φ。
一个频繁项集是支持度大于σ的项集。
一个强规则是频繁的且置信度高于φ的规则。
关联规则问题:给定I,D,σ和φ,找到x→y形式的所有强规则。
所有可能的关联规则的数量是巨大的:
1)蛮力策略是不可行的。
2)一个聪明的办法是首先找到频繁项集。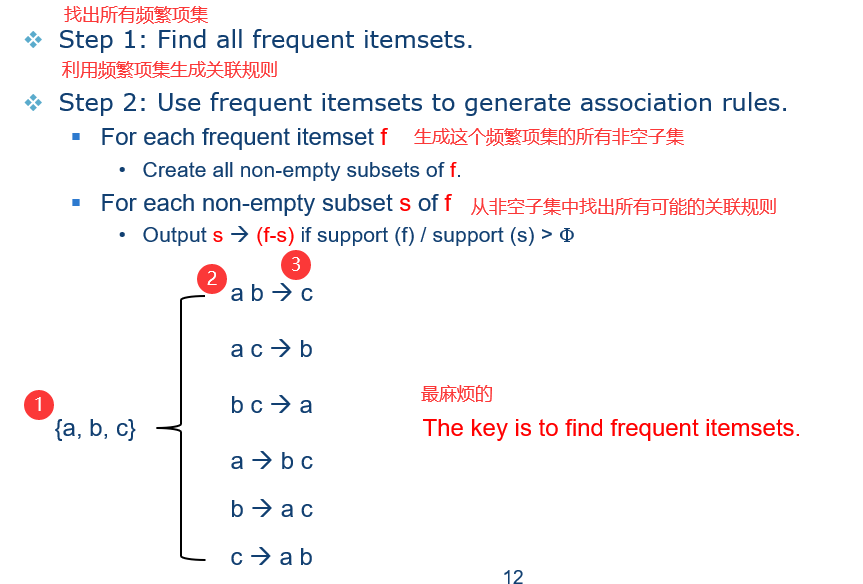
32 误区


两个事务相关并不代表这两个事务之间有因果关系,如冰淇凌销量和犯罪率。关联规则P(Y|X)仅仅是条件概率。
33 Apriori算法
33.1 项目集生成 Itemset Generation
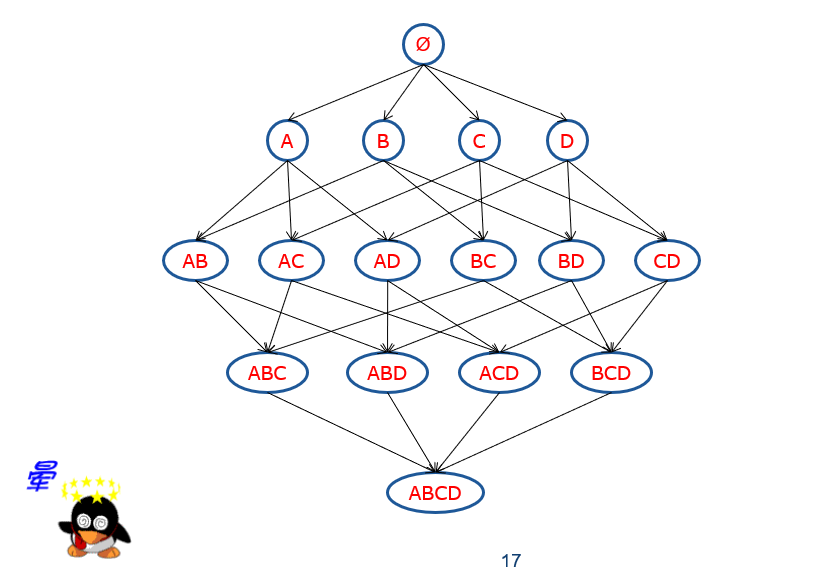
即使只有四个元素的关联规则也十分复杂,根本无法使用传统的蛮力求解。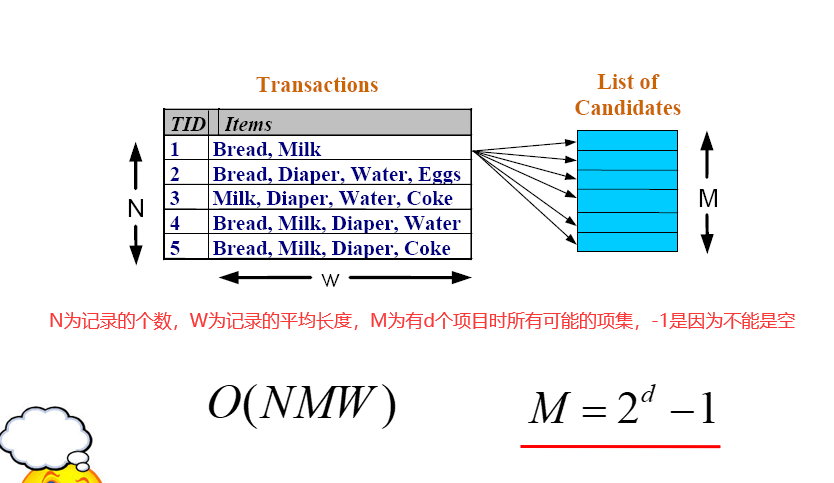
主要思想:
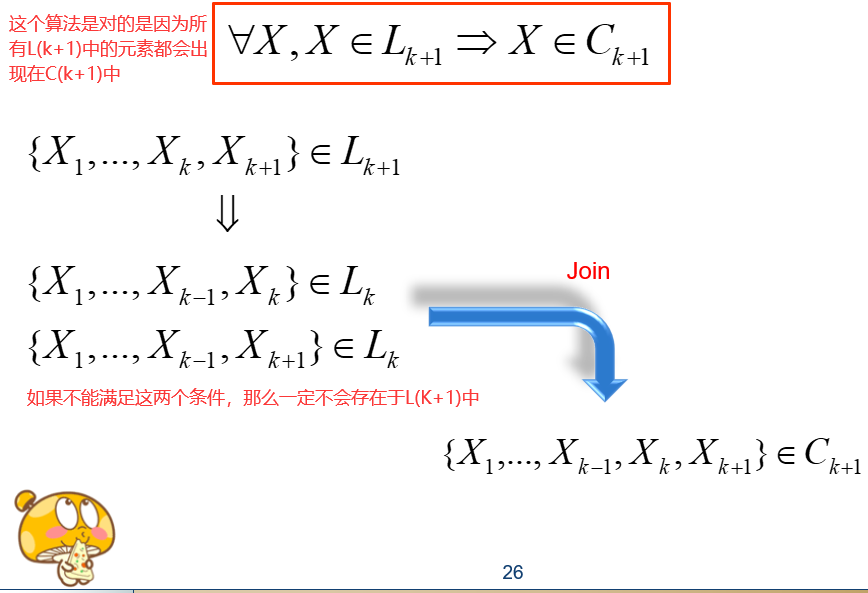
1)任何一个频繁项它的所有非空子集都是频繁的。也就是说,如果{牛奶,面包,可乐}是频繁项,那么”牛奶”也是频繁项,其他的任意一个非空子集都是频繁项,如果有一个子集不频繁,那么这个项集就不可能频繁。
2)任何一个非平凡项的非空超集(有它构成的项集),一定是不频繁的。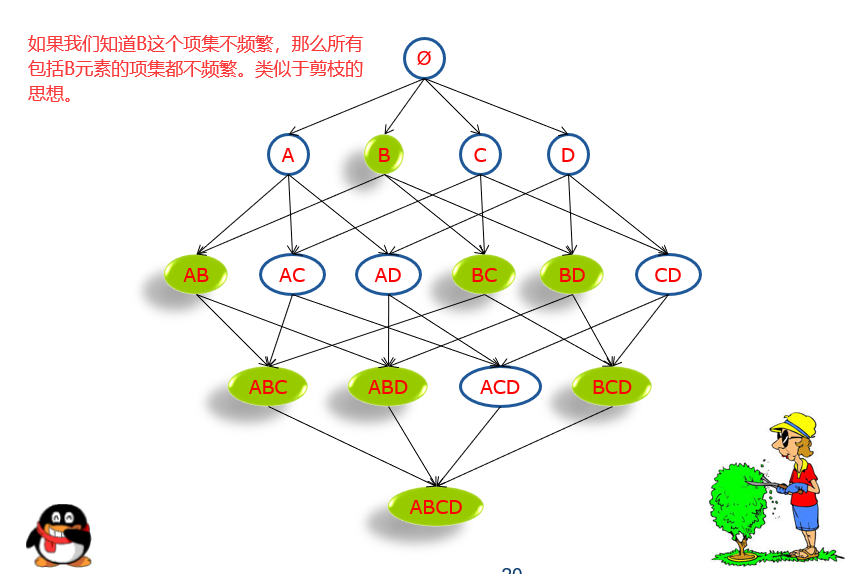
33.2 算法过程
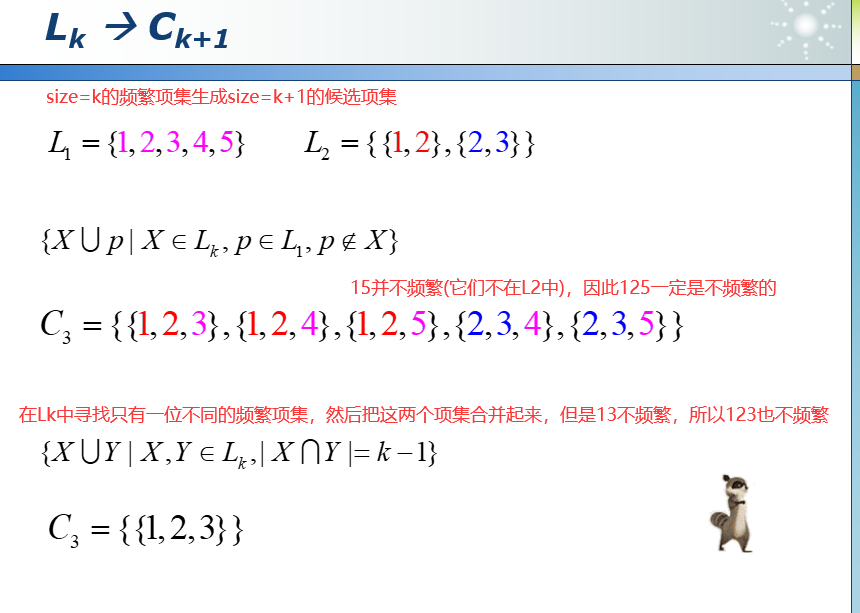
1)生成特定大小的项集,一般大小为(size = 1)。
2)扫描一次数据库,得到上述项集中的频繁集。
3)使用频繁项集生成size=size+1的候选项集。
4)迭代地找到大小从1到k的项集。
5)避免生成一些不可能频繁的候选项集。(如从来没有出现的项集)
6)需要对数据库进行多次扫描。
7)哈希函数和位图等高效索引技术可能会有所帮助。
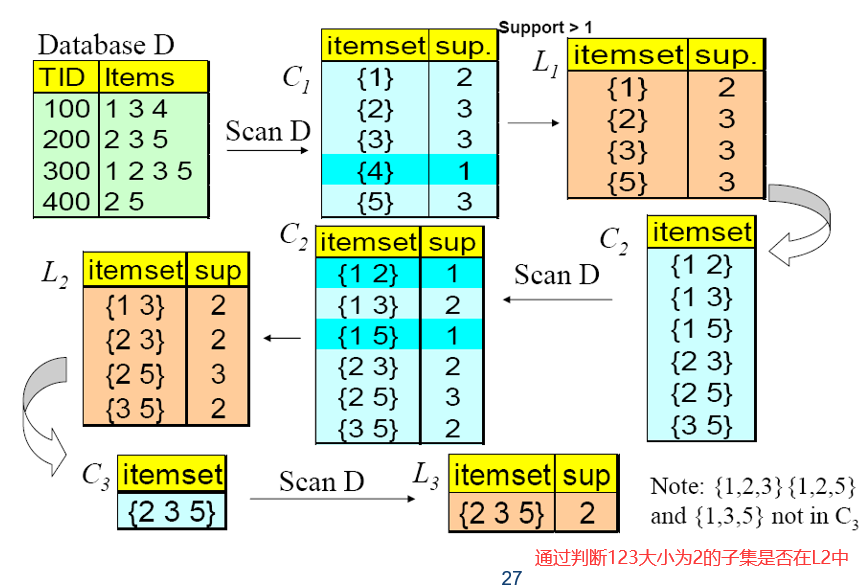
34 实例分析


35 序列模式
主要集中在序列模式与传统关联规则之间的不同点。
35.1 序列 sequence
序列是元素的有序列表,其中每个元素是一个或多个项目的集合。
子序列:t是s的一个子序列,那么我们能够在s中找到一组下标(1≤j1<j2<…<jm≤n),使得相应的t的元素都包含在相应的s元素中。t中元素在s中出现的次序是不能改变的,但是是可以有间隔的。
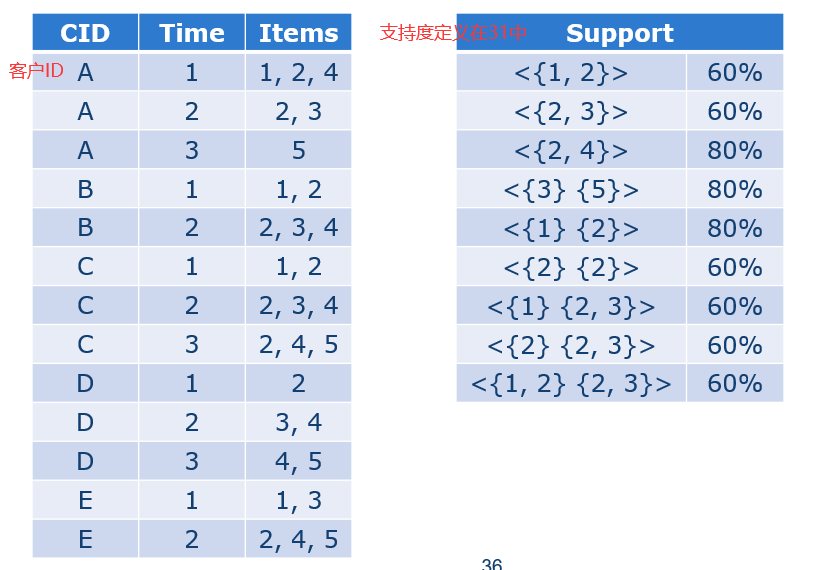
序列的搜索空间要比之前的项集的搜索空间大。
35.2 备选序列生成 Candidate Generation
备选序列生成的方式与Apriori算法生成过程类似(见34)。当且仅当通过删除S1中的第一项获得的子序列与通过删除S2中的最后一项获得的子序列相同时,序列S1与另一个序列S2合并。(把S2的尾部放到S1的尾部即可)
36 无所不在的推荐
推荐算法:
1)TF-IDF。
2)Vector Space Model,向量空间模型。
3)Latent Semantic Analysis,隐含语义分析。
4)PageRank,页面排序
5)Collaborative Filtering,协同过滤,推荐算法中最为流行的一种。
信息过载 data overload。
36.1 推荐系统 Recommendation Systems
一个可以预测用户对某个项目评分或是偏好的系统。
1)帮助人们发现他们没有想到要搜索的有趣或信息丰富的数据。
2)是数据挖掘最有影响力的应用之一。
基于内容的过滤:
1)侧重于物品的特性。比如书的作者,类型。
2)推荐与用户过去喜欢的项目类似的项目。
协同过滤:
1)根据用户与其他用户的相似性预测用户会喜欢什么。
2)类似于询问朋友的意见。
3)不依赖机器可分析的内容。
37 隐含语义分析
37.1 TF-IDF
给定一组文档和一个查询词,文档和该词的相关性如何?
有些词比其他词出现得更加频繁。
Term Frequency(TF)词频:
1)原始频率定义,实际使用中稍有变化。
2)定义式如下:
Inverse Document Frequency(IDF)逆向文本频率
分子是所有文档的个数,分母是包含这个搜索词的文档的个数。
一个搜索词,在本文档中出现的次数,要越频繁越好,同时这个搜索词在其他文档中要尽可能少的出现,这样才有指向性。
37.2 向量空间模型 vector space model
vector space model是将文本文档表示为向量的代数模型。例如,我们定义100个关键词,那么一篇文档就会变成100维的向量,这个向量的第i位表示第i个关键词在本文档中有(1)没有(0)出现。或者也可以把第i个关键词出现的次数记录在向量第i位中。或者可以采用tf-idf值。大致思路就是把一篇文档变成一个向量。
文本处理的问题:
1)近义词。不同的词,相同的意思。car,vehicle,automobile……,可能会出现小余弦值→不相关。这可能会导致低召回率。(召回率即在所有应该为positive的数据中,判断为positive的比例。例如在搜索引擎上搜索文章,我需要的100篇文章中被顺利找到的文章有多少。见上文8)
2)多义词。一个词,不同的意思。apple computer vs. apple juice,他们可能会出现大余弦值→相关。这可能会导致低精度。(准确率即在所有判断为positive的数据中,确实是positive的比例。例如在搜索引擎上搜索文章,返回的结果中有多少是我真正需要的。见上文8)
为了解决这些问题,我们使用了奇异值分解(矩阵分解方法,Singular Value Decomposition),类似于PCA方法(主成分分析,见上文11),把维度进行一个压缩(合并具有相似含义的维度),把信息进行一个浓缩,同时去掉冗余信息和噪点信息。在新的空间中的判断会更加精准。
37.3 隐含语义分析 Latent Semantic Analysis

TS就相当于把原来一个单词对应一个index换成了一个单词对应一组向量。在X中第i个单词对应TS中第i行向量。文档同理。

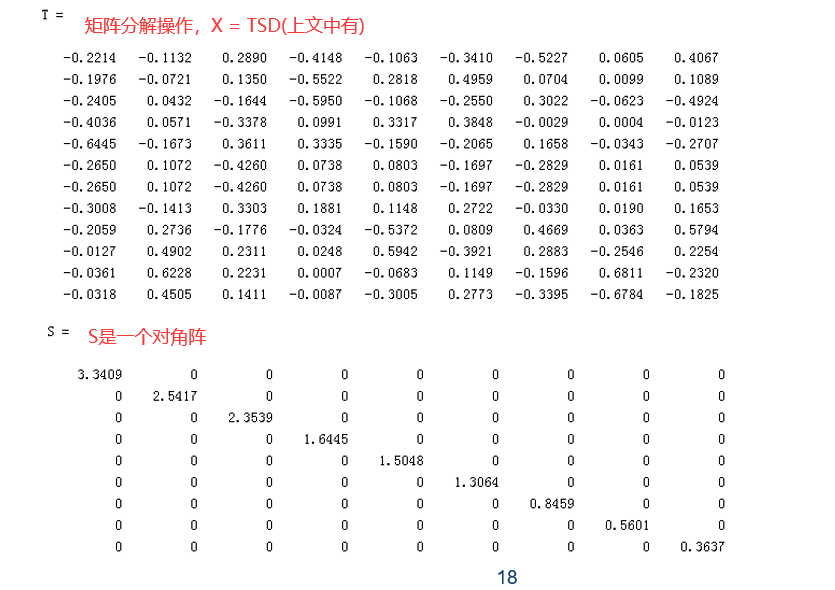

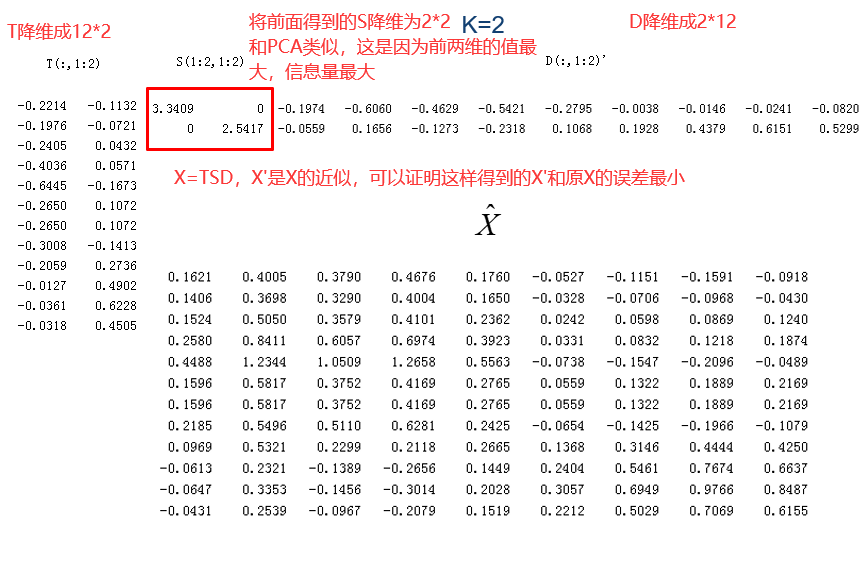
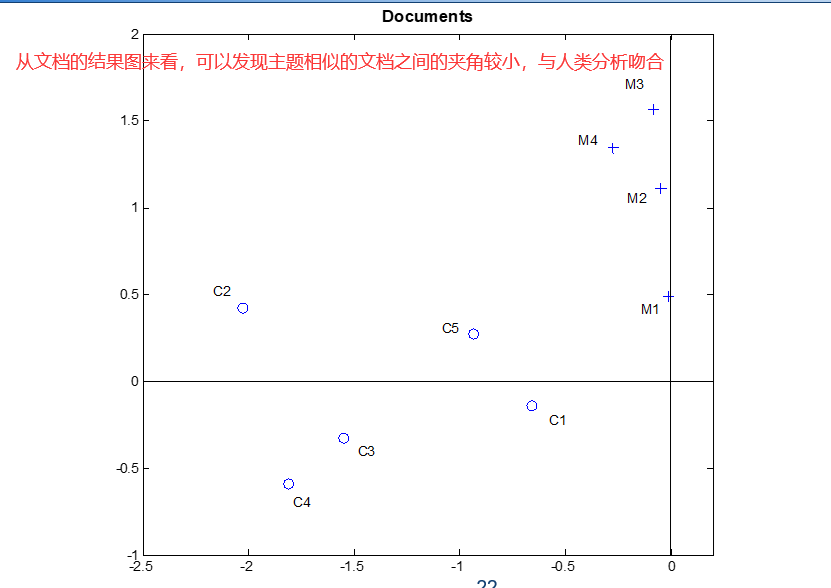
图中D的每一列表示一个文档,可以通过余弦值计算他们之间的相似度。图中T的每一行表示一个单词,可以通过余弦值计算他们之间的相似度。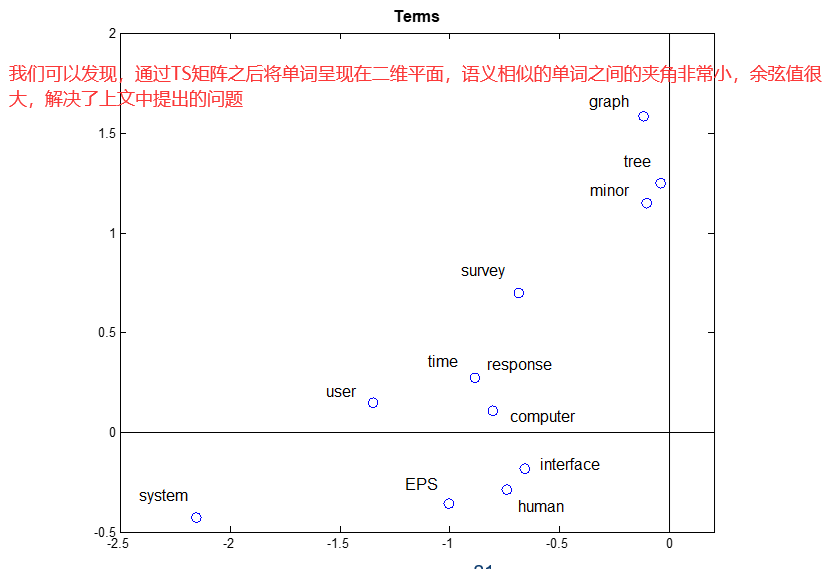

38 PageRank传奇
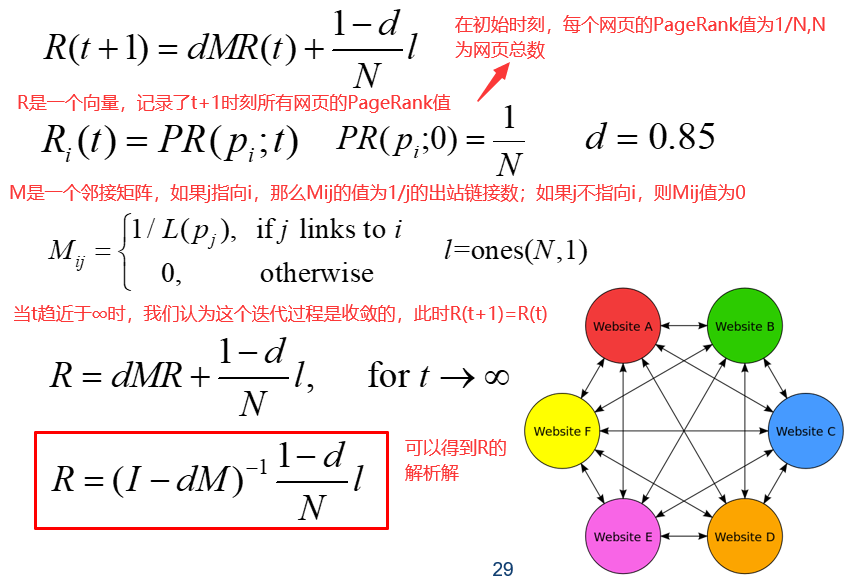
给定一组超链接文档,如何评估每个文档的相对重要性?
指向页面的超链接算作支持。一个页面的重要性取决于指向它的网页自己的PageRank和指向它的网页的出站链接的数量。比如一个德高望重的人(PageRank很高),而且他给别人写的推荐信很少,那么这个被推荐的人含金量就会高。
页面的PageRank由链接到他的所有页面的数量和连接到他的所有网页的PageRank指标决定。不适用本页面的出站链接数作为指标是因为为了提高网页的PageRank,这个指标是很容易被伪造的,我可以很容易的从10个变到100个,这个指标是不可靠的,因此页面的出站链接并不会影响其PageRank值。(和论文引用类似)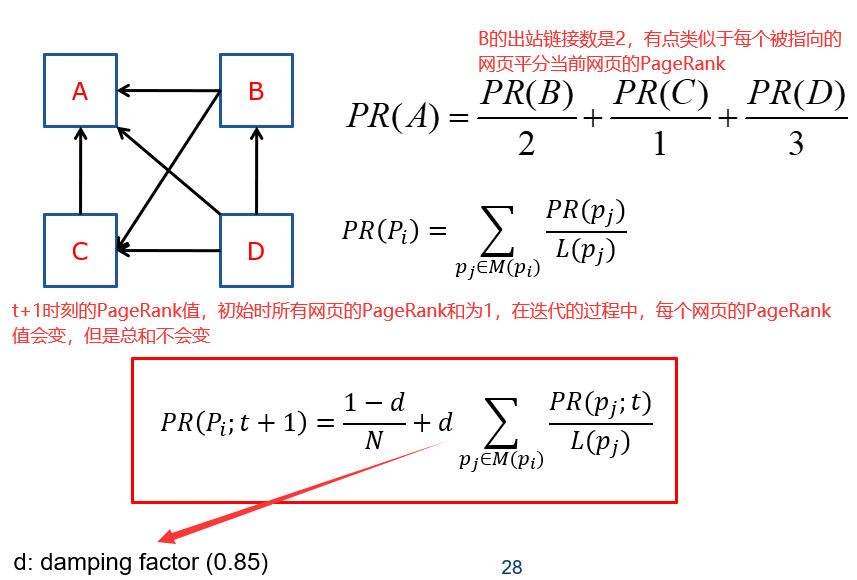
39 协同过滤
核心理念:
协同过滤的”协同”是指寻找和用户品味相近的用户来得到问题的答案。人们总是从其他口味类似的人那里得到最好的推荐。
工作流程:
1)它的基本思想是首先确定一个打分矩阵,每一行代表了一个用户,每一列代表了一个商品,矩阵(i,j)位置的元素就是第i个用户对第j件商品的打分。
2)通过匹配他们的评分来找到类似的人。
3)推荐类似的人高度评价的项目。
分类:
1)Memory-Based Collaborative Filtering(基于记忆的协同过滤)分为User-Based(基于用户的)和Item-Based(基于项目的)。
2)Model-Based Collaborative Filtering(基于模型的协同过滤)
问题:
1)对于一些特立独行的人,我们很难通过协同过滤来得到问题的答案,我们可能会找不到品味相同的用户。
2)打分矩阵中的数据并不是完全真实的。可能会有水军刷评论等等。
3)冷启动。新用户无法准确推荐。
39.1 基于用户的协同过滤 User-Based CF

引入平均分的概念是为了考虑每个人打分的尺度,比如有的人打分普遍高,而有的人打分普遍低。要考虑到每个人打分尺度的不同。
下图为计算实例:
39.2 基于项目的协同过滤 Item-Based CF
在基于用户的协同过滤中寻找的是打分表行与行之间的关系。在基于商品的协同过滤中,我们寻找的是列与列之间的关系。例如,可以通过相关度分析得到喜欢蝙蝠侠和喜欢蜘蛛侠之间有没有关系,然后利用用户对蝙蝠侠的打分去预测用户对蜘蛛侠的打分。


39.3 基于模型的协同过滤 Model-Based CF
把协同过滤问题转化为机器学期中的分类问题。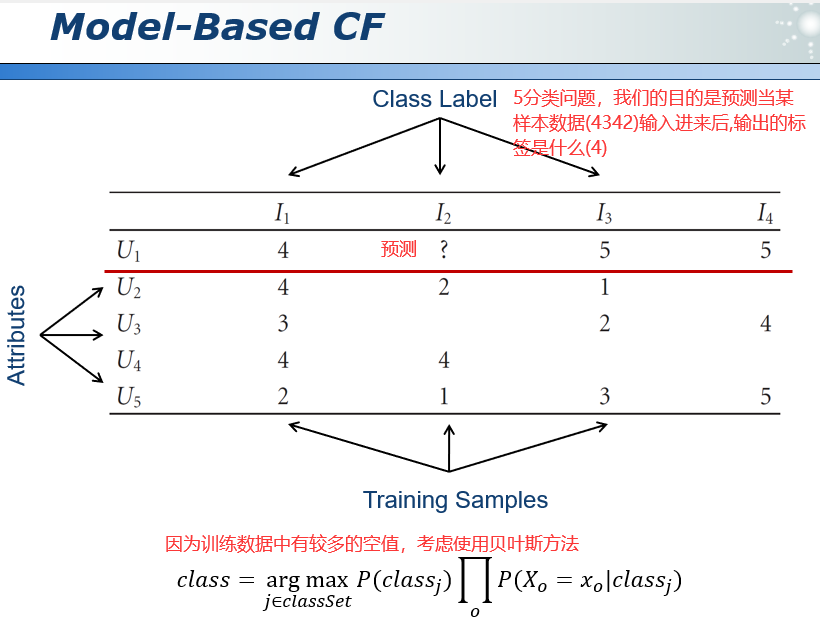
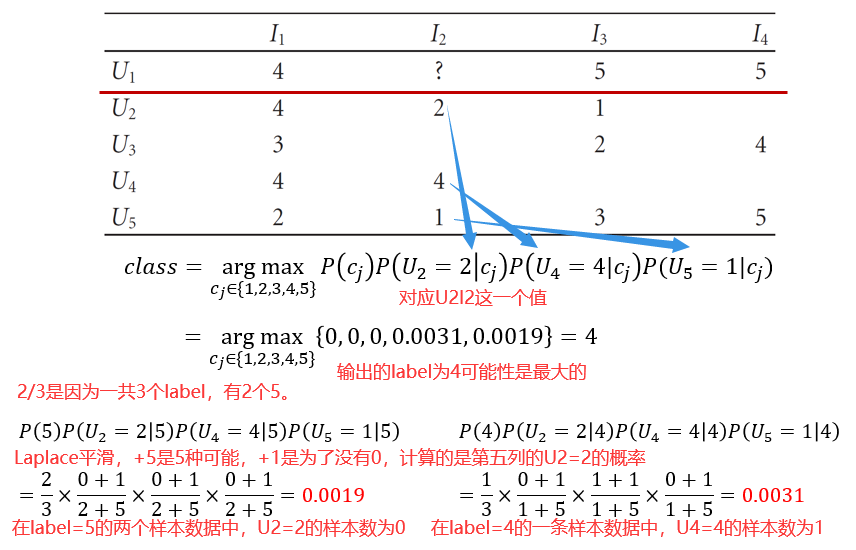
针对p(cj)则没有使用拉普拉斯平滑,所以cj=1,2,3时概率都是零。简单来说就是对每个得分计算后验概率,完了后验概率最高的得分就是U1I2的值。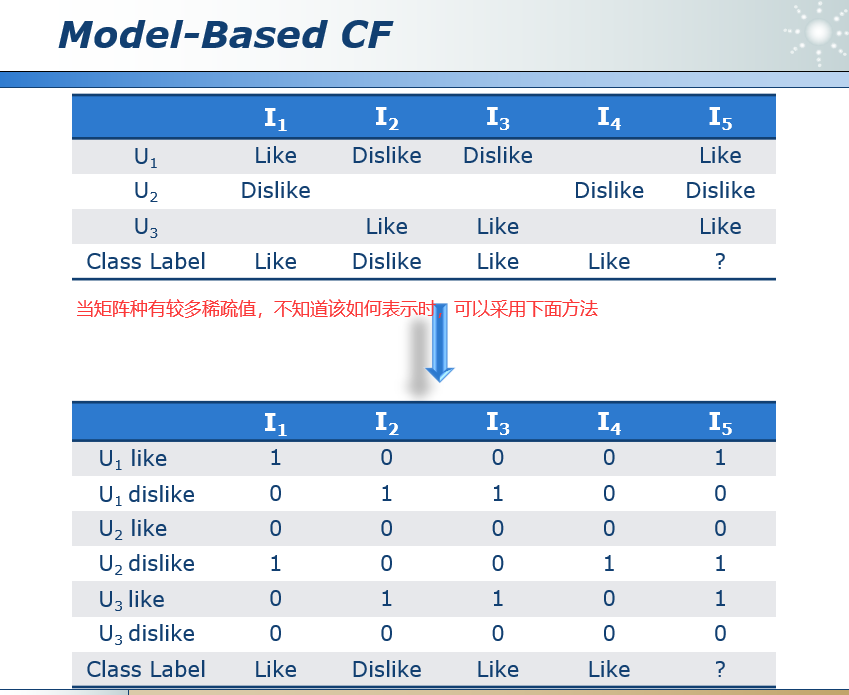
40 告诉你一个真实的推荐
40.1 Netflix Prize
一家提供DVD出租服务的上市公司提供。主要功能是根据人们喜欢或不喜欢其他电影的程度来预测某人是否会喜欢一部电影。将自己的Cinematch评分提高10%。
40.2 Reality Mining
通过一些数据信息挖掘出人与人之间的关系。
40.3 关于推荐的思考
1)现在我们仅仅根据购买记录对客户进行分析。其实我们可以添加更多的维度,思考一下我们平时如何向朋友推荐一些东西……
2)人们有不同的个性。所以我们需要不同的策略。如推销保险时,是感性一点的策略还是成熟的策略。
3)人们出于不同的原因购买东西。冲动购买和计划购买。同时人在不同时期,需要购买的东西是不同的,是逐渐改变的。
41 民主协商:Ensemble
集成学习不是一个特定的算法,是一个大的算法框架。
What is ensemble learning?(什么是集成学习?)
许多单独的学习算法可用:决策树、神经网络、支持向量机。
策略性地生成和组合多个模型以更好地解决特定机器学习问题的过程。例如我们学过很多的分类器,每个分类器各有各的优点,集成学习就是先针对问题生成一些分类器,然后再把他们组合到一起。
motivations(动机)
1)提高单个模型的性能。单个模型的性能可能不够。
2)减少不幸选择不良模型的可能性。有效解决模型选择问题。
集成学习也叫多分类器系统。
一个想法,许多实现(主要包括)
1)Bagging
2)Boosting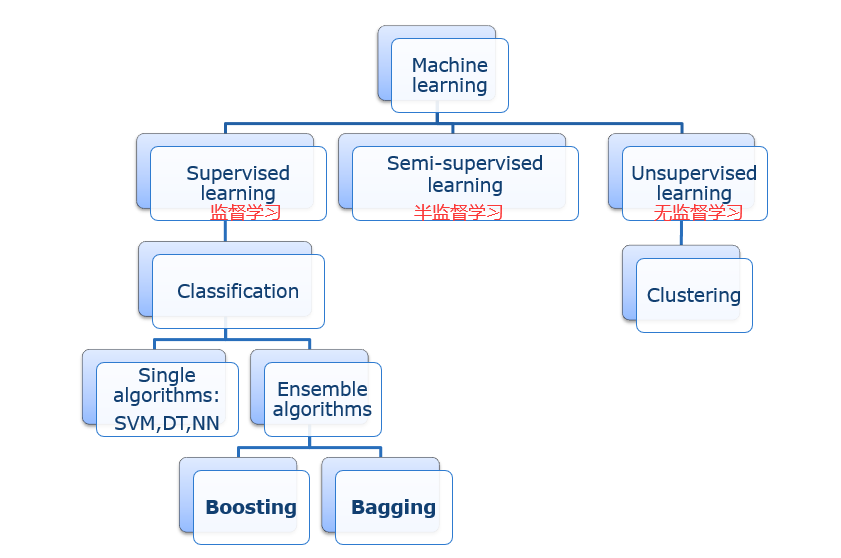
41.1 模型选择 model selection
我们每次选择70%的数据训练模型,因为每次用于训练模型的数据不同,所以训练出的模型也不同,如何在这些模型中做出选择呢?
我们可以三个模型都采用,对每个模型去一个平均,得到一个更为准确的分界面。这就是集成学习。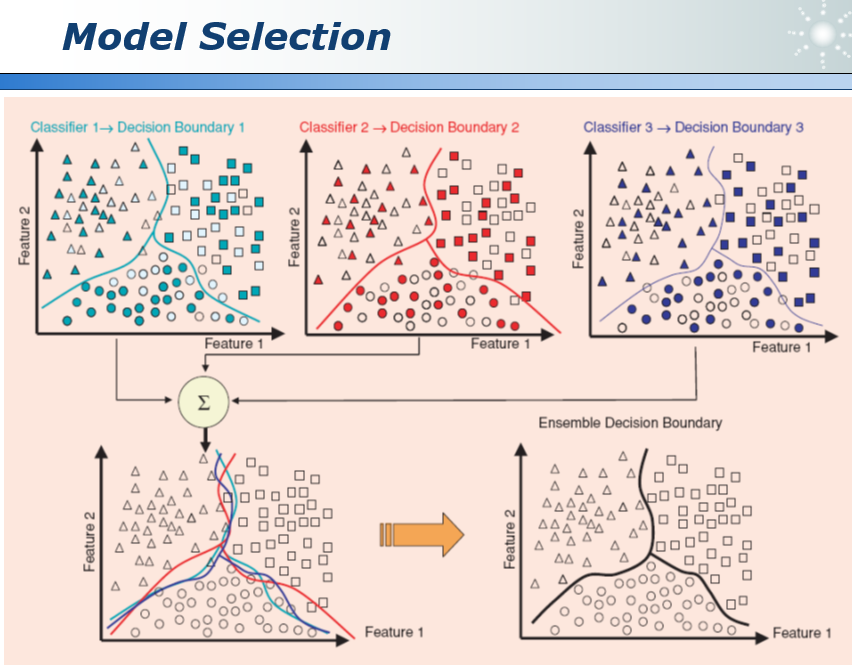
42 群策群议:Bagging
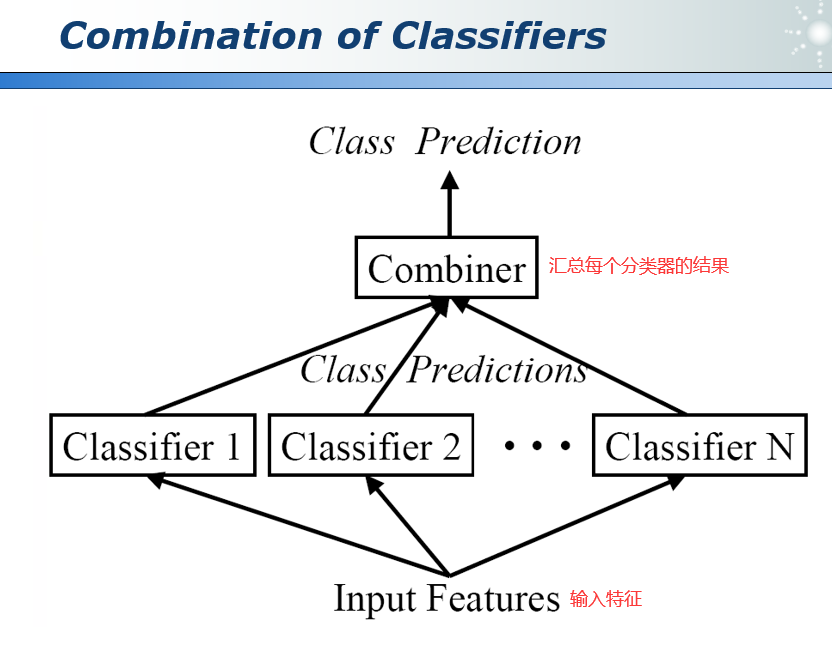
42.1 模型组合 Combiners
如何组合各分类器的输出?
1)平均。
2)投票表决:多数投票(随机森林,Random Forest);加权多数投票(AdaBoost),每个分类器的输出有对应的权重,权重越大证明分类器越重要。
3)学习组合器:通用组合器(堆叠,Stacking);分段组合器(区域提升,RegionBoost)。
42.2 模型多样性 Diversity
集成学习成功的关键是模型的多样性:
1)需要纠正其他分类器犯的错误。
2)如果所有模型都是相同的,则算法不起作用。
不同的学习算法有:DT,SVM,NN,KNN……
但是在平时使用过程中,我们还是更倾向于使用相同的学习算法,因此可以考虑使用不同的训练过程:
1)不同的参数。
2)不同的训练集。
3)不同的功能集。
我们不需要太强的分类器,因为可能会有计算复杂度高或是过拟合等问题。弱学习者:
1)轻松创建不同的决策边界。
2)如只有一个根节点的决策树。
42.3 生成样本 BootStrap Samples
BootStrap是统计学上的一个采样方法,本质上是一个有放回的采样。如下图中对5个样本进行BootStrap采样的结果。有的小球出现了多次,而有的小球一次都没有出现,然后用这些结果就可以训练生成不太一样的分类器。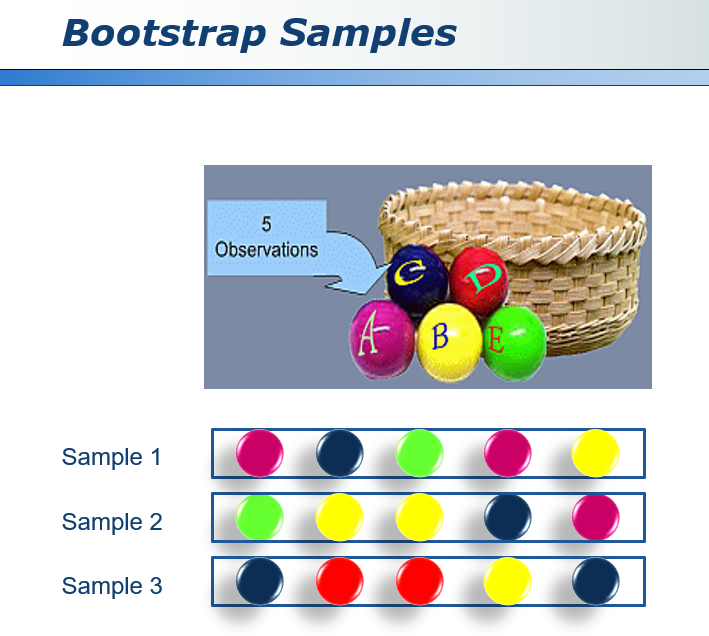
42.4 Bagging(BootStrap Aggregating)
1)使用前文中的BootStrap方法生成50个样本数据,训练出50个(经过独立训练的)分类器。
2)对于一个样本的最终分类结果,由50个分类器的输出进行投票,少数服从多数原则。
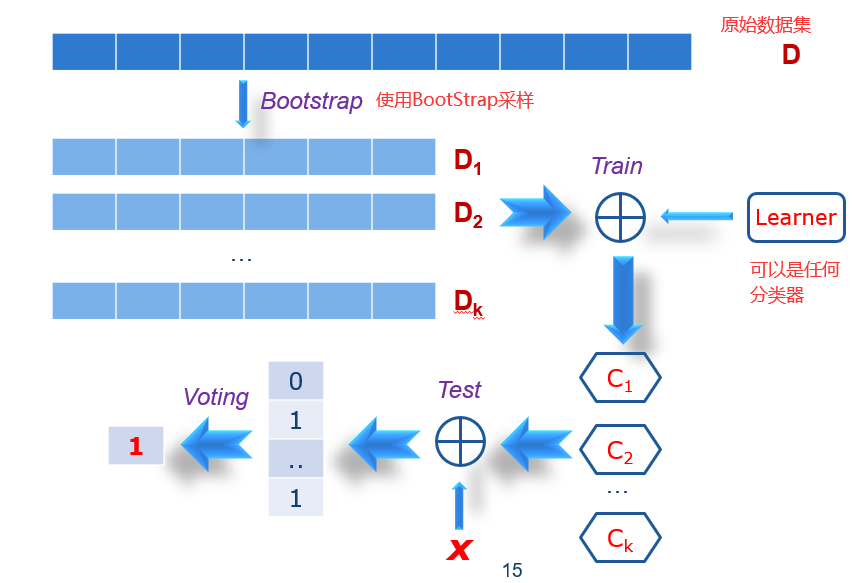
42.5 随机森林 Random Forests
把长得不一样的决策树混合在一起,形成一个好的分类器,这个分类器就叫随机森林。
Bagging(BootStrap Aggregation)
1)有放回的取样。
2)使用大约2/3的原始数据。
1/n就是n个样本中某个样本被选中的概率,1-1/n就是某个样本不被选中的概率,n个样本一个都不被选中的概率是(1-1/n)^n,在取样过程中不能一个样本都不被选中,因此样本被选中的概率为1-(1-1/n)^n,大概是2/3。选中的样本用于训练,没有被选中的样本用于测试。
所以Random Forests算法就是生成很多CART树的集合:
1)二进制分区
2)不修剪。
3)固有随机性。
CART:ID3和C4.5算法,生成的决策树是多叉树,只能处理分类不能处理回归。而CART(classification and regression tree)分类回归树算法,既可用于分类也可用于回归。 分类树的输出是样本的类别, 回归树的输出是一个实数。
最终输出的决策方法:少数服从多数。
RF(Random Forests)的主要特点:
1)使用原始数据的bootstrap采样样本。
2)为每个节点使用决策树所有属性的随机子集。可以进一步增加决策树的多样性。
每棵决策树的属性个数:
1)总属性个数K的平方根。总属性个数K是指可用变量的总数。
2)可以显著加快建树的速度。
生成决策树的个数:500或更多。
模型自我测试:
1)大约1/3的原始数据被遗漏了(Out of Bag,OOB)。
2)类似于交叉验证。我们的测试数据一部分被选中用于模型训练,天然地留下了一部分数据用于模型测试。
RF(Random Forests)的优点:
一、所有的数据都可以在训练过程中使用。
1)无需专门留下一些数据进行测试。
2)无需进行常规的交叉验证——人工划分训练集和测试集。
3)OOB中的数据可以被用于评估当前树。所有数据都可以被充分利用。
二、整个RF模型的表现。
1)每个数据点都在树的子集上进行测试。
2)取决于它是否在OBB中。从原始数据中挑出没有被用于训练当前决策树的数据,用于测试当前决策树。一个数据不可以既训练又测试。
三、高水平的预测准确性。
1)只有一小部分参数需要调试(即使RF中有很多决策树)
2)对于分类和回归都适用。
四、可以防止决策树中会出现的过拟合情况。这是因为我们最终的输出结果不取决于某一棵树,所以即使有过学习的情况(树的高度很大),也不太可能影响整个RF的输出。
五、不需要事先选择属性。对于大部分分类器来说,我们需要进行选择属性的操作,例如在100个属性中选出20个。
43 环环相扣:Boosting
43.1 Stacking(Bagging)
在实际应用中,我们需要在Random Forests的基础上为分类器的输出结果增加了权重,Stacking提供了一种方法来学习这些权重,具体方法是把每一个分类器的输出作为输入,再放入到一个分类器当中,进行训练,学习每个分类器的权重。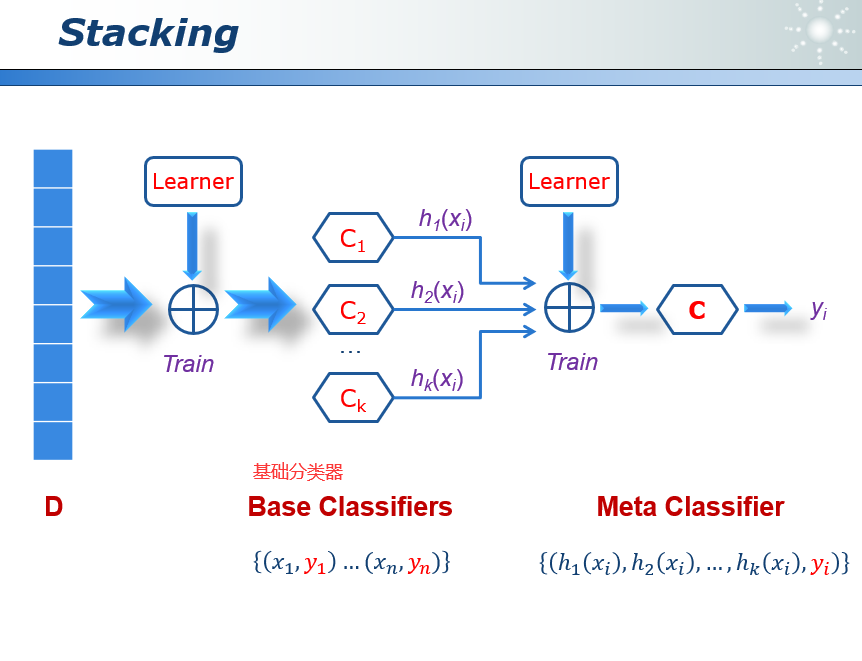

43.2 Boosting
Boosting和Bagging最的区别在于,Bagging中所有的分类器是并行的,是同时去生成,分类器之间并没有什么关系。在Boosting中,我们会先生成一个分类器,然后根据第一个分类器的性能去生成第二个,这样串行地生成。下图解释了Boosting的大致流程(虽然在实际中并不是如此)。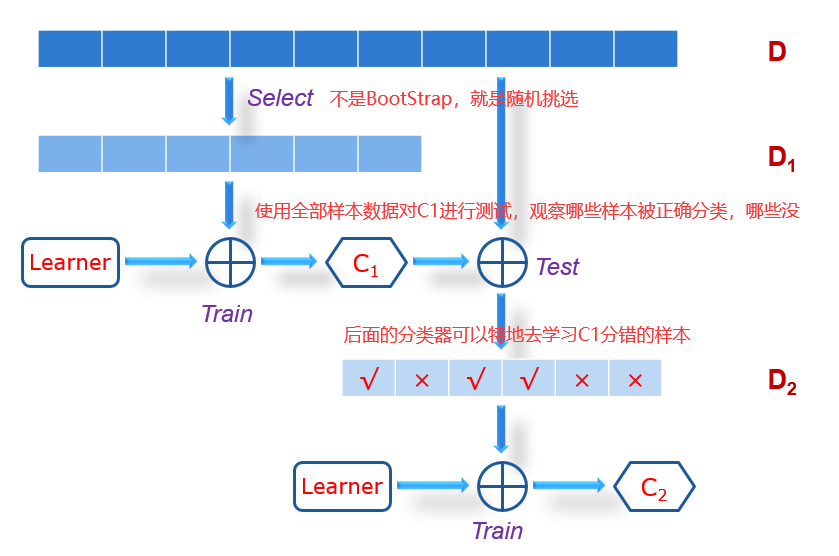
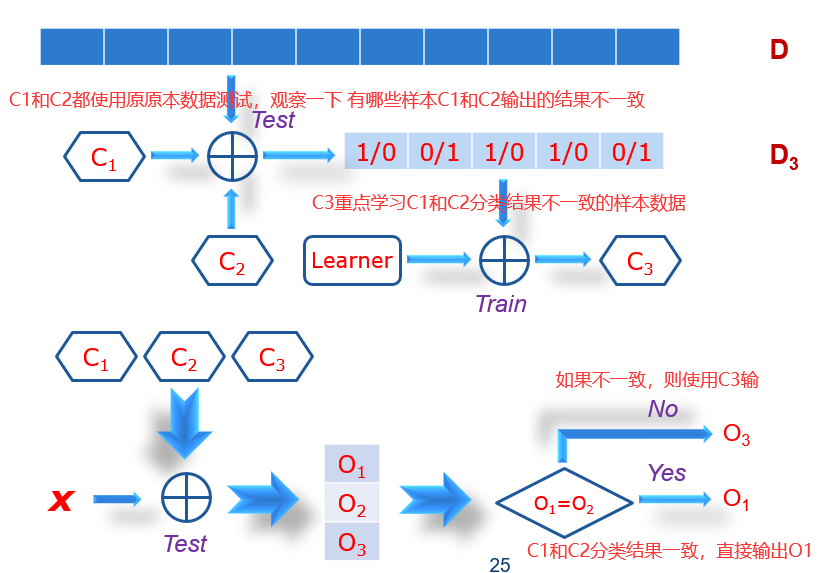
Bagging可能会需要几百个上千个分类器,而Boosting只需要有目的的设置一些,一般不会设置太多。Boosting的特点是根据分类器Ci在数据集上的测试结果,不断调整Ci+1分类器的训练样本。所谓的调整,就是为训练样本加权重。原来是每个样本都有同样的机会去作为训练样本训练分类器,现在每个样本都有不同的权重。使得分类器犯错的次数多的样本,权重就大,这样做的目的是为了让后面的分类器重点去学习前面分类器分错的样本。如果一个样本很简单,几乎没有分类器在它上面犯错,那么它的权重就会降得很低。在权重大的样本上犯错,这个错误就严重;在权重小的样本上犯错,这个错误就不那么重要。
Boosting的特点:
1)Bagging旨在减少方差(Variance),而不是偏差(bias)。Bagging和Boosting是集成学习的代表。Bagging可以降低模型的方差,模型的方差是指当训练集稍微变一变,那么用于训练的样本数据就不同了,就会导致生成的分类器差别(variance)比较大,意味着模型本身受到训练样本的影响会很大。就像上文中41中提到的model selection问题。
2)在Boosting中,分类器按照顺序生成的。
3)专注于信息最丰富的数据点。
4)训练样本是加权的。
5)输出可以通过加权投票进行组合。
6)基础分类器可以很弱。只要他们比随机猜测好。使用Boosting可以创建任意强的分类器。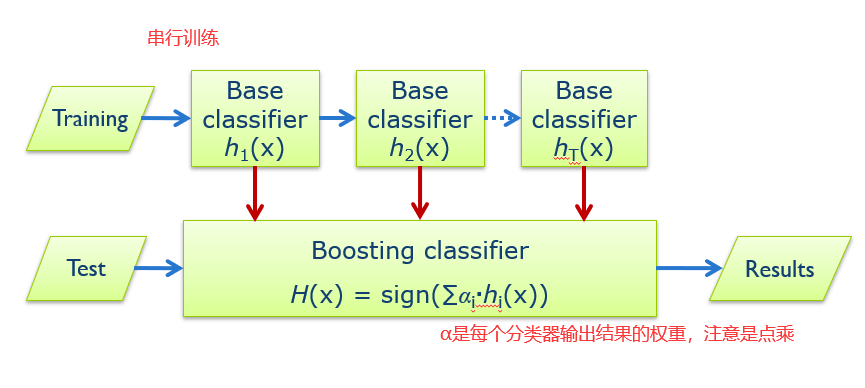
43.3 AdaBoost
AdaBoost是Boosting中最具有代表性的算法,也是数据挖掘十大算法之一。
一个二分类的例子。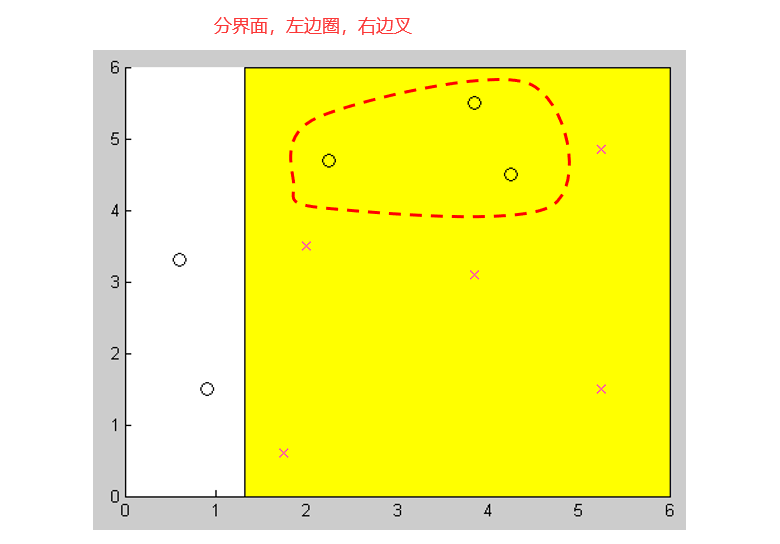
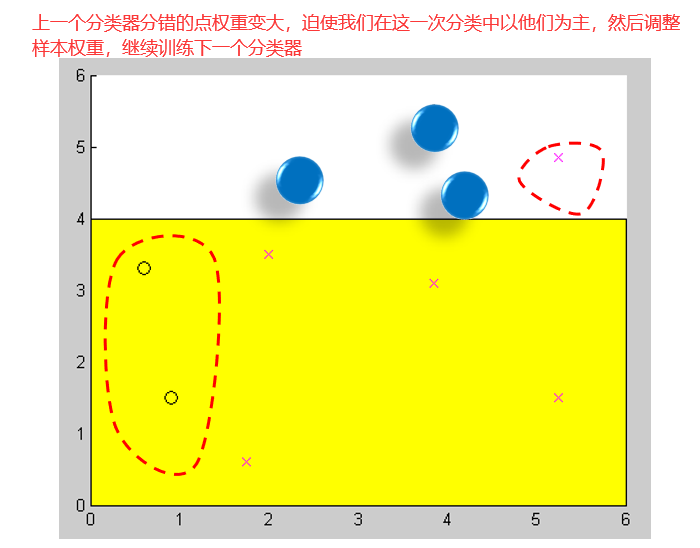
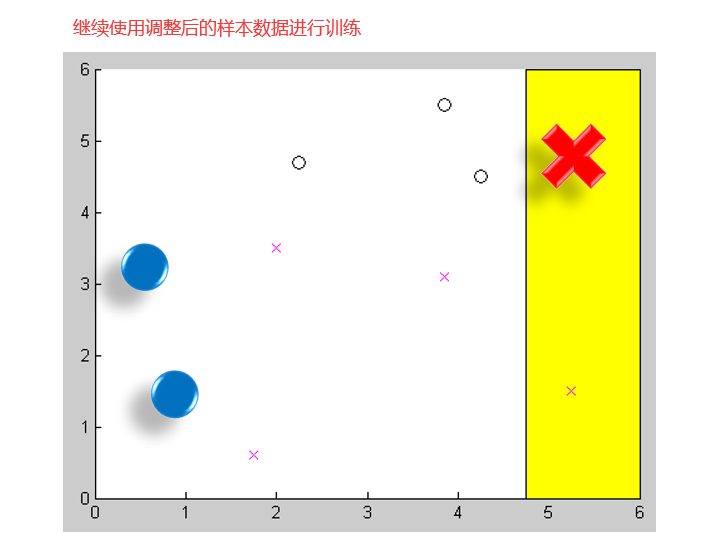
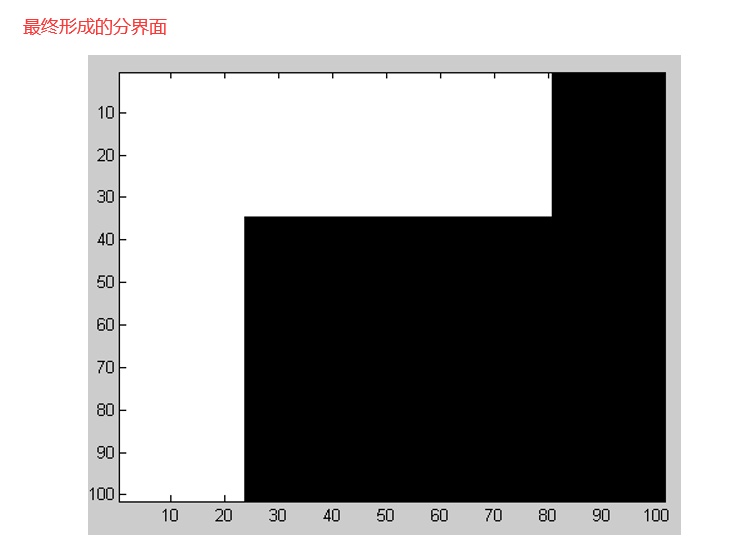
44 集成之美:AdaBoost
Adaboost的训练误差的上界是可以从数学上证明越来越小的,而且它的α是可以推导出来的。

为什么Zt会与误差有关呢?如果在AdaBoost训练过程中,很多样本基本上都被分对,那么这些样本的权重就会越来越小,那么加起来得到的Zt就会较小。反之,如果Zt很大,那就可能是很多分类器都把这个样本分错了,所以权重就会越来越高,所以最小化Zt,实际上就最小化了训练误差。

AdaBoost优点:
1)简单易实现。
2)几乎没有需要调的参数。只需要设定模型需要生成多少个基础分类器,一般50个误差就非常小了。
3)已数学证明的误差上限。
4)对过拟合免疫。
AdaBoost缺点:
1)局部最优的α值。每次最小化当前的Z值。
2)最陡下降,误差下降快。
3)对噪点敏感。
未来的工作:
1)涉及到的相关理论很多。
2)可解释性。很多模型在AdaBoost中,模型的可解释性不好。
3)新框架。
45 继往开来:RegionBoost
在AdaBoost中每个分类器的权重α是确定的。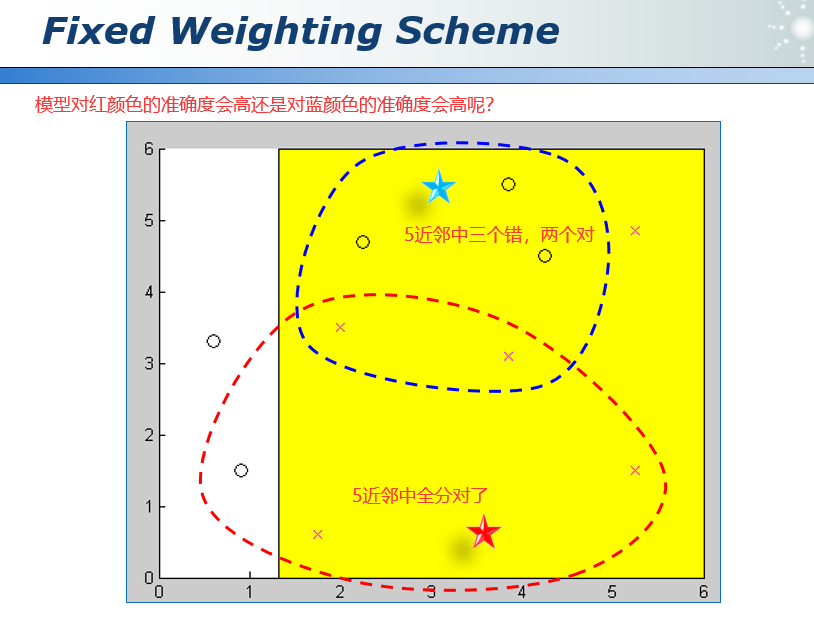
一个模型的权重,其实是和输入是相关的。比如我是一个计算机系的学生,如果问我关于计算机的专业知识,那么我的输出就比较靠谱;但是如果问我一个文学方面的问题,那么我的输出就仅供参考。
45.1 动态加权方案 Dynamic Weighting Scheme
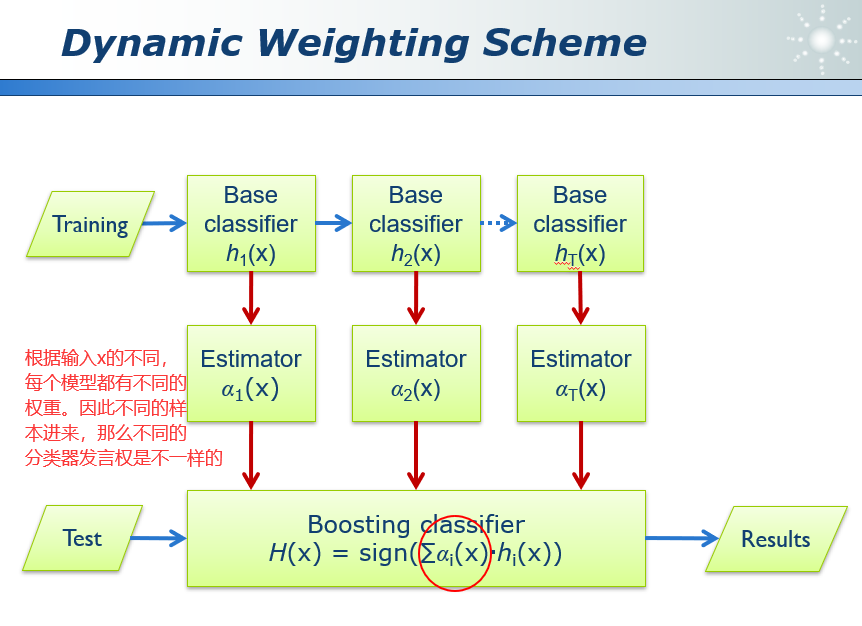
45.2 RegionBoost
AdaBoost为模型分配固定的权重。但是,不同的模型强调不同的领域。RegionBoost模型的权重应该取决于输入。
给定一个输入,我们需要调用恰当的模型。因此,为每个模型训练一个能力预测器。估计模型是否有可能做出正确的决定。将此信息用作权重。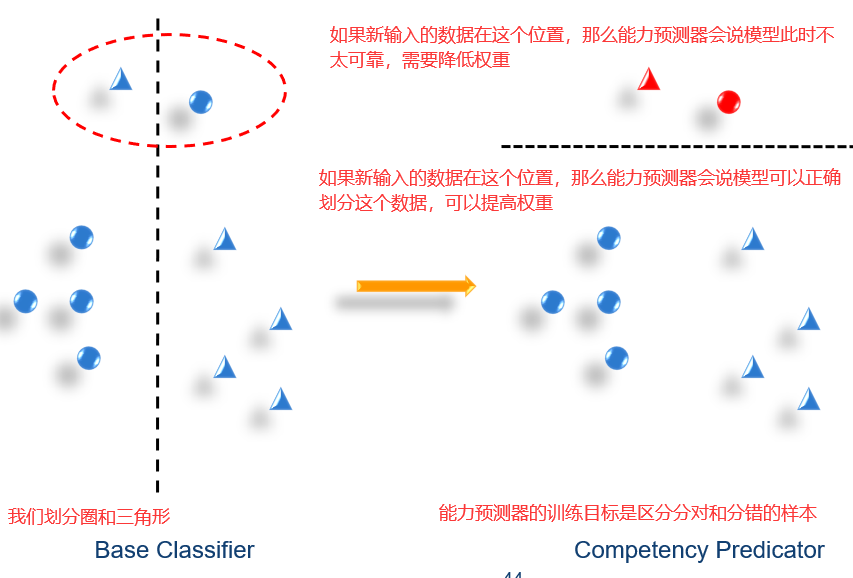
在RegionBoost中计算每个模型的动态权重αj(xi),我们使用knn(k近邻)的思想:
1)在训练集中找到xi的k个最近邻。
2)计算被hj正确分类的点的百分比。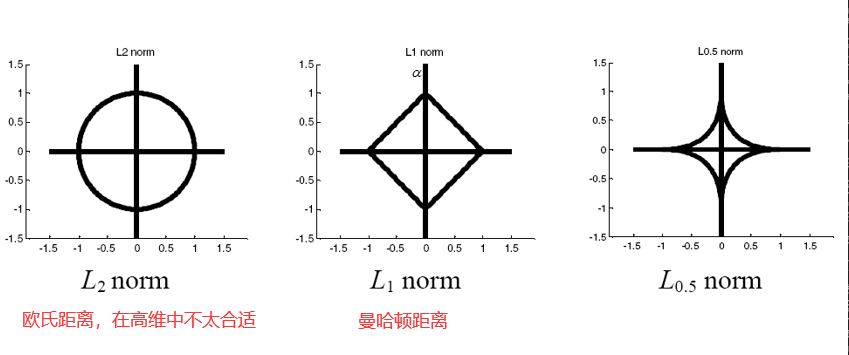
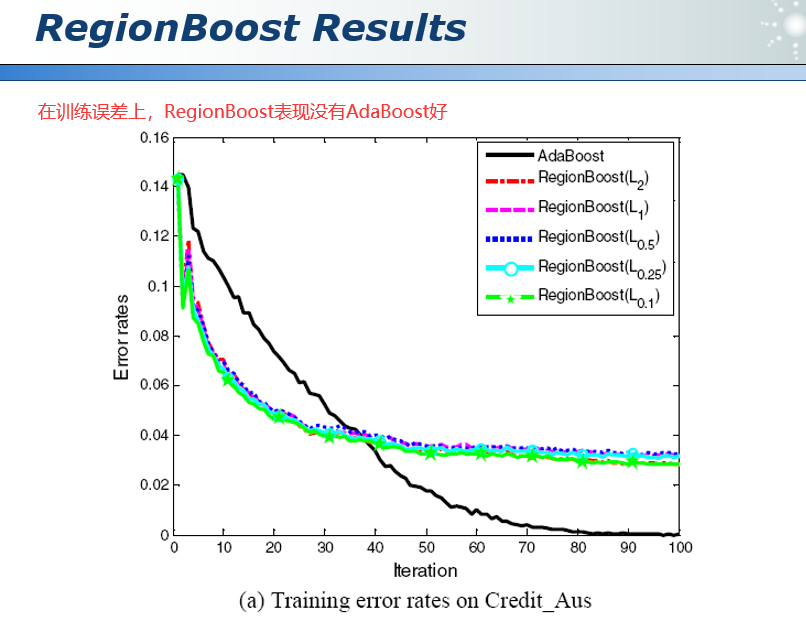
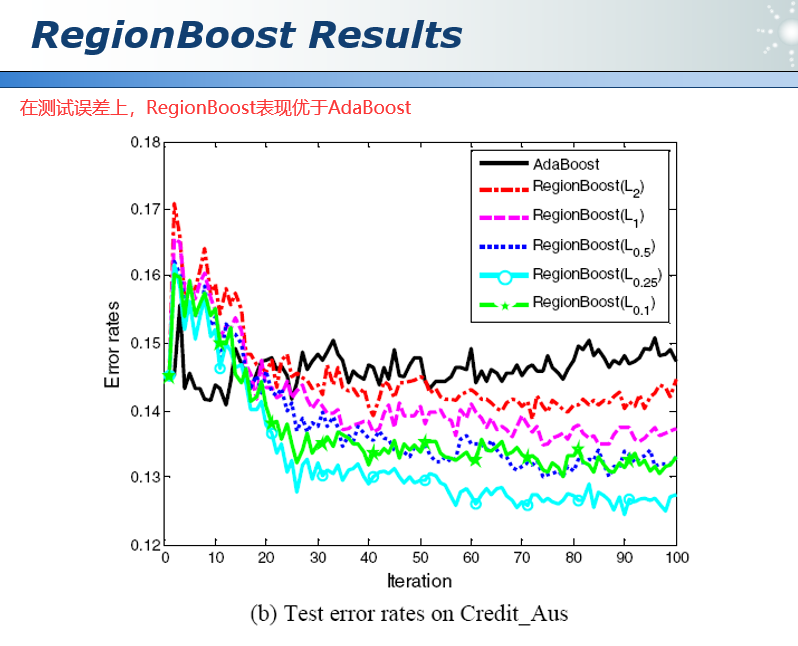
45.3 集成学习总结
集成学习就是非常有策略地生成一组分类器,然后再非常有策略地把它们组合起来。
集成学习的两种类型:
1)Parallel(Bagging)并行
2)Sequential(Boosting)串行
组合模型的不同方法:
1)取平均值。
2)少数服从多数。
3)加权的少数服从多数算法。
一些代表性的算法:
1)Random Forests
2)AdaBoost
3)RegionBoost
46 人与自然
在数据挖掘当中,分类、聚类、回归还是特征选择,我们都可以用进化计算获得满意的效果。传统的计算机系统,它的功能和结构都是比较固定的。也就是说,他能做什么,都是由设计者来确定好的。因此这样的系统很难实现超过人类的能力。
主要介绍的算法有:
1)全局优化(Global Optimization)
2)遗传算法(Genetic Algorithm)
3)遗传编程(Genetic Programming)
4)可进化的硬件(Evolvable Things)
进化算法(Evolutionary Algorithm)能为我们做什么?
1)优化
2)帮助人们了解自然界的进化,进而模拟自然界的进化。
什么是优化?
根据某些性能标准从一组候选对象中寻找感兴趣问题的最佳解决方案的过程。就是在完成一件事情的过程中,我们有很多可以完成的方法,优化就是帮助我们从中间挑选出最好的。
以最高标准完成预定义的任务。如机床完成订单(Job Shop)问题。
在资源有限的情况下产生最大产量。投资策略。
46.1 关键概念 Key Concepts
EA算法是基于群体的随机优化方法,区别前面讲的针对于单点的算法,例如20BP算法。随机是因为和梯度下降相比,它是随机的。是和梯度下降相比,梯度下降每一步都是确定的,而EA算法则是随机的,算法每一步的走向有一定的随机性,算法多次运行,结果不一定相同。
EA算法本质上并行搜索,所以不容易陷入局部最优。
工程中仿生学的一个很好的例子。
体现了适者生存的理念,还有染色体,杂交,突变等一些生物学上的概念。
元启发式(metaheuristics),其实和进化计算基本上是一个概念,heuristics是启发式搜索。生物/自然启发计算,也是进化计算。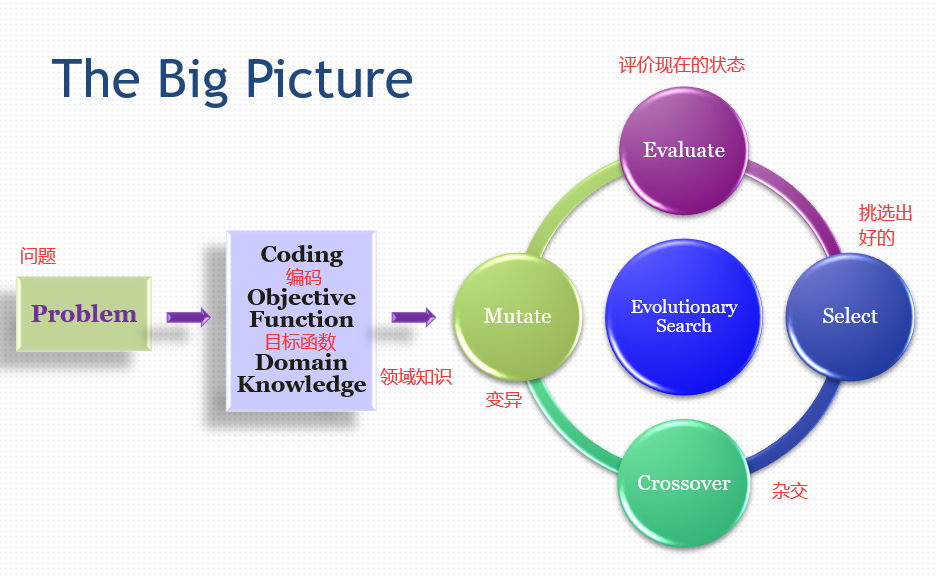
EA Family:EA并不是一个算法。
1)GA:Genetic Algorithm 遗传算法
2)GP:Genetic Programming 遗传编程
3)ES:Evolution Strategies 进化策略
4)EP:Evolution Programming 进化编程
5)EDA:Estimation of Distribution Algorithm 分布算法的估计
6)PSO:Particle Swarm Optimization 粒子群算法,模拟大规模鸟群或是鱼群的轨迹。
7)ACO:Ant Colony Optimization 蚁群算法,模拟蚁群的轨迹。
8)DE:Differential Evolution 差异进化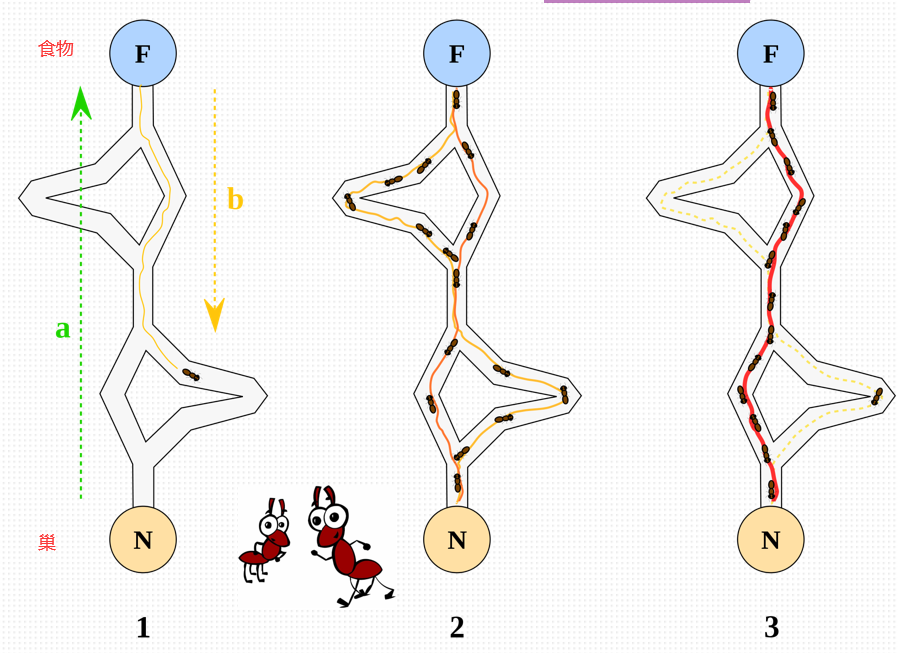
47 尽善尽美
47.1 目标函数 Objective Function

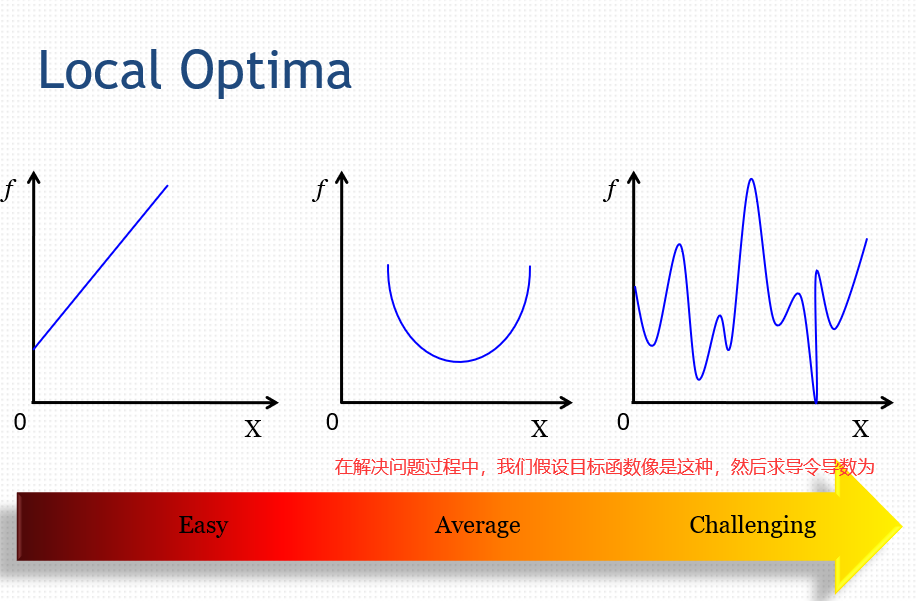
坏消息:
一、许多有趣的优化问题都不是简单的。不能总是在多项式时间内找到最优解。
二、仅仅是属性选择问题,就异常复杂。
1)从N个特征开始。冗余/无关/噪声。
2)选择特征子集。目标:最高精度。
48 走向进化
如何解决算法陷入局部最优的问题?
如何解决分而治之时变量之间的依赖问题?当一个问题Z有x和y两个变量时,Z要取得最小值,我们如果选择固定y寻找x和固定x寻找y,都无法找到最优点。即n维问题不能随随便便拆成n个1维问题。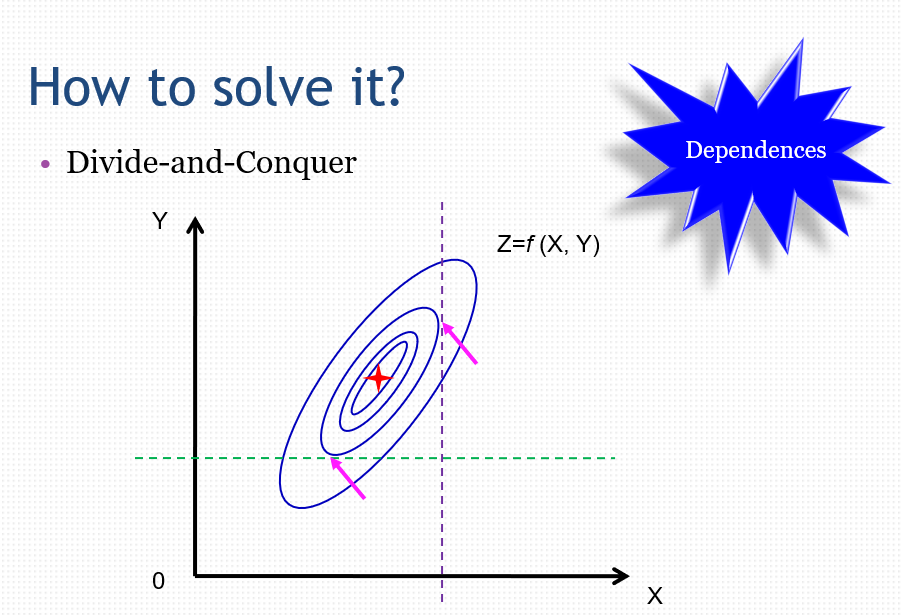
为了解决上述问题,我们就引入了并行搜索(Parallel Search)。
一、同时在不同区域进行搜索。
1)基于人口。
2)避免不幸的起始位置。
二、采用启发式方法有效地探索空间。
1)专注于有希望的地方。有一些人去搜索比较有希望的地方。
2)同时还要留意其他地方。还有一些人去搜索其他地方,是并行的。
3)不仅仅是随机重启策略。
总结:
一、进化算法:
1)关键概念
2)EA Family
二、什么是优化?
三、典型的优化问题。
四、是什么让问题难以优化?进化计算产生的原因。
49 遗传算法初探
49.1 生物学背景 Biology Background
gene基因:DNA的一个功能片段。
gene trait基因控制的性状:例如眼睛的颜色
allele等位基因:特征的可能设置,如褐色、灰色和蓝色。
genetype基因型:个体携带的实际基因。tt还是ts
phenotype表现型:基因被翻译成的物理特征。
49.2 遗传算法 Genetic Algorithms
John Holland受达尔文理论启发,算法大致基于达尔文理论:
1)染色体
2)交叉
3)突变
4)选择(适者生存)
基本思想:
1)问题的每个解决方案都可以表示为一条染色体。
2)初始解可以随机生成。
3)解决方案在一代个体与一代个体之间进化。
4)根据自然进化的原理逐步改进。
49.3 基础概念 Basic Components
一、表示
1、如何编码问题的参数?
2、二元编码 10001,00111,11001……
3、连续编码 0.8,1.2,-0.3,2.1……
二、遗传算子
1、交叉:在两条染色体之间交换遗传物质。
2、突变:随机修改选定位置的基因值。
三、选择策略
哪些染色体应该参与繁殖?
在选择参与繁殖的子代时,我们对子代进行打分。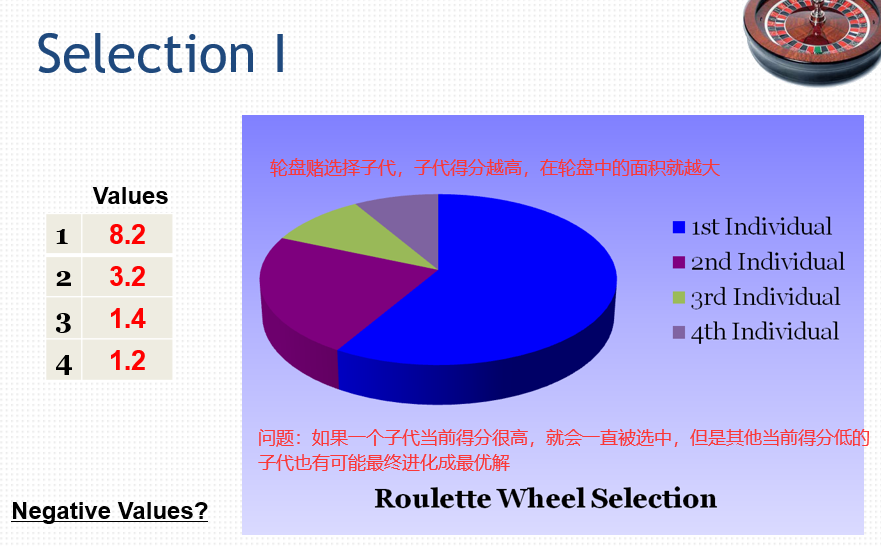
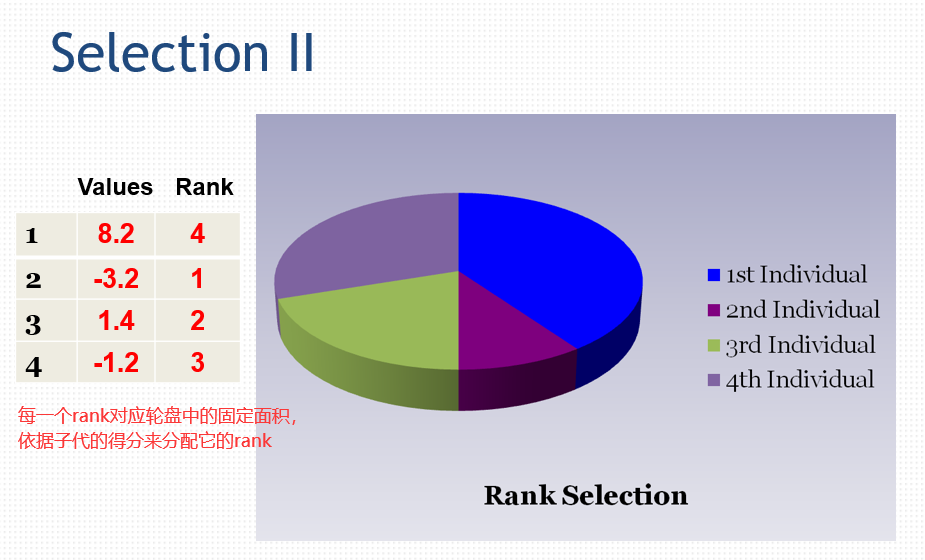

精英主义:
1)后代不一定比父母好。
2)当前人群中最优秀的个体可能会流失。被交叉和突变破坏。
3)将最好的个体复制给下一代。(类似于为了防止发挥失常,保送上大学)
4)提高GA的稳定性和性能。
后代选择:
1)通常父代被子代取代。
2)把父代和子代合在一起,然后从中选取n个得分高的子代。
哪些后代应该能够生存?
四、个体(染色体)
1、表示问题的特定解决方案的向量。
2、向量上的每个元素对应于某个变量/参数。
五、群体
1、一组个体。
2、GA(遗传算法)维持和进化了一群个体,让100+个个体同时进行搜索。
3、并行搜索→全局优化,更容易发现全局最优点。
六、后代
1、通过遗传算法产生的新个体。
2、希望后代中包含更改好的解决方案。
七、编码
1、二进制编码和gray(格雷)编码
2、如何编码TSP(旅行商问题中城市编码)问题。
对于gray编码的圆盘,旋转过程中每次只有一位改变,如果内环和外环不同步,比相同情况下binary编码更为稳定。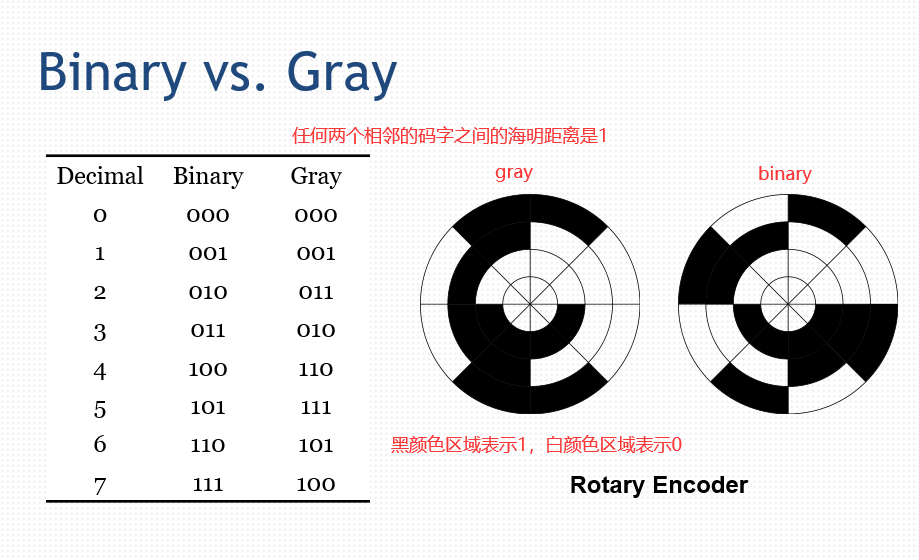
50 遗传算法进阶
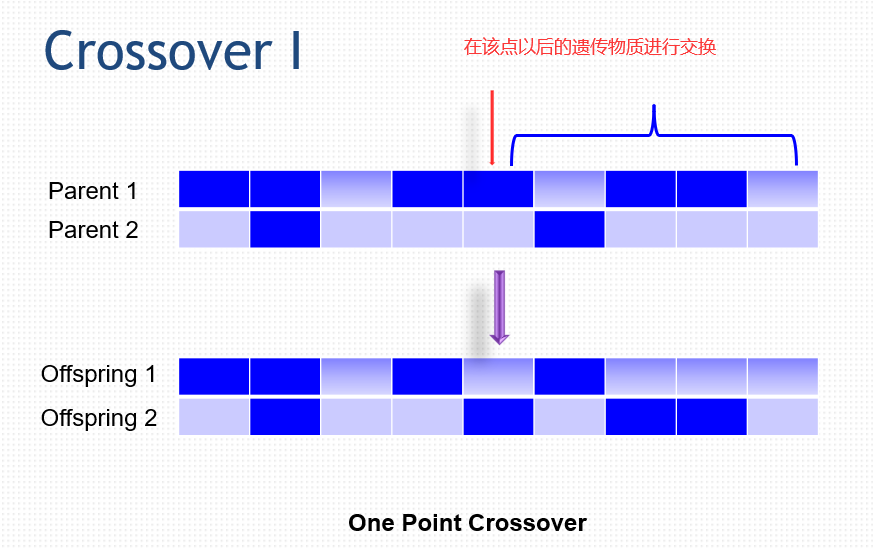
50.1 交叉 Crossover
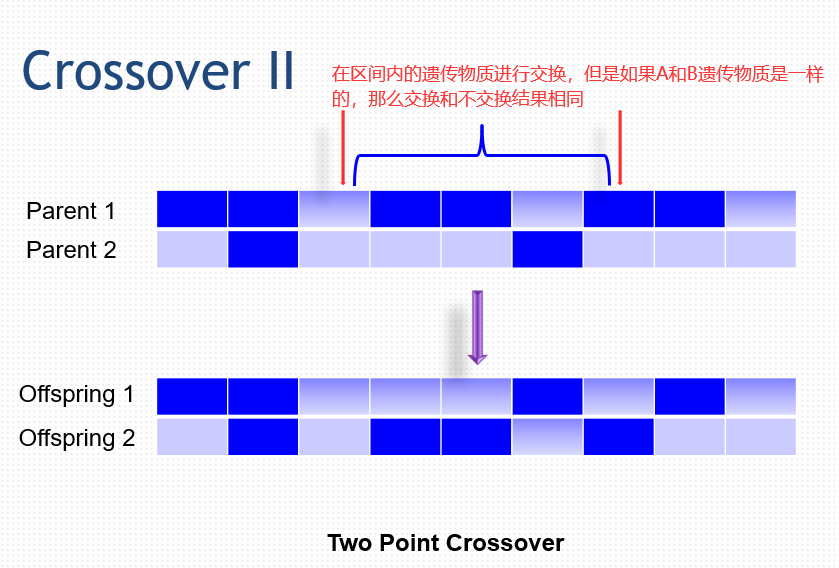
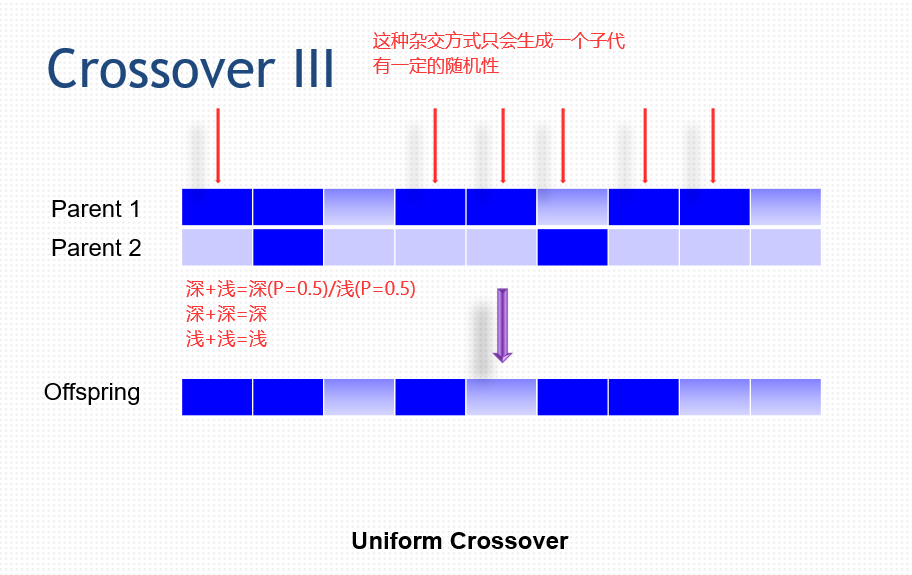
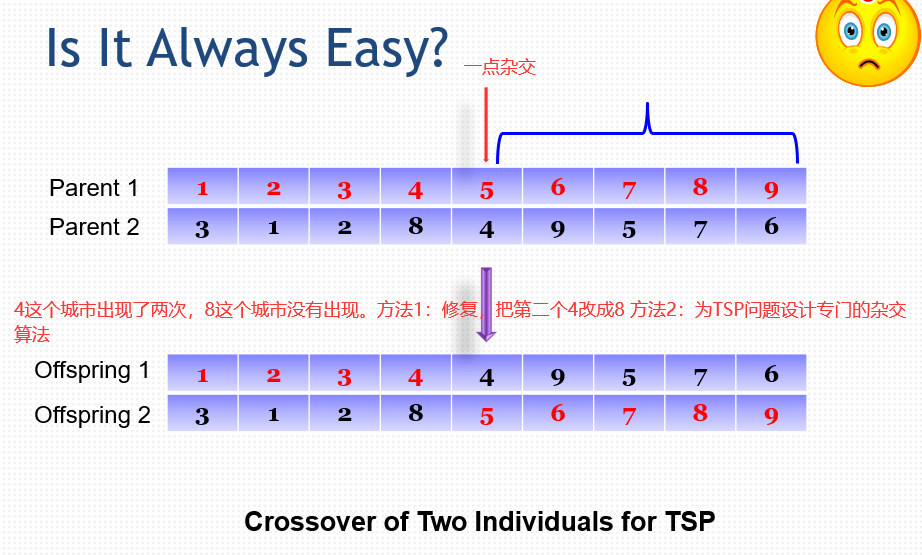
50.2 变异 Mutation
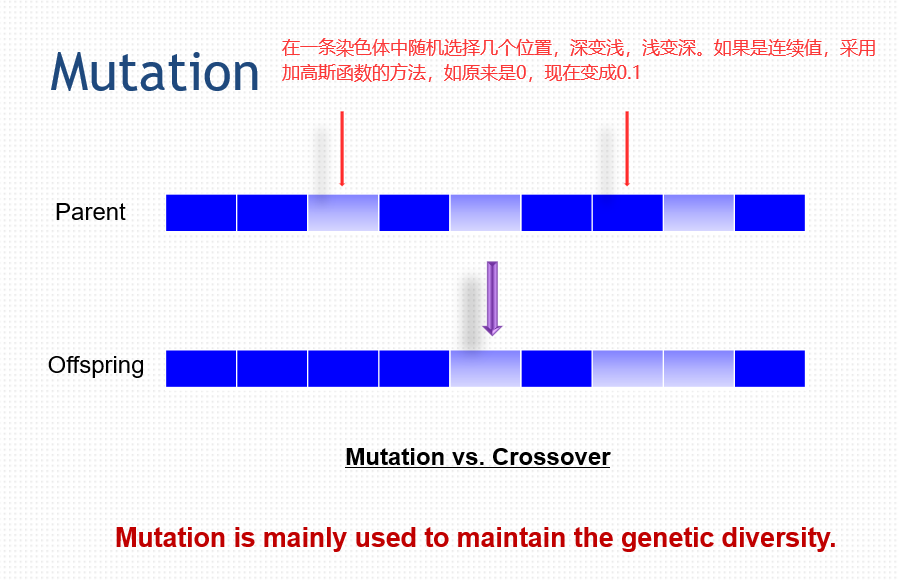
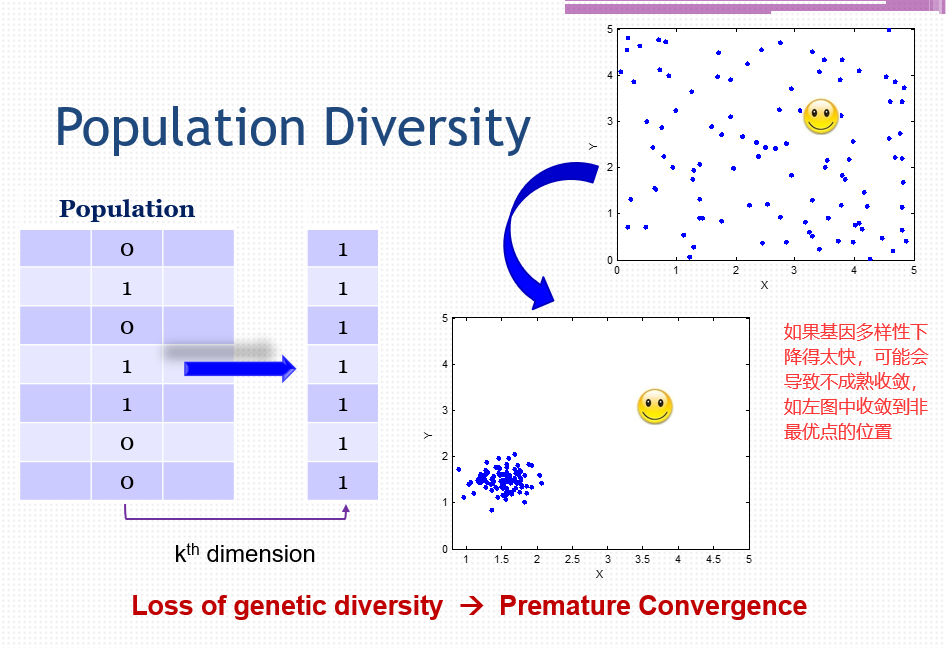
选择(Selection)
1)将搜索努力偏向有前途的个人。
2)可能会导致基因多样性的丧失。
交叉(Crossover)
1)通过结合来自优秀个体的基因来创造更好的个体。
2)积木假说。好的父代可以有更好的子代。
3)GA的主要搜索能力来源。
4)对遗传多样性没有影响。
突变(Mutation)
1)增加基因多样性
2)强制算法搜索当前焦点以外的区域。
思想:exploration,就是注重搜索的广度。exploitation,就是注重深度的搜索。就是搜索广度和搜索深度的平衡。
50.3 算法框架
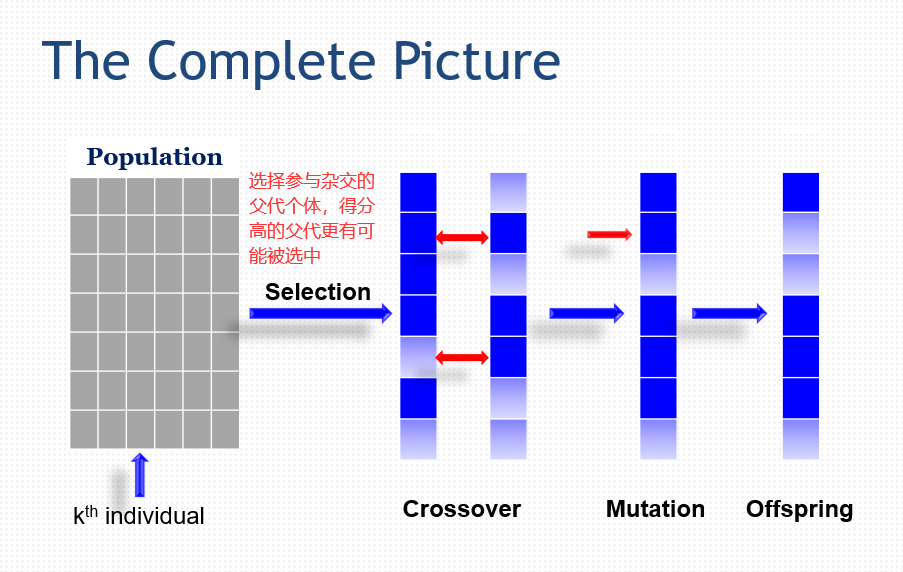
1 | 随机生成一个初始种群包含M个个体。 |
50.4 遗传算法的参数
种群大小:
1)太大:收敛速度慢。
2)太小:过早收敛。
交叉的概率:推荐值 0.8
变异的概率:
1)推荐值 1/L,L是每个个体的位数,比如一个个体是100100,那么变异的概率就是1/6。
2)太大:扰乱进化过程。
3)太小:不足以维持多样性。
选择策略:
1)比赛选择。两两PK或是三三PK。
2)截断选择(选择前T个个体)。例如高考,会有分数线。
3)需要注意选择压力。如果一开始就给一些适应强的个体很高的优先权,那么资源就会向这些个体倾斜,有可能会陷入局部最优。
没有免费的午餐:
1)所谓的最佳参数并不存在。
2)每个问题的最优参数因问题而异。
3)我们不知道最优参数,因此需要一些试验来找到合适的参数值。
随机性:
1)固有随机算法。
2)表现性评估需要独立性实验,即多次实验。
为什么遗传算法有效?
1)易于理解和实施(无需数学)。
2)很难进行数学分析。
3)以概率1(无限人口)收敛到全局最优值。
4)图氏定理。
51 用遗传算法解决问题
51.1 特征选择 Feature Selection
从原始特征中选择特征子集。
1)降维。
2)删除不相关的特征。
好处:
1)训练难度降低。
2)运行时间更快。
3)精度更高。
4)理解难度更低。
方法:
1)Filter Method:不考虑分类器,只是从属性出发,选择更有区分度的属性。
2)Warpper Method:把使用的分类器作为一个参数,也包含在特征选择当中,针对不同的分类器特征选择结果不同。
个体表示:二进制字符串
适应度函数:一个分类器(KNN,SVM,ANN等等),例如,选择五个属性,放到SVM中训练一下,看看准确度多高,使用误差作为适应度的量化指标,误差越小,适应度越高。
进化一组候选特征子集。
主要问题:
1)候选特征的数量(维度诅咒),先降维再GA。
2)计算开销。
51.2 GA算法用于聚类初始参数选择
聚类:根据一定的相似度度量将一组数据划分为K个组的过程。属于无监督学习,不需要标记数据集。
基本过程:
1)选择K个点作为初始聚类中心。
2)将每个点分配给具有最近中心的簇。
3)重新计算K个中心的位置。
4)重复步骤2和3,直到中心不再移动。
但是如果K个中心的初值没有选好,那么算法可能会收敛到局部最优。我们可以用遗传算法来选择这k个中心点。
使用GA算法最终确定一组最优聚类中心。
问题表示:
1)用一个字符串表示K个簇的中心。
2)长度:KD(D为数据维数)
适应度评估:
1)将每个数据分配给最近的簇。
2)计算新的簇的中心。
3)更新旧的簇的中心。
4)聚类的质量通过以下方式衡量:M的值越小越好,证明每个簇内数据点越聚集。
这证明了遗传算法框架在解决问题过程中的普适性。
51.3 开放思考
参数控制:GA算法中有许多参数需要设置。
1)参数调整。根据进化过程动态调整参数。
2)用于在运行过程中更改参数值的启发式方法。
约束处理:所有现实世界的问题都有约束。
1)有界约束。x在0和1之间,y在0和1之间。
2)线性约束。如x+y≥1。
多目标优化:多目标可能是矛盾的:
1)模型复杂度和预测准确度的权衡。
2)利润与风险的权衡。例如,多赚钱与低风险的矛盾。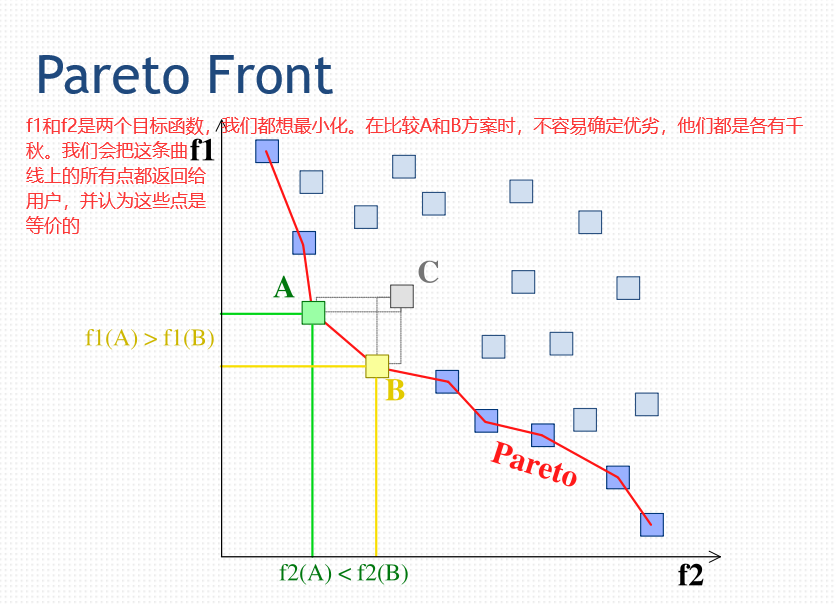
因为GA算法的计算量很大,但是各个搜索之间是并行的,因此我们可以用并行计算对GA算法进行加速。
51.4 总结回顾
遗传算法的基本概念。
主要概念:
1)交叉。
2)变异。
3)选择。
4)表示,编码。
遗传算法的框架。
参数选择问题,如果选择不好可能会导致GA算法陷入局部最优。
遗传算法在特征选择和聚类中的应用。
52 遗传程序设计
52.1 GA(Genetic Algorithm) vs. GP(Genetic Programming)
1)GP是GA的一个分支。交叉/变异/选择。
2)表示
+++GA:包含一串数字(0/1)的字符串。
+++GP:树形结构的计算机程序(LISP)
3)输出
+++GA:优化适应度函数的一组参数值。
+++GP:一个计算机程序(是的,一个计算机程序!)
52.2 GP中的重要概念
构建计算机程序块,该程序用树来表示。
Terminal Set:
1)变量:x,y,z……
2)常数:1,2,3……
Function Set:
1)+-*/
2)问题特定功能。
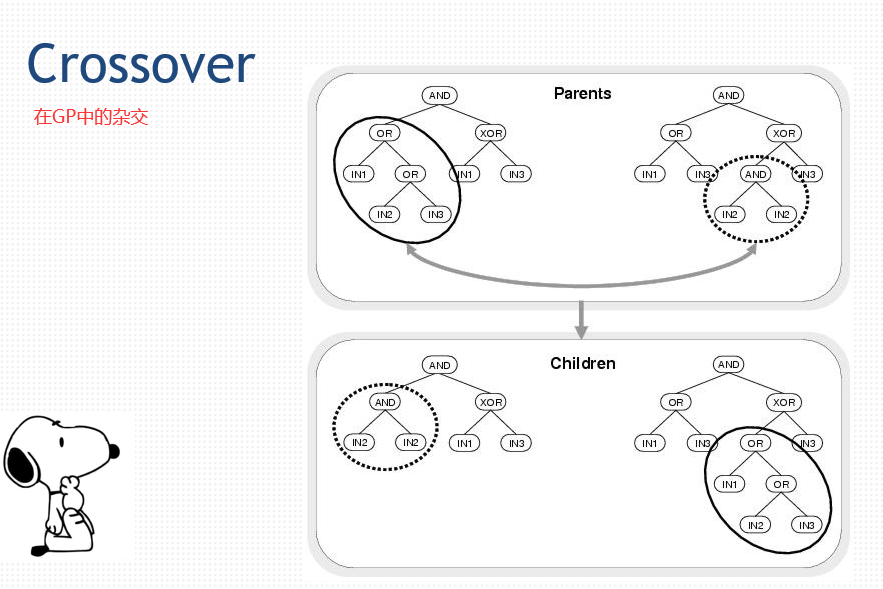
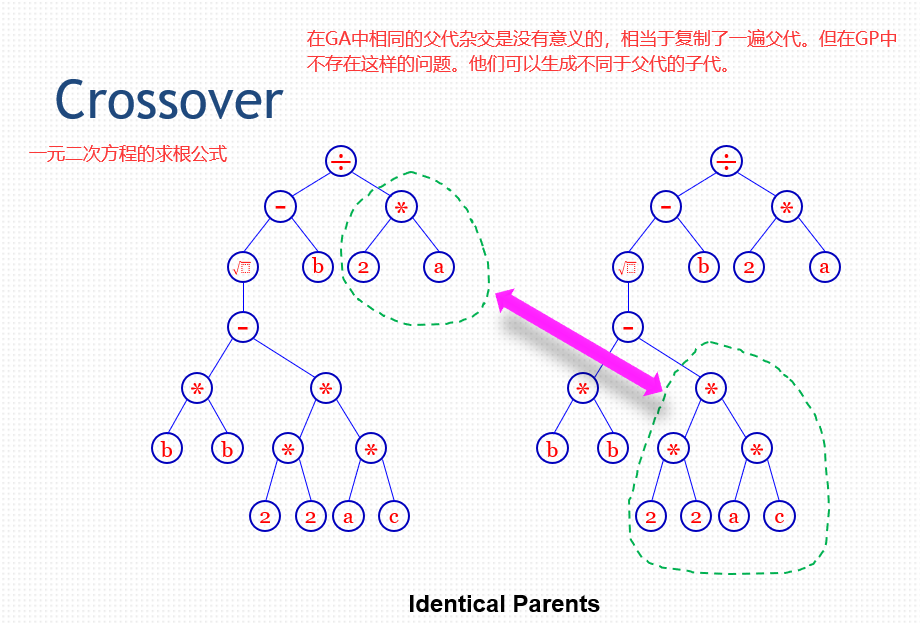
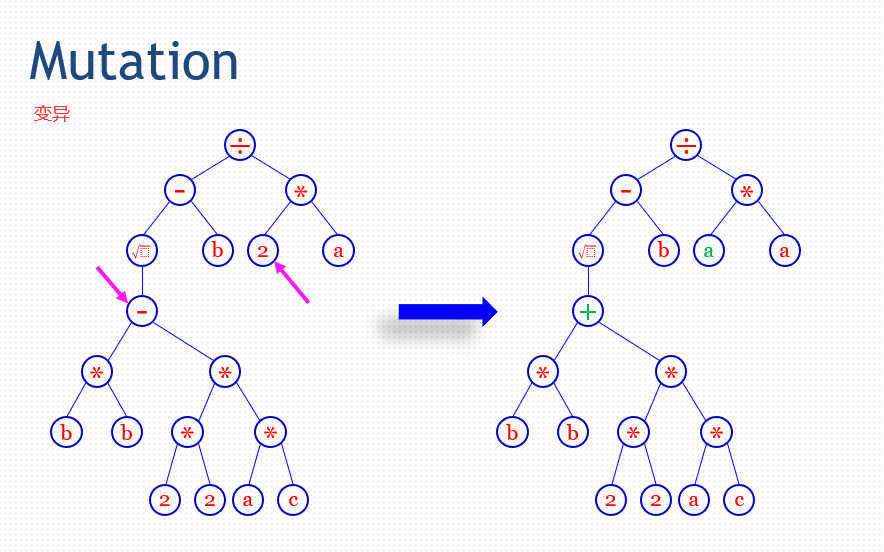
52.3 GP的例子
符号回归。
给定一组数据点(x,y)(生成的点)。
使用GP得到在生成数据点时使用的二次多项式。
1)得到给定x的y的近似值。
2)找到生成函数y = f(x)。
适应度评价:
差值的绝对值
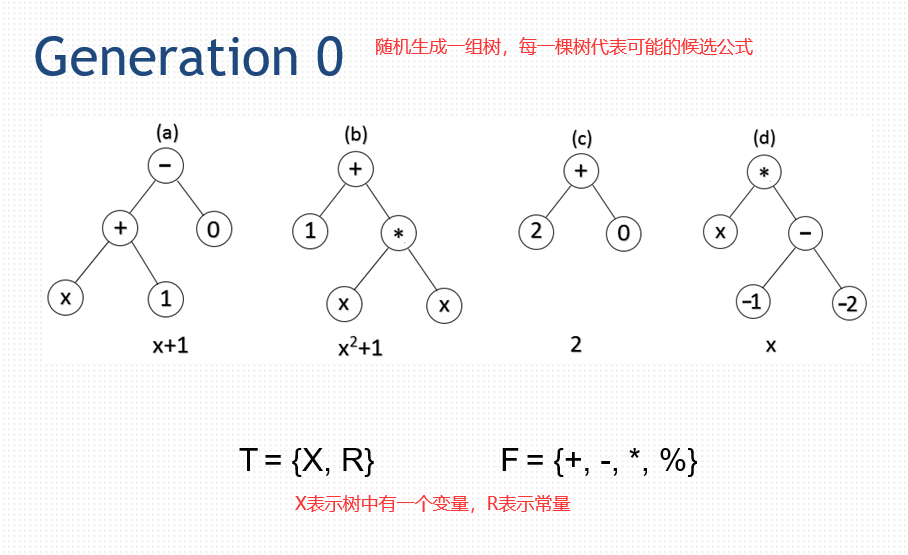
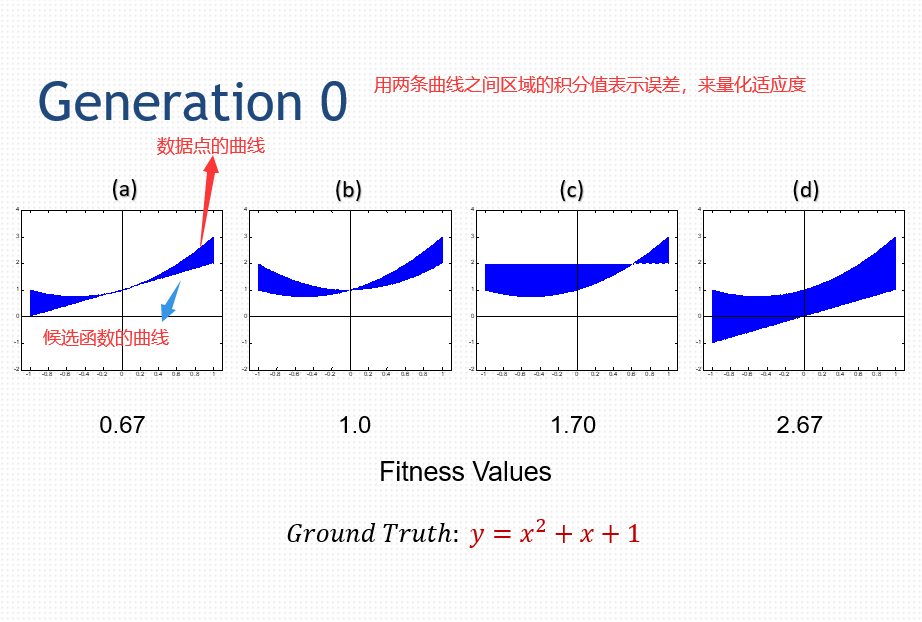
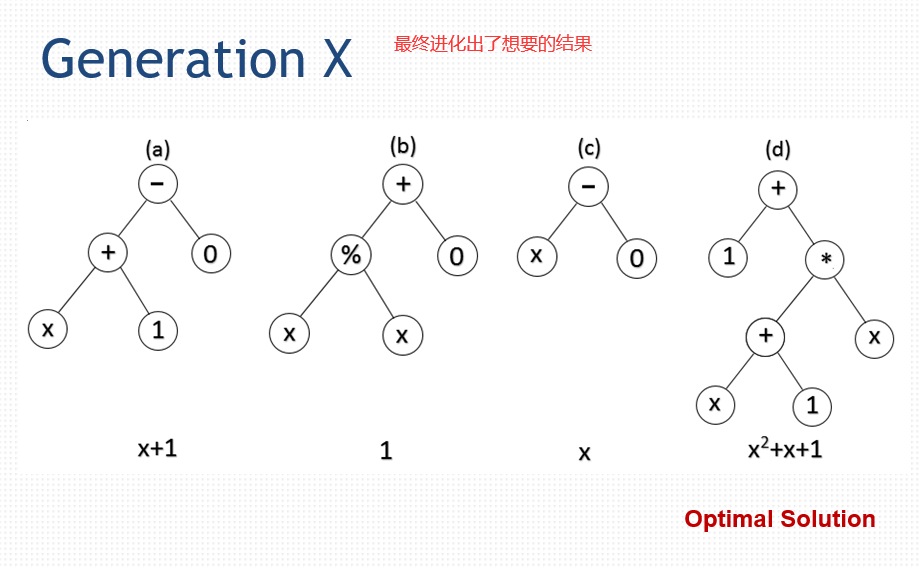
52.4 总结
树状结构的计算机程序
1)长度灵活,树可以灵活边长和变短。
2)根据问题确定terminal set和function set。
应用:
1)回归问题。
2)控制问题。
3)分类问题。
可进化的硬件:通过与环境交互动态和自主地改变其架构和行为地电路。
53 万物皆进化
在实际问题中,适应度函数非常难确定,可能需要人工来评价。
进化算法:
1)一组受自然启发的算法。
2)通用技术(非常强大且普适)。
遗传算法可以做:
1)功能优化。
2)特征选择。
3)分类。
4)聚类。
遗传编程可以做到:
1)回归。
2)分类。
3)智能设计。
END