1 神经网络和深度学习
1.1 什么是神经网络
“深度学习”指的是训练神经网络的规模很大。
学习进度 01:31
2 改进深度神经网络:超参数调整、正则化和优化
3 结构化机器学习工程
4 卷积神经网络 Convolutional Neural Networks
5 自然语言处理:建立序列模型
5.1 数学符号
例如我们需要在一句话中定位人的名字,即命名实体识别问题,这一问题常用于搜索引擎。命名实体识别系统可以用来查找不同类型的文本中的人名、公司名、时间、地点、国家名、货币名等等。
给定一段文字输入x,我们希望模型输出的数据y能标识x中的每个单词是否是人名的一部分。下图中,我们将输入的文字索引为x^1,x^2…x^9,然后我们对输出数据y使用相同的索引方式,y^1,y^2,y^3…y^9。我们使用T_x来表示输入序列的长度,T_y来表示输出序列的长度。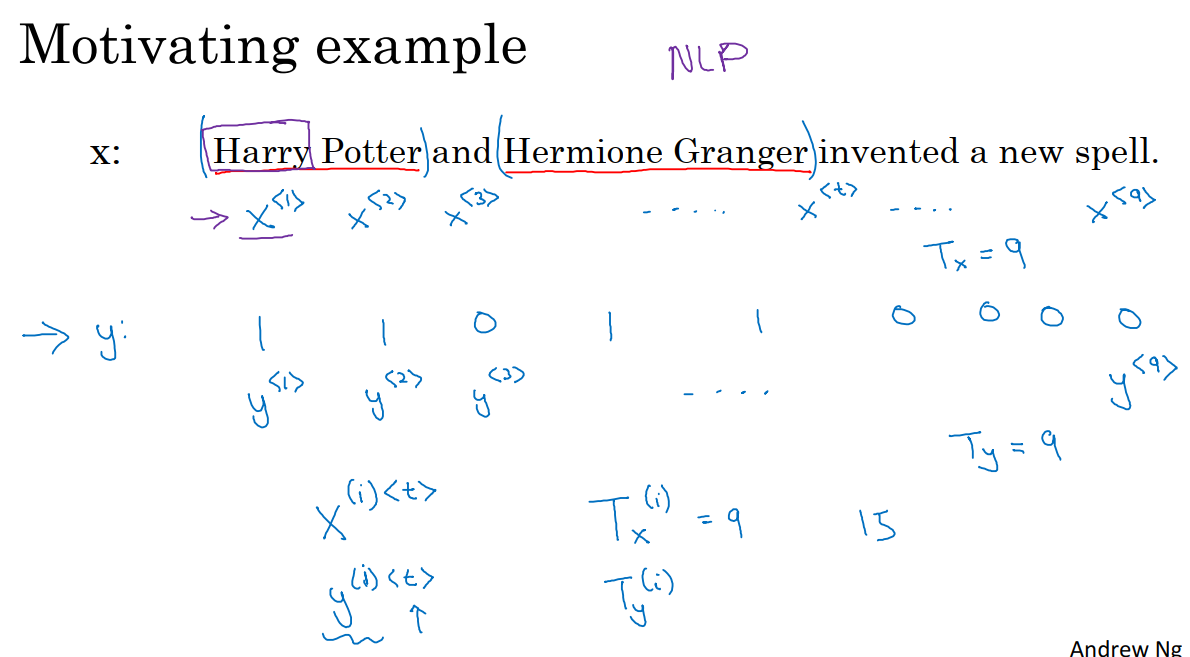
对于第i个训练集x^i,我们用x^(i)(t)表示训练样本i序列中第t个元素,T_x是序列的长度,训练集中不同的训练样本就会有不同的长度,T_x^i表示第i个训练样本的输入序列长度。同样地,y^(i)(t)代表第i个训练样本中第t个元素,T_y^i就是第i个训练样本的输出序列的长度。
对于输入的序列x,我们需要思考如何表示一个序列里单独的单词。
首先我们需要做一张词表,也叫做词典,就是将我将要用到的单词做成一个列表。这样词典中的每一个单词都对应了一个索引。
接下来我们使用one-hot表示法来表示词典里的每个单词,例如Harry在我们词典中的索引是4075,那么我们使用一个长度为10000(词典长度)的向量来表示一个单词,对于Harry来说,其余行都是0,只有第4075行是1。同样上图中potter也使用类似的表示方法。最终,我们将会使用9个向量来表示输入的文本x。我们的训练数据将会是带有对应标签的x。我们使用UNK来表示没有在词典中出现的单词。
5.2 循环神经网络
我们考虑使用标准的神经网络来完成x到y的映射。如下图,神经网络的输入为经过one-hot编码得到的9个向量,输出为9个值为0/1的项,来表示输入的单词是否是人名的一部分。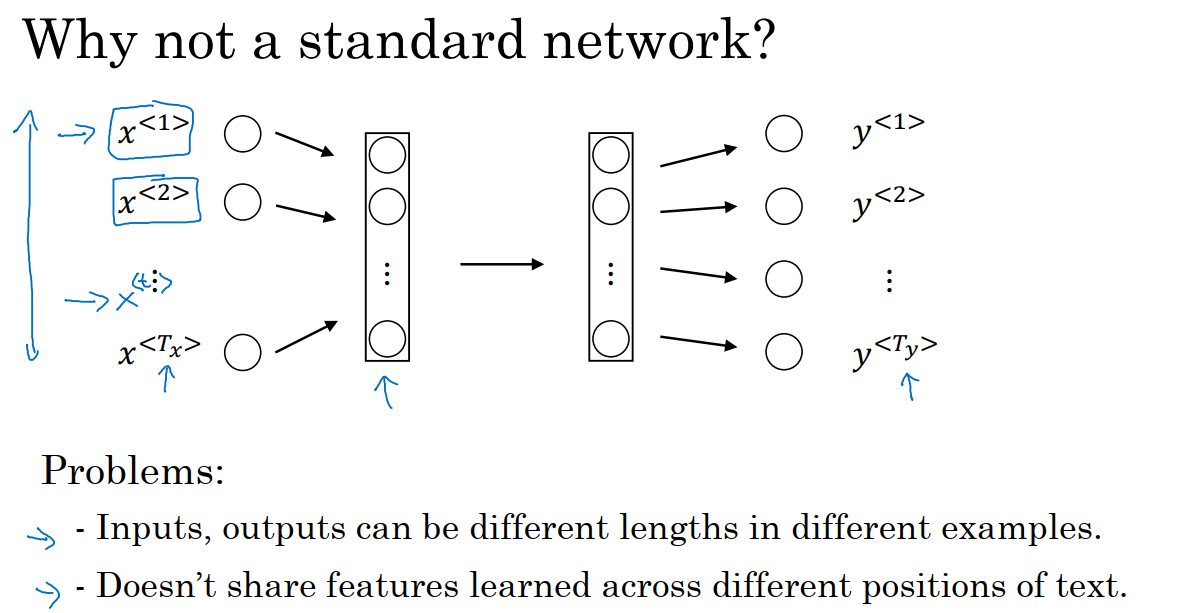
但结果表明这个方法并不好,主要存在两个问题:
1 输入数据x和输出结果y在不同例子中可以有不同的长度。不是所有的例子都有着同样输入长度T_x。即使每个句子都有最大长度,也许我们能够填充或0填充,使每个输入语句都达到最大长度,但仍然看起来不是一个好的表达方式。
2 标准神经网络并不共享从文本的不同位置学到的特征。例如在输入文本索引1出现的harry是人名的一部分,那么当Harry出现在其他位置时,我们希望它也能被识别为人名的一部分。
同时我们需要注意到,这个输入层非常庞大,它的大小为每条样本中最大单词数乘以10000,那么第一层的权重矩阵就会有巨量的参数。
为了改善这些问题,我们有了循环神经网络。如上图,图中每一个块代表一个神经网络。如果我们从左到右读句子x,那么第一个单词就是x^1,我们要做的就是将x^输入到第一个神经网络的隐藏层,我们让这个神经网络尝试预测并输出结果。当神经网络读到句子x的第二个单词x^2时,它不是仅用x^2预测出y^2,它也会输入一些来自时间步1(也就是上一步)的信息,时间步1的激活值(激活项,是指由一个具体的神经元计算并输出的值)就会传递到时间步2,然后在下一个时间步。循环神经网络输入了单词x^3,然后输出了预测结果y^3,直到最后一个时间步,神经网络的输入为x^(T_x),神经网络的输出为y^(T_y),对于这个样本数据,T_x = T_y,如果不等,则这个结构会需要作出一些改变。
所以,在每一个时间步中,循环神经网络传递一个激活值到下一个步中用于计算。要开始整个流程,我们在零时刻,需要编造一个激活值(伪激活值),它通常是一个0向量。
在上图中的右边位置,是有些论文中用来表示循环神经网络的方法,在课程中,我们一般使用左边这种表示方法。
循环神经网络是从左向右扫描数据,同时每个时间步的参数也是共享的。W_ax管理着从x^1到隐藏层的连接的一系列参数。每一个时间步使用的都是相同的参数W_ax。而激活值,也就是网络中的水平联系是由参数W_aa决定的,同时每一个时间步都使用相同的参数W_aa。网络的输入由W_ya决定。
在这个循环神经网络中,上一时间步的信息通过水平连接传递给下一时间步来帮助当前时间步进行预测。这个循环神经网络的缺点就是它只使用了这个序列中之前的信息来做出预测,而没有办法使用这个序列之后的信息,例如我们在预测索引3位置的单词时,没有用到4、5、6等等位置的信息。但是在实际使用中,我们做出正确的判断也需要后面的信息,如上图中的Teddy,在第一句中是人名,但在第二句中却不是。
在后面,我们学习的双向循环神经网络(BRNN)的时候解决这个问题,现在我们以RNN为例进行讲解。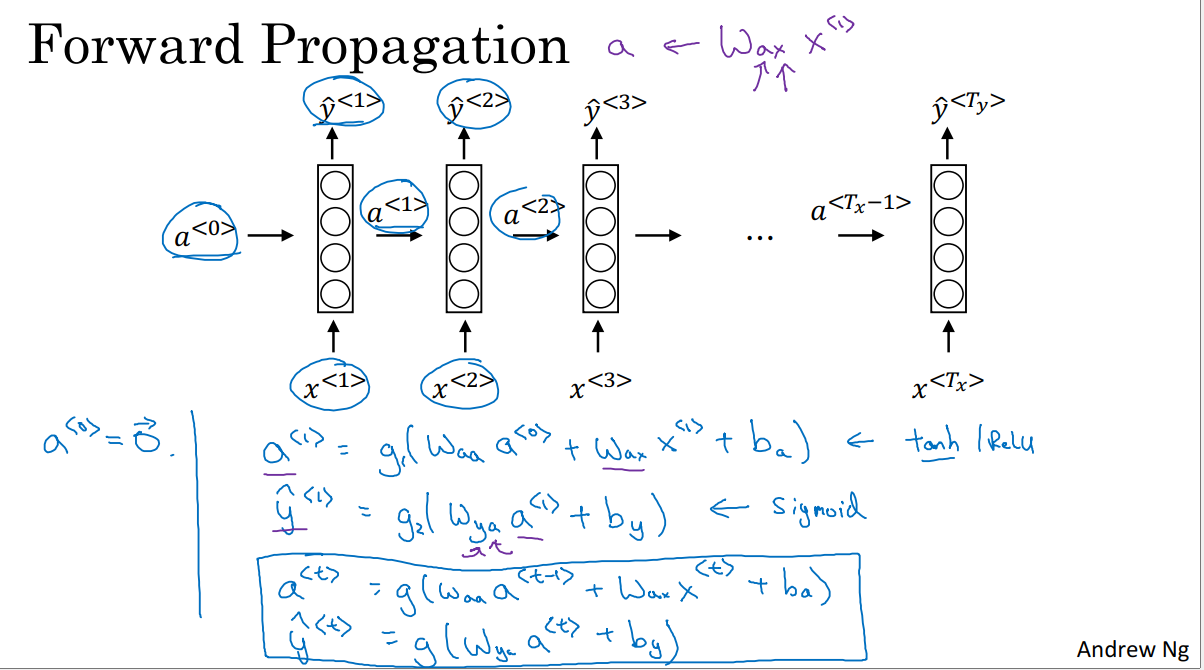
如上图,我们先来了解一下前向传播的过程。一般开始先输入a^0,它是一个零向量。接着为了计算a^1,我们使用
然后计算y^1:
这里解释一下参数下标的含义,例如W_ax,第二个下标的名字为x,表示它将乘上一个x类型的量,第一个下标的名字为a,表示它是用来计算a类型的量的。
循环神经网络用的激活函数经常是选用tanh,有时也会用ReLU,但是tanh是更通常的选择。选用哪个激活函数是取决于我们的输出y,如果它是一个二分问题,激活函数为sigmoid,如果是k分类问题,激活函数是softmax。对于命名实体识别来说,y只可能是0或者1,因此我们计算y使用的激活函数为sigmoid。
同理我们可以计算出t时刻的a^t,结果如上图。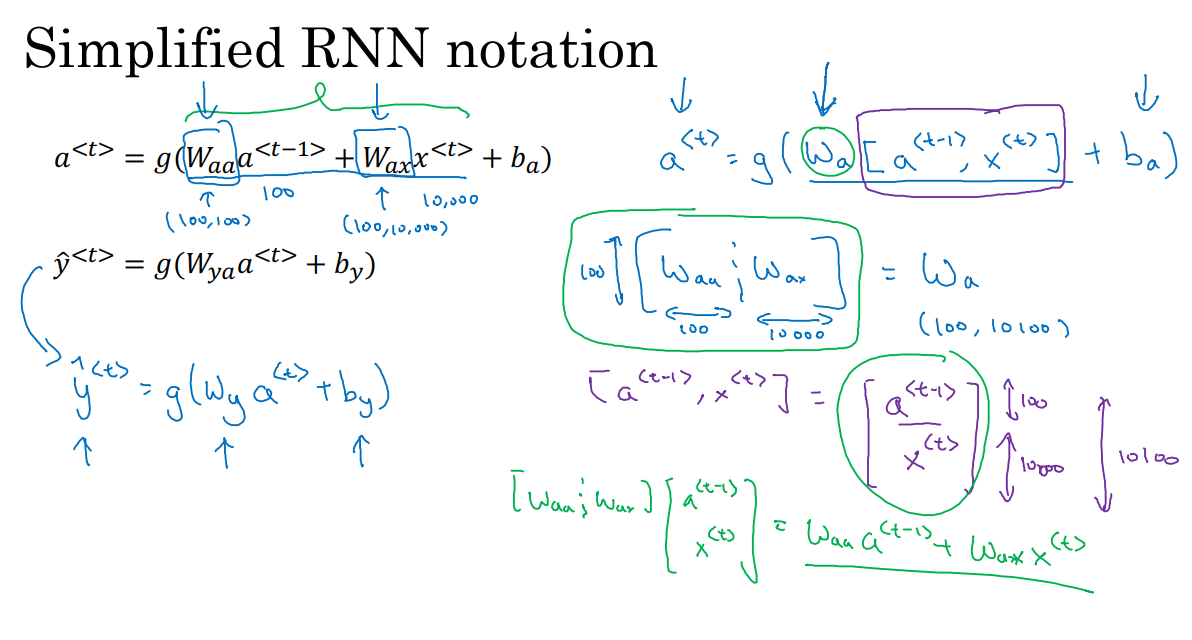
在上图中,我们将Waa和Wax矩阵水平放置在一起,形成一个矩阵W_a。例如,a的维度是100(a指的是单元数目),x的维度是10000,那么W_aa就是100*100的矩阵,W_ax就是100*10000的矩阵,因此如果将这两个矩阵并排放置,W_a就会是个100*10100维的矩阵,具体细节如上图右边。
则有:
[]的意思是将这两个向量竖直放置在一起,如上图中紫色部分,最终得到10100维的向量。仔细观察绿色部分的两个矩阵相乘,实际上就等价于W_aa和a相乘,W_ax和x相乘。
这样做的好处是我们可以不使用两个参数矩阵W_aa和W_ax,而是将其压缩成一个参数矩阵W_a,这样能够简化我们要用到的符号。
同样对于y的计算,我们可以简化成图中左边蓝色部分,W_y表明它是计算类型y的权重矩阵,而上面的W_a和W_b则表示这些参数是用于计算a的值(激活值)
5.3 通过时间的反向传播
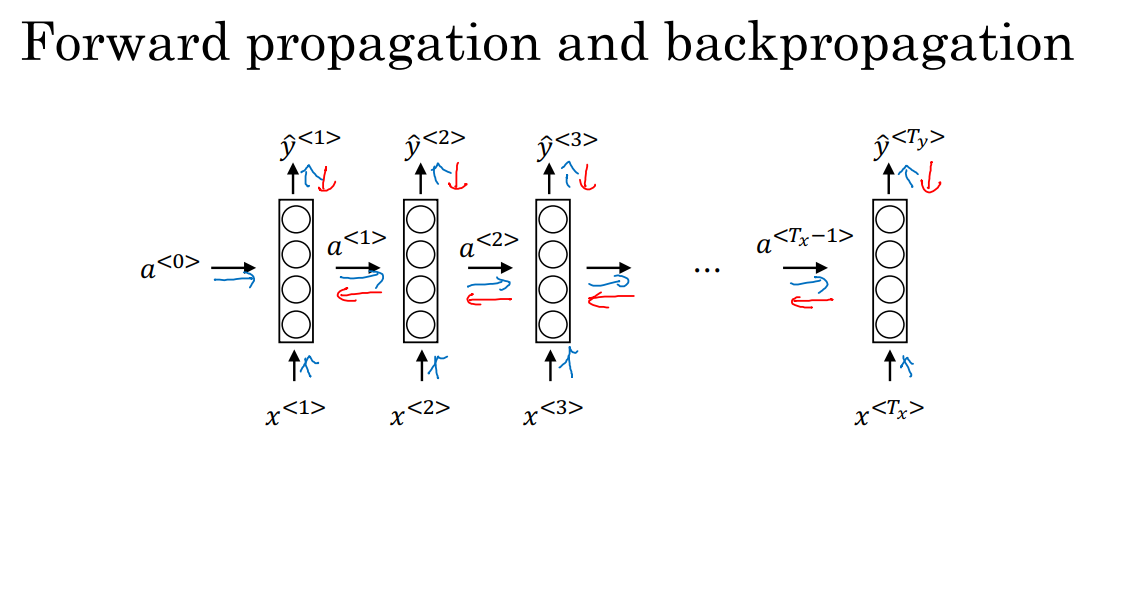
在上图中,蓝色表示前向传播的计算方向,红色表示反向传播的计算方向。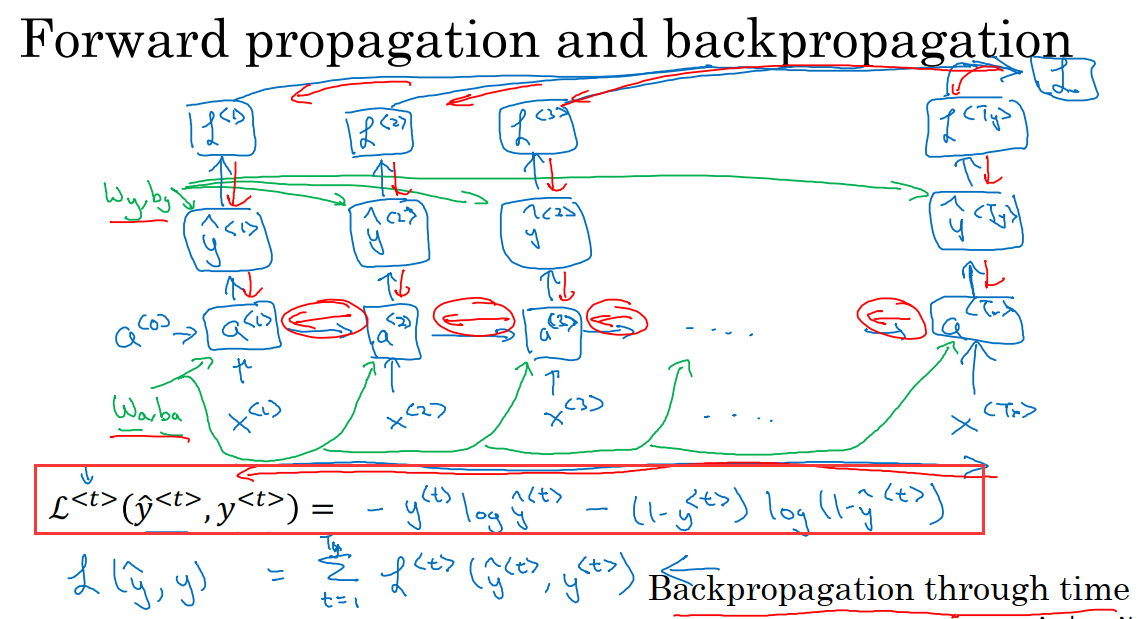
在上图中,我们有一系列的输入x^1,x^2,…,x^T_x。然后我们用x^1和a^0计算出时间步1的激活项a^1;用x^2和a^1计算出时间步2的激活项a^2。在这个过程中我们需要的参数为W_a和b_a,这两个参数会被用于计算出所有的激活项。
然后我们通过a^1计算出预测输出y^1,在下一个时间步中,我们通过a^2计算出预测输出y^2。在这个过程中我们需要的参数为W_y和b_y,这两个参数会被用于计算出所有的输出y。
在进行反向传播之前,我们需要一个损失函数。我们先定义一个元素损失函数,它对应的是序列中一个具体的词,如果第t个数据是人名,那么y^t就是1,然后神经网络将输出第t个值是名字的概率y_pre^t,例如y_pre^t=0.1。我们将损失函数定义为标准逻辑回归损失函数,也叫交叉熵损失函数。具体公式见上图红框部分。这是关于单个位置上或者说某个时间步t上某个单词的预测值的损失函数。
现在我们来定义整个序列的损失函数。将L定义为从t=1开始一直到t=T_x/T_y(因为T_x=T_y),对每一个时间步的损失求和。
于是在上图中,我们可以通过y_pre^t和y^t计算出时间步t的损失函数。最后我们的反向传播就是沿着红色箭头的方向进行计算。然后我们就可以使用梯度下降法来更新参数。在反向传播过程中最重要的信息传递就是从右到左的运算,因此这个算法还有个名字叫做通过时间(穿过时间)的反向传播。这是因为在前向传播中,我们是从左到右进行计算,在反向传播的过程中,我们从右到左进行计算,就像是时间倒流。
5.4 不同类型的循环神经网络
在前面我们谈论的RNN模型T_x=T_y,但是在实际问题中,T_x和T_y不一定相等。我们需要修改基本的RNN结构来处理这些问题。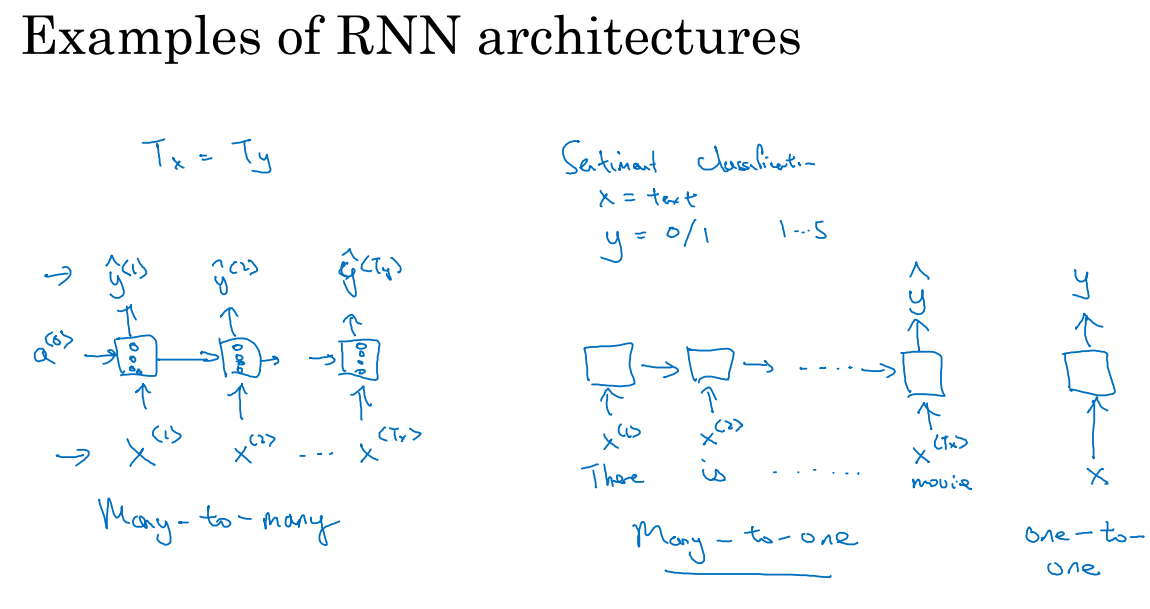
多对多结构:上图中左边的位置,输入序列有很多的输入,而输出序列也有很多输出。
多对一结构:输入x可能是一段文本,例如一个电影的评论,输出y是1-5或是0-1的数字。我们一次输入一个单词,如图中中部位置,我们不再在每个时间步上都有输出了,而是让这个RNN网络读入整个句子,然后在最后一个时间上得到输出。它的特点是输入序列有很多,然后只输出一个数字。
一对一结构:这就是一个小型的标准的神经网络。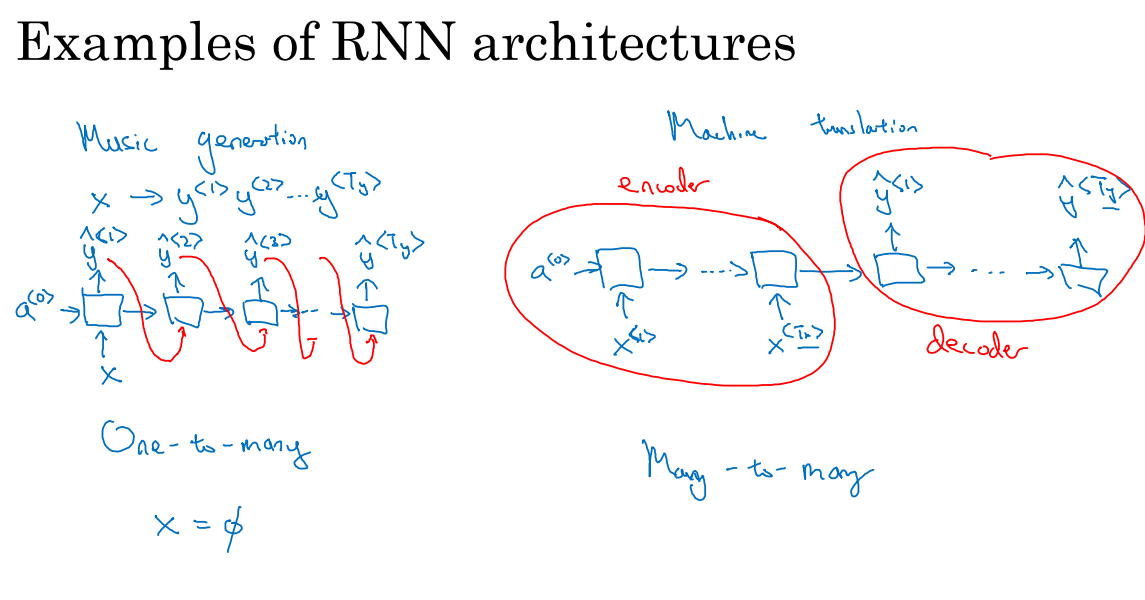
一对多结构:常用于音乐生成。我们的输出是一些音符,对应于一段音乐。输入x可以是一个整数,表示我们想要生成的音乐类型。首先我们输入x得到RNN输出的第一个值,在下一个时间步中,模型没有输入参数,输出第二个值。我们会在开头提供一个伪激活项a^0。这里有一个后面会涉及的技术细节,当我们生成序列时,通常会把第一个合成的输出也喂给下一层,所以实际的网络结构最终如上图左边所示。
对于多对多模型,我们考虑输入和输出长度不同的情况,例如机器翻译。首先读入这个句子。在输入结束时这个网络就会输出翻译的结果。因此整个网络分成了部分,首先是一个编码器,用于获取输入,第二部分是一个解码器,它会读取整个句子,然后输出翻译成其他语言的结果。
总结一下各种各样的RNN结构如下图;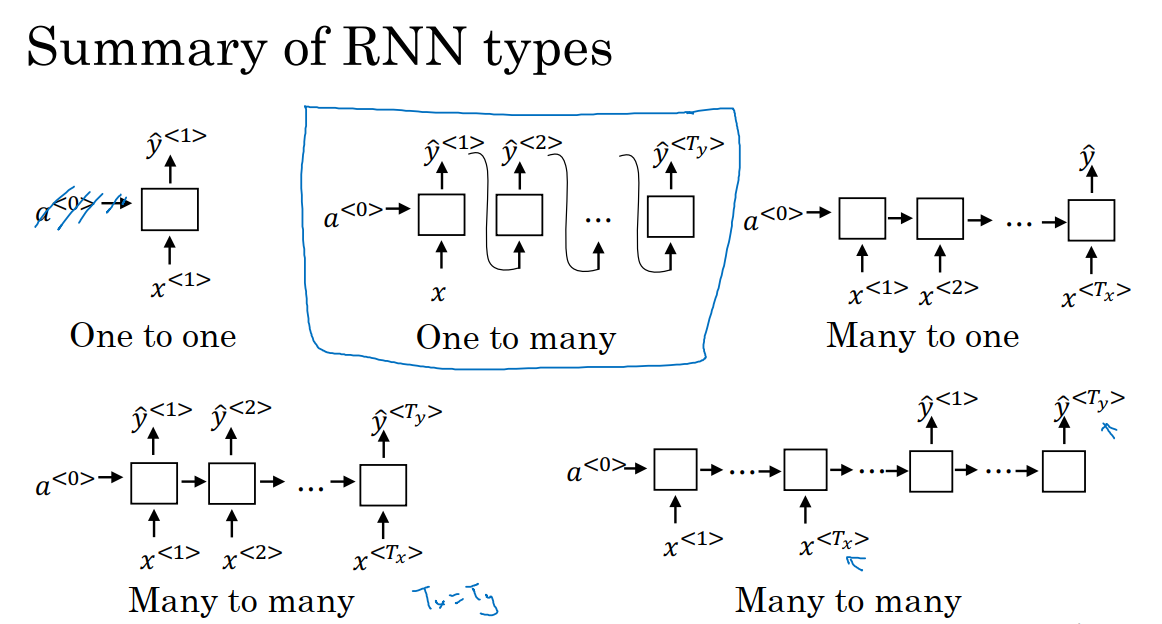
一对一:如果去掉了a^0,它就是一种标准类型的神经网络,不需要RNN。
一对多:用于音乐生成或者序列生成。
多对一:用于情感分类。
多对多:T_x=T_y,用于命名实体识别。
多对多:用于机器翻译,T_x不等于T_y。
5.5 语言模型和序列生成
5.5.1 语言模型的作用

我们在语音识别时可能会将语音输入识别为上图中两种可能的情况,然而此时我们应该想要表达的意思是第二种,一个好的语音识别系统能正确输出识别结果为第二种而不是第一种,即使这两句话听起来是如此相似。为了达到这一目的,我们需要使用一个语言模型,来计算这两句话各自的可能性,通过比较这两个概率值,来决定最终的输出结果。
语言识别模型的工作就是输出某个特定的句子出现的概率是多少,它是语音识别系统和机器翻译系统的重要组成部分,目的是正确输出最接近的句子。
5.5.2 建立一个语言模型
5.5.2.1 标记化

训练集:包含一个很大的英文文本语料库。语料库是自然语言处理的一个专有名词,在这里就是数量众多的英文句子组成的文本。
假如说我们训练集中有一句话,如上图,猫一天睡15个小时。我们要做的第一件事就是将句子标记化。就像是之前我们曾经提到过的一样,建立一个字典,然后对每一个单词使用one-hot编码。同时我们需要定义句子的结尾,一般的做法是增加一个额外的标记EOS,这样我们可以知道一个句子什么时候结束。因此我们需要对训练集中的每一个句子的结尾增加这个标记。如果按照这样的规则,我们可以得到9个标记,y^1,y^2,…y^9。在这个过程中,我们可以决定要不要把标点看成是标记。这里我们忽略了标记。
在上图中第三行的样本数据中,出现了不在我们字典中的一些单词。此时我们可以把Mau替换成一个UNK标记,代表未知词。我们只针对UNK建立概率模型,而不针对这个具体的词Mau。
5.5.2.2 构建RNN
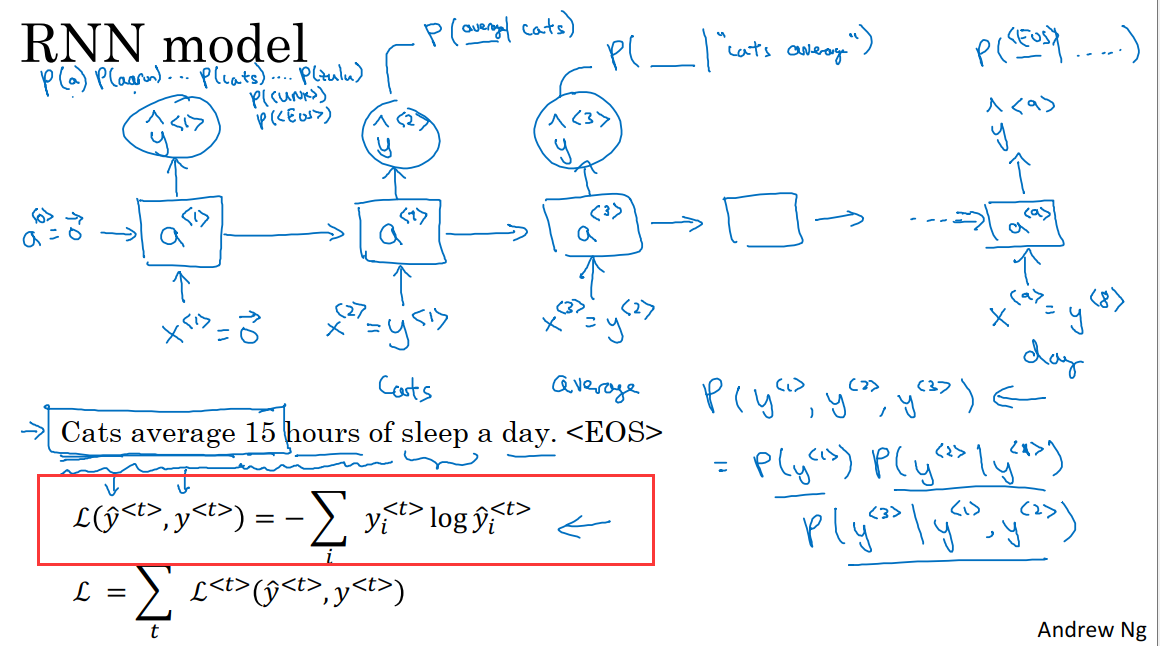
在这里,x^t=y^(t-1)。在第0个时间步,我们计算激活项a^1,它是由a^0和x^1共同决定的,a^0和x^1会被设为全0向量。然后a^1通过softmax预测第一个词可能是y_pre^1。这一步实际上就是通过softmax来预测字典中的任意单词会是第一个词的概率。例如第一个词是cats的概率是多少?所以softmax层可能输出10000+2种结果,这是因为字典中一共有10000个词,再加上句子结尾和UNK标志。
然后RNN进入下一个时间步,我们计算激活项a^2,它是由a^1和y^1(即在时间步0中正确的输出,在这里y^1=Cats),最终预测得到的第二个词会是y_pre^2。输出结果同样经过softmax层进行预测,RNN的工作就是预测这些词的概率,而不去管正确的结果是什么,它只会考虑之前的值y^1。
然后再进入到RNN的下一个时间步,它的输入是y^2=average,输出是y_pre^3,也就是字典中每一个词出现在这里的概率,通过之前得到的cats和average。
以此类推,最后停在第9个时间步,此时的输入为y^8=day,输出为y_pre^9,y^9=EOS,因此我们希望EOS标志能有很高的概率。
所以RNN中的每一个时间步,都会考虑前面得到的单词,比如给他前三个单词,让他给出下个词的分布。RNN的工作就是学习从左到右地预测一个词。
5.5.2.3 定义代价函数
在某一个时间步时,如果真正的词是y^t,softmax层预测的词是y_pre^t,那么softmax的损失函数定义如上图中红框部分。
而总体损失函数就是把所有单个预测的损失函数都相加起来。
如果我们用很大的训练集来训练这个RNN,我们就可以通过开头的一系列单词来预测之后的单词的概率。
现在有一个新的句子y^1,y^2,y^3,现在要计算出句子中各个单词的概率,方法就是第一个softmax层会输出p(y^1),然后第二个softmax层会输出在考虑y^1情况下的p(y^2),最后第三个softmax层会输出在考虑y^1和y^2情况下的p(y^3)。把这三个概率相乘,最后得到这个含3个单词的整个句子的概率。
5.6 新序列采样
在我们训练一个序列模型之后,要想了解这个模型学到了什么,一种非正式的方法就是进行一次新序列采样。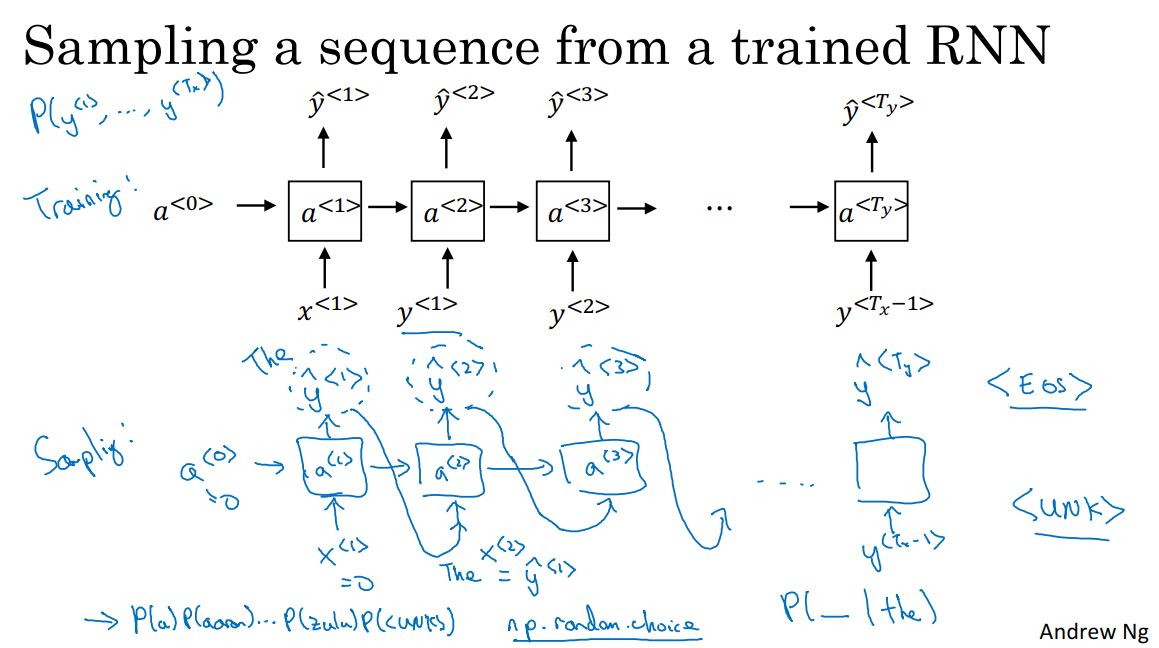
一个序列模型模拟了任意特定单词序列的概率,我们的工作就是对概率分布进行采样来生成一个新的单词序列。这个网络已经被上图所展示的结构训练过了。而为了进行采样,我们需要做的是:
1 对我们想要模型生成的第一个词进行采样。该时间步的输入为a^0=0和x^1=0。我们得到的是所有可能的输出经过softmax层后得到的概率。
2 根据这个softmax的分布进行随机采样。softmax分布给我们的信息就是第一个词是x的概率是p(x),x是词典中的每一个词。然后对这个y_pre向量使用numpy.random.choice,来根据向量中这些概率的分布进行采样。也就是根据p(x)选择最终输出的y_pre。
3 进入下一个时间步,第二个时间步的输入为y^1,注意在用于序列生成时,y^1=y_pre^1,然后softmax层就会预测y_pre^2。也就是说我们现在计算在第一个词是y^1的情况下,第二个词应该是什么?
4 进入到下一个时间步,用one-hot码表示y_pre^2选择的结果,并把它继续传递给下一个时间步。
5 表示句子的结束。如果EOS标志在字典中,我们可以一直进行采样直到得到EOS标志。另一种情况是,如果EOS标志不在字典中,我可以设定在固定的时间步结束。如果我们不希望生成的序列中有未知标志,那么我们可以设定当结果为未知标志时从剩余部分继续采样直到结果不是未知标志。
这就是RNN语言模型生成一个随机选择的句子的过程。
在上文中我们介绍的是基于单词的RNN,实际上我们也可以使用基于字符的RNN。在这种情况下,字典中仅包含从a到z的字母,可能还会有空格符,可能还会有0-9,还可以有大写字母。此时我的序列y^1,y^2,y^3,…在训练集中都将是单独的字符,而不是一个单词。
基于字符的RNN的优点是不用担心会出现UNK标识。它的缺点是我们最后会得到太多、太长的序列,大多数英语句子只有10到20个单词,但是却可能包含很多字符。所以基于字符的语言模型在捕捉句子中的依赖关系,也就是句子较前部分如何影响较后部分,不如基于单词的RNN那样可以捕捉长范围的关系。并且它的计算成本较高。
5.7 带有神经网络的梯度消失
5.7.1 梯度消失
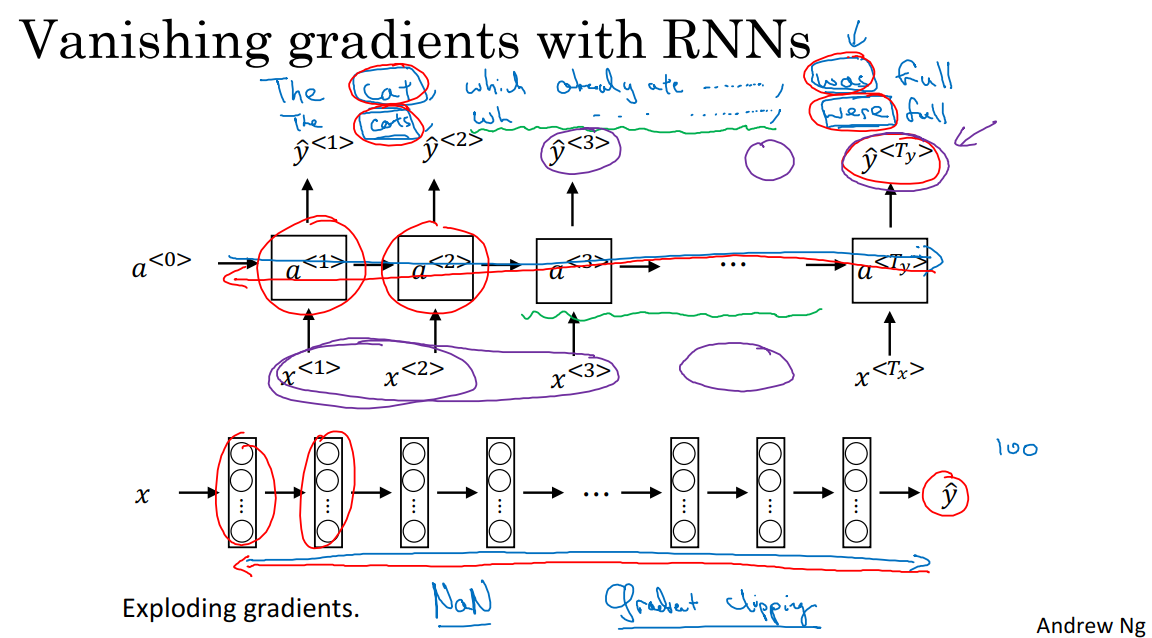
在上图中的句子,cat-was,cats-were,它们有非常长距离的依赖,最前面的单词对句子后面的单词有影响。但是我们此前见到的基本RNN模型,不擅长捕获这种长期以来。这是因为梯度消失,即一个很深的神经网络,在进行反向传播的时候,输出y的梯度很难传播回去,很难影响靠前层的权重。在RNN中,从左到右进行前向传播,从右到左进行反向传播,因为存在梯度消失问题,所以反向传播会很困难,后面层的输出误差很难影响前面层的计算。反映到这个问题上就是很难让一个神经网络记住看到的是单数名词还是负数名词,然后在序列后面生成对应的单复数形式。
RNN网络中会有很多局部影响。也就是输出y^3主要受y^3附近的值的影响,很难受到序列靠前的输入的影响。这是因为这个区域的误差很难反向传播到序列的前面部分,也因此网络很难调整序列前面位置的计算,这是RNN模型的主要问题所在,不擅长处理长期依赖问题。
5.7.2 梯度爆炸
梯度下降在训练RNN网络时是首要的问题。但也可能出现梯度爆炸。我们在进行反向传播时,随着层数的增多,梯度不仅可能指数型的下降,也可能指数型的上升。这是因为指数极大的梯度会让我们的参数变得极其大,以至于网路参数崩溃。所以梯度爆炸很容易发现,会出现NAN的结果。
我们解决梯度爆炸的一个方法就是梯度修剪。观察我们的梯度向量,如果它大于某个阈值,就需要缩放梯度向量,保证它不会太大。
5.8 GRU单元(门控循环单元)
GRU单元改变了RNN的隐藏层,使其可以更好地捕捉深层连接,并改善了梯度消失问题。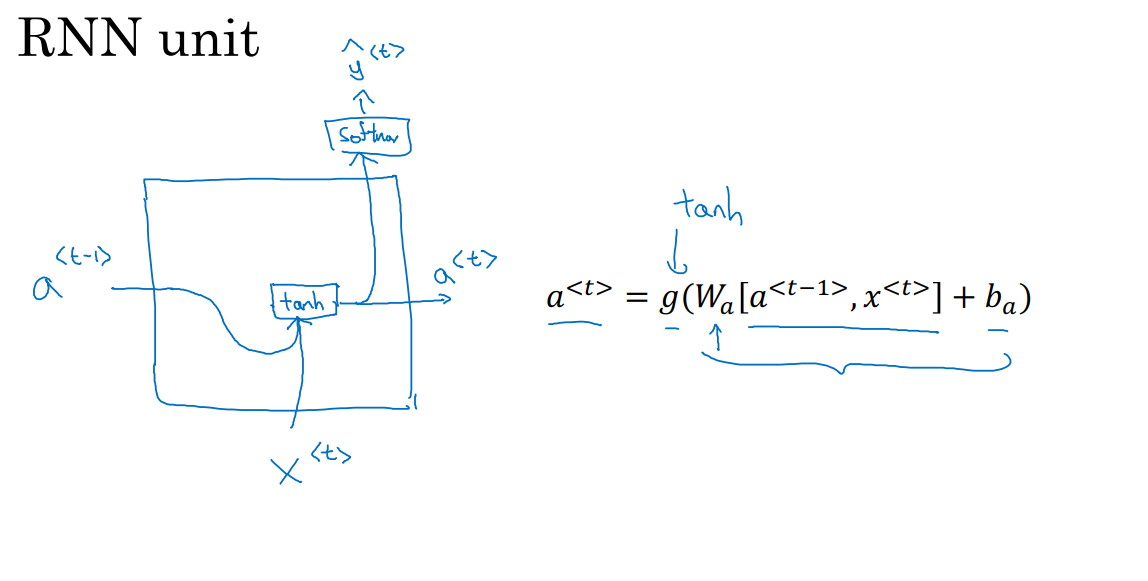
上图中,我们在5.2部分已经得到了这个公式,用于计算RNN的激活值,时间步t的激活值a^t等于W_a乘上时间步t-1的激活值和输入x^t,再加上偏差项。
我们把RNN的单元画一个图,输入是时间步t-1的激活值a^(t-1)和x^t,然后把这两项加上权重项计算,如果g是一个tanh激活函数,则在经过tanh计算之后,RNN单元会输出激活值a^t,同时将a^t传递给softmax层产生输出y_pre^t。这就是RNN隐藏层的单元的可视化呈现,如上图。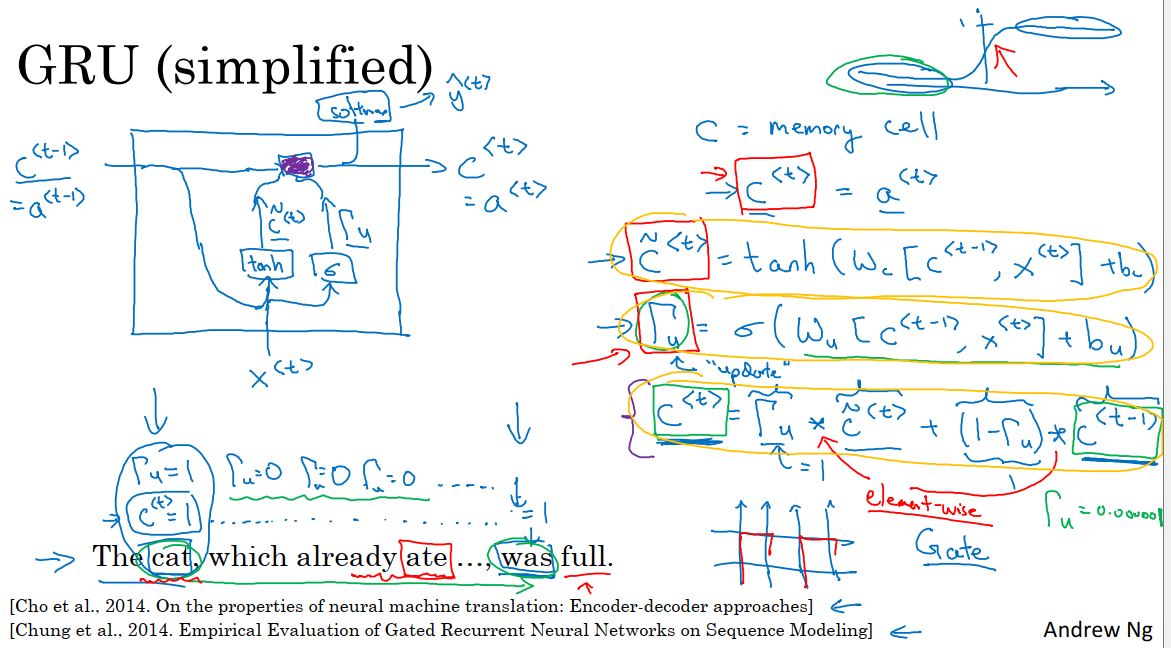
当我们从左到右读入这个句子,GRU单元有一个新的变量c代表细胞,即记忆细胞。记忆细胞的作用是提供记忆的能力,比如说cat是单数还是复数。
5.8.1 初始化c^t
在时间步t,c^t=a^t,即使这两个值相同,我们也需要使用两个符号来表示,因为在后面LSTM中,这两个符号代表的是不同的值。
5.8.2 计算c^t候选值c_pre^t
在每一个时间步,我们将会用一个候选值重写记忆细胞,即c_pre^t的值,它就是一个候选值,代替了c^t的值。然后我们用tanh激活函数来计算W_c,具体如下式:
即上一个记忆细胞的值和目前的输入x^t。
5.8.3 确定门
在GRU中真正重要的思想是,我们有一个门Γu,u代表更新门,Γu表示一个0到1之间的值,它的具体计算方式是
回忆sigmoid的函数图像,它的输出值总是在0到1之间。对于大多数可能的输入,sigmoid函数的输出值总是非常接近0或者非常接近1,那么Γ的取值也是大多数情况下非常接近0或1。
我们用c_pre来确定更新c的候选值,然后用门来决定是否要真的用这个候选值来更新c。
在这里,我们可以这样理解。记忆细胞c将被设定为0或1,这取决于我们考虑的单词在句子中是单数还是复数。在这里cat是单数情况,所以我们先假定c被设为了1,那么复数情况就会被设为0。然后GRU单元将会一直记住c^t的值,直到was的位置,因为记忆细胞告诉网络这里是单数,所以我们用was。
门的作用是决定我们什么时候更新c^t的值。例如当我们看到cat,这就是一个更新这个bit的好时机。然后当我们使用这个bit的时候,我们就可以更新bit的内容了,因为它已经发挥过作用了。
5.8.4 更新c^t
c^t的更新方法如下:
即如果Γu=1,那么就是把c^t更新为候选值c_pre^t。在这个例子中,cat位置的Γu=1,证明应该更新c^t。在cat和was之间的位置,Γu=0,意识是不要去更新c^t的值,将当前时间步的c的值设置为上一时间步c的值。于是网络就会一直记得cat这里是单数。
5.8.5 过程绘图
GRU单元输入c^(t-1),我们可以先假设c^(t-1)=a^(t-1),表示t-1时间步记忆细胞的激活值就是它要记忆的值。
GRU单元输入x^t。
把这两个输入用合适权重结合在一起,再用tanh计算出c_pre^t,也就是c^t的候选值。
两个输入以合适的权重通过sigmoid激活函数,计算Γ_u,即更新门。
通过Γ_u的值决定是否要用候选值来更新c^t。最终GRU单元输出a^t=c^t。表示记忆细胞的激活值就是它要记忆的值。同时a^t输入到softmax层可以用于预测y_pre^t的取值。
GRU的优点是通过门决定当我们从左到右扫描一个句子的时候,某一时刻是否需要更新记忆细胞。Γ_u很容易就能取到0,那么我们的更细就是c^t=c^(t-1),这非常有利于维持细胞的值。因为Γu很接近0,也避免了梯度消失的问题(就是y_pre的值只受到附近的值的影响,而没有办法解决长距离依赖问题)。即使经过很多的时间步,c^t的内容也会很好的维持。
c^t可以是一个向量。如果我们有100维的隐藏项的激活值,那么c^t也是100维的,c_pre^t也是相同的维度,Γu也是相同的维度。这样更新式中的×表示的是元素对应的乘积。如果Γu是一个100维的向量,那么里面的值几乎都是0或1,但在实际中可能也会有0到1之间的值。这个100维的记忆细胞就是我们每次更新的目标。门的功能就是告诉GRU单元哪个记忆细胞的向量维度在当前时间步需要更新。所以我们可以选择保持一些比特不变,而去更新其他的比特。
例如我们可能需要一个比特来记忆cat是单数还是复数,其他比特来理解另外的内容。
5.8.6 完整的GRU单元
在上图中我们展示的只是经过简化的GRU单元,下面我们来讨论完整的GRU单元。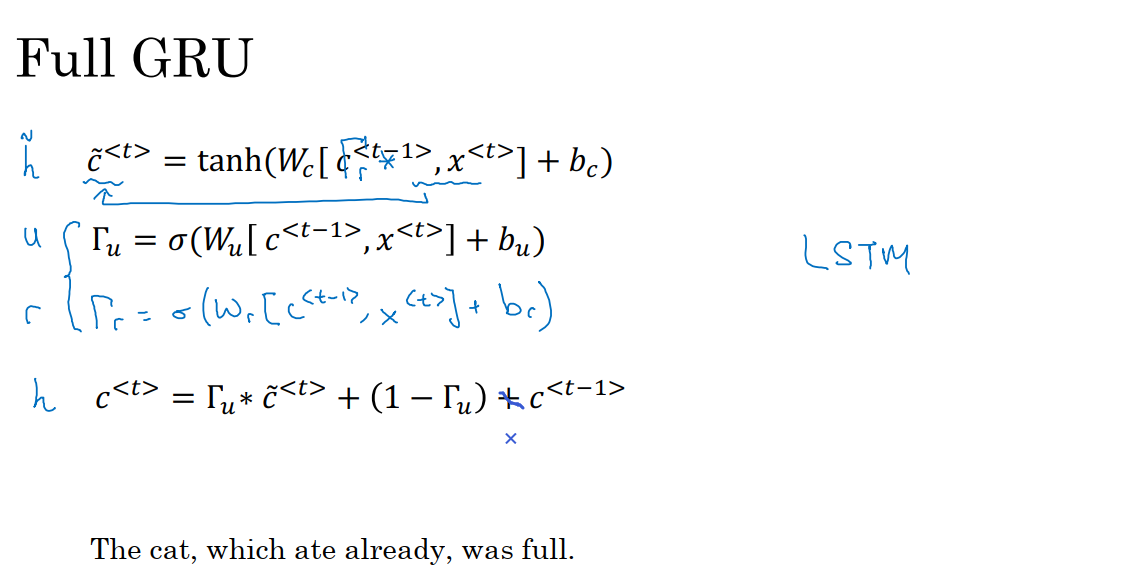
在我们计算的第一个式子中,给记忆细胞计算候选值,我们需要在c^(t-1)的前面增加一个门Γr,r代表相关性,Γr表示下一个c^t的候选值c_pre^t与c^(t-1)的相关性大小。Γr的计算方式如下:
另一种捕捉长范围依赖,解决梯度消失的解决方案是LSTM。
5.9 长短期记忆 LSTM

上图中的左边部分是我们在5.8GRU部分得到的式子,在GRU中,我们有a^t=c^t,还有两个门,更新门和相关门。c_pre^t是记忆细胞的候选值,然后我们使用更新门Γu来决定是否要用候选值c_pre^t来更新c^t。
5.9.1 c_pre^t计算
LSTM是比GRU更强大和通用的版本,我们先了解记忆细胞。c_pre^t的计算方式如下:
我们不再有a^t=c^t的情况,我们计算c_pre^t使用的是a^(t-1),而不是c^(t-1),我们也不用Γr。
5.9.2 更新门Γu和遗忘门Γf
像以前那样我们有一个更新门Γu,具体计算方式如下:
LSTM的一个特性就是不只有一个更新门控制c^t的更新(具体来说是c^t在更新时候选值的权值和c^(t-1)的权值),即我们使用不同的门来取代左边式子中的Γu和1-Γu。我们将更新门作为候选值的权值,而c^(t-1)的权值为遗忘门Γf的输出,它的计算方式为:
则c^t的计算方式为:
如果是矩阵,则×表示对应位置的元素乘积。这给了记忆细胞选择权去维持旧的值c^(t-1)或者就加上新的值c_pre^t。所以这里用了单独的更新门和遗忘门。
5.9.3 输出门Γo
然后我们还有输出门Γo:
因此该时间步的激活值a^t的计算方式为
5.9.4 过程绘图
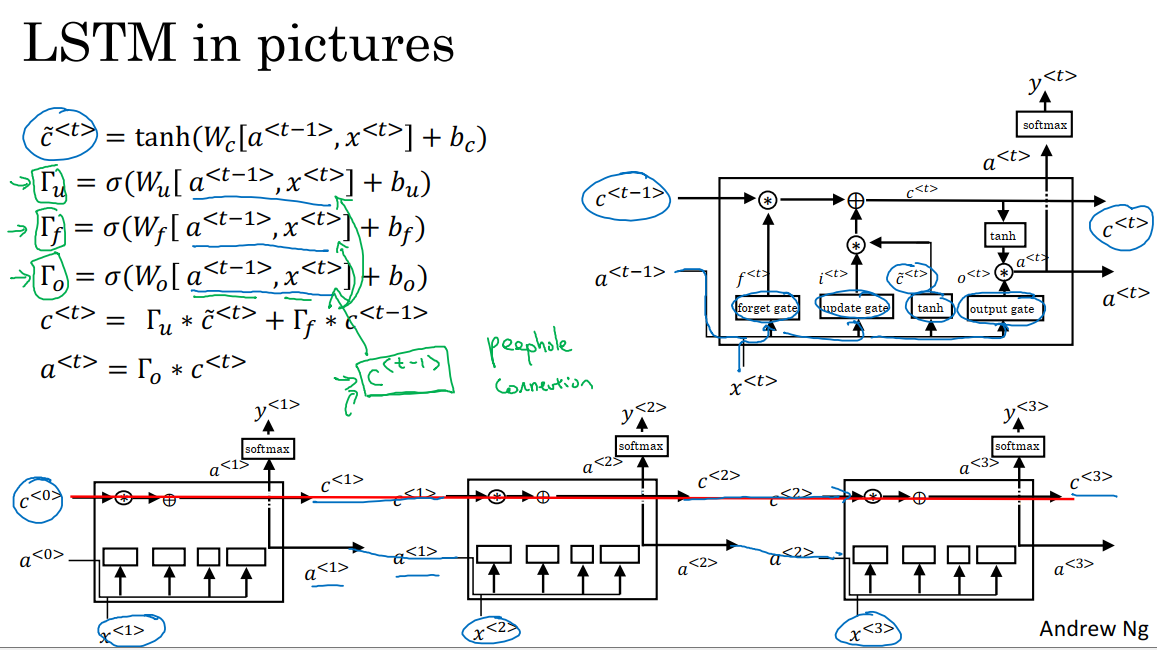
上图中,我们用a^(t-1),x^t计算了所有门值,从左到右依次是遗忘门、更新门和输出门。
同时a^(t-1),x^t也经过了tanh来计算y_pre^t。这些门值和c^(t-1)、c_pre^t一起决定了c^t。
然后我们将这些单元连接起来,我们发现红线位置只要我们正确地设置了遗忘门和更新门,LSTM很容易把c_pre^0的值一直向下一个时间步传递直到最右边,也就是c^3=c^0,这表明它非常擅长于长时间记忆某个值。最常用的LSTM版本门值不仅取决于a^(t-1)和x^t,有时也会参考一下c^(t-1)的值,这叫做窥视孔连接。
LSTM的主要区别在于这个技术细节:比如c是100维的记忆细胞单元,第50个c^(t-1)的元素,只会影响第50个元素对应的那三个门,所以对应关系是一对一的,c^(t-1)不可能影响所有的门元素。
GRU的优点是它是一个更加简单的模型,所以更容易创建一个更大的网络。而且它只有两个门,在计算性能上,也运行得更快。使用GRU我们可以扩大模型的规模。
LSTM比GRU更为强大和灵活,因为它有3个门。
5.10 双向神经网络
双向RNN模型可以让我们在序列的某点处不仅可以获取之前的信息,还可以获取未来的信息。
深层RNN模型也可以帮助我们解决更复杂的问题。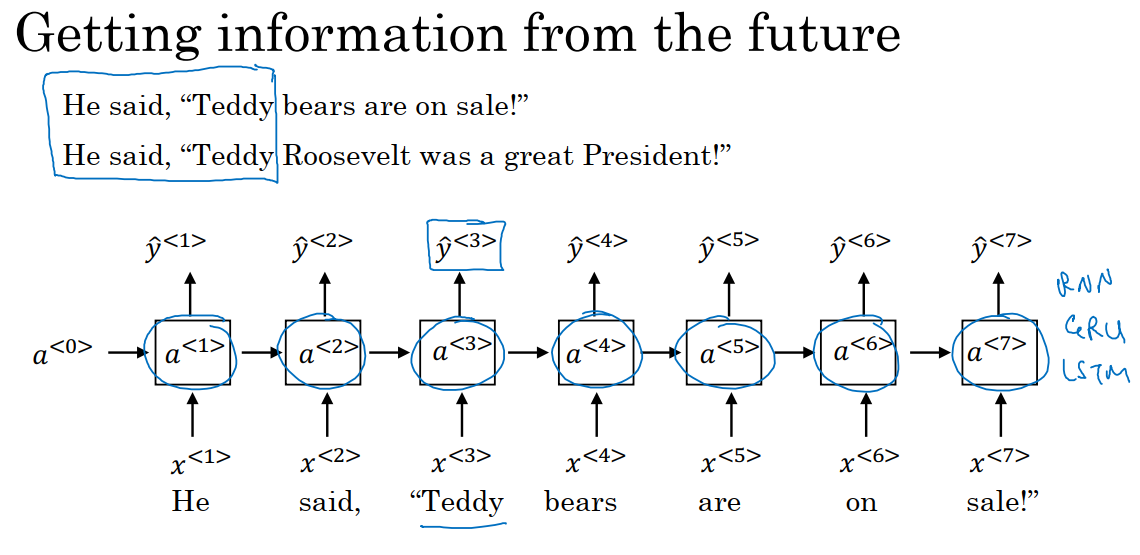
在上图中,我们判断Teddy是不是人名的一部分时,光看句子的前面部分是不够的。为了判断y_pre^3是0还是1,除了前3个单词,我们还需要更多信息。因为根据前3个单词无法判断这句话在谈论的是Teddy熊还是前美国总统。
上图中的网络是一个单向的RNN网络,这些单元可以是标准的RNN块、GRU单元、LSTM单元。单向网络的特点是都是前向的。那么一个双向的RNN,是如何工作的呢?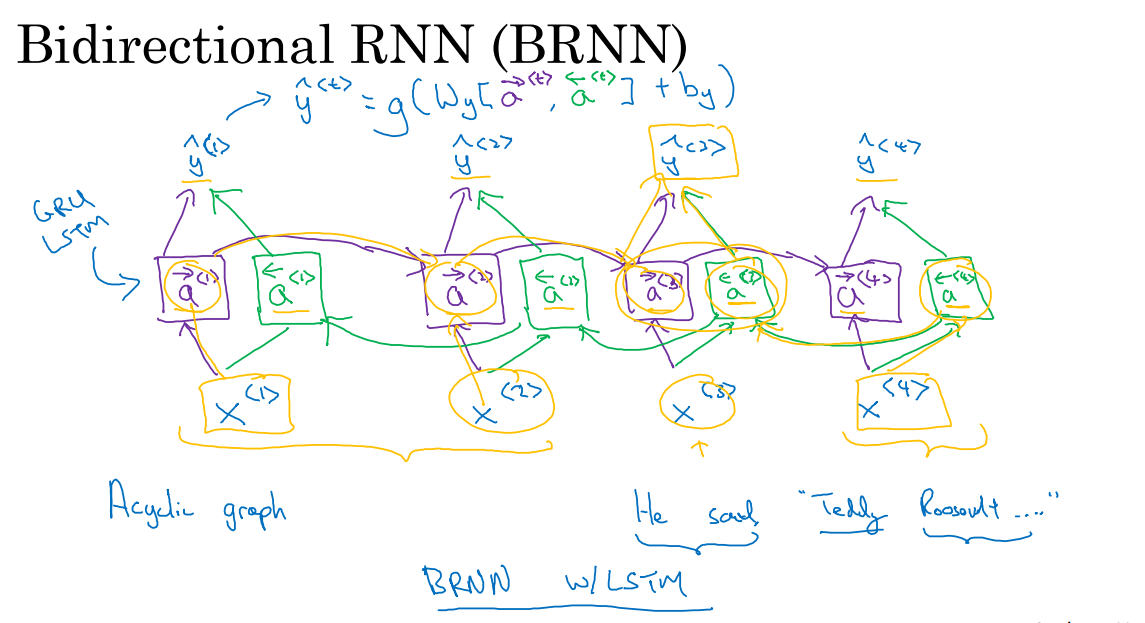
上图展示的双向RNN的工作原理。我们的输入是一个只有四个单词的句子。首先这个网络有一个前向(从左到右)的循环单元,它们都有一个当前输入x,输出预测y_pre^t。
然后我们增加一个反向循环层(从右到左),同样有一个当前输入x,输出预测。
这样网络就构成了一个无环图,给定一个输入序列x^1,…x^4,网络进行前向传播。这个序列首先计算前向a^1,a^2,…,a^4。而反向序列从计算a^4开始,反向进行,计算a^3直到a^1,这里也属于是神经网络的前向传播部分。
在计算完正向和反向的激活值之后,网络就可以计算预测结果了。y_pre的计算方式如下:
此时如果要预测y_pre^3,则在正向循环中,x^1,x^2,x^3的信息都会考虑在内,在反向循环中,x^4的信息也会考虑在内。
双向RNN网络的缺点是我们需要完整的数据序列才能完成预测。
5.11 深层循环神经网络
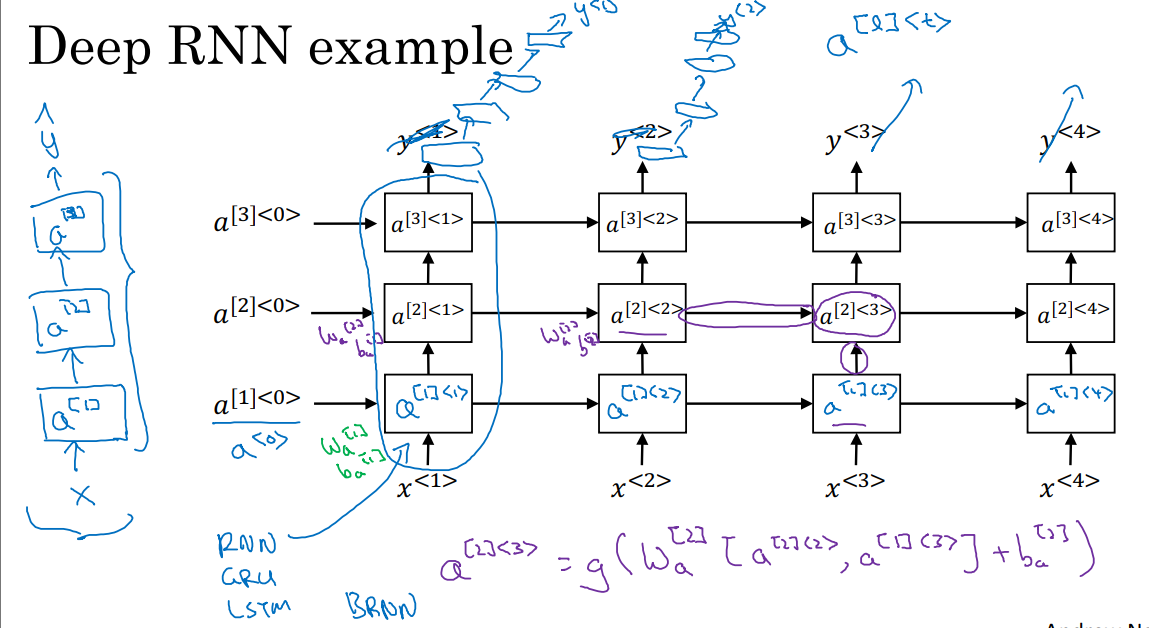
在深层RNN网络中,我们在每一个时间步中堆叠多个隐藏层。如上图,我们对激活值a的索引上增加了所在层的信息。对于a(2,3)单元来说,他有两个输入,一个是从下面过来的输入,还有一个从左边过来的输入。计算a(2,3)的时候用激活函数作用于权重矩阵,如下:
Wa^2和ba^2在第二层的计算中都是相同的值。对于RNN网络来说,深度为3的网络就相当大了。但是我们可以将第三层后的输出去掉,直接在后面接上一个标准神经网络用于预测y_pre,而不再进行水平连接。
6 textRNN实现
参考博客1
参考博客2
参考视频
问题背景:参考论文 Finding Structure in Time。我们有n句话,每句话都由且仅由3个单词组成。我们的工作是将前两个单词作为输入,最后一个单词作为输出,训练一个RNN模型。
6.1 导库
1 | # 导库 |
6.2 准备数据集
1 | # 准备数据集 |
6.3 预处理数据
n_step参数解释:
TextRNN参数:
1 | # 预处理数据,构建Dataset,定义DataLoader,输入数据one-hot编码 |
划分输入数据和标签:
1 | def make_data(sentences): |
数据集封装:
1 | input_batch,target_batch = make_data(sentences) |
6.4 构建网络结构
out和ht在RNN网络中的对应关系: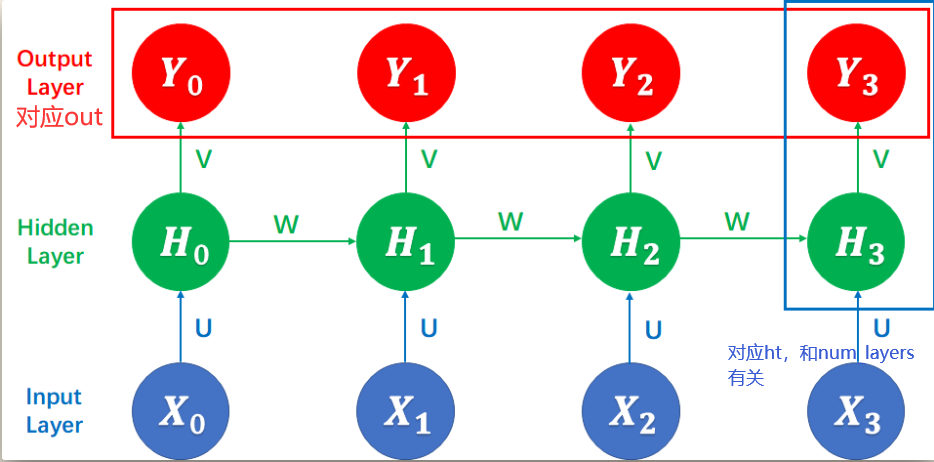
nn.CrossEntropyLoss()讲解交叉熵损失就是把log_softmax和nll_loss结合起来。
Adam方法参数:
1 params (iterable) – 待优化参数的iterable或者是定义了参数组的dict。
2 lr (float, 可选) – 学习率(默认:1e-3)。
3 betas (Tuple[float, float], 可选) – 用于计算梯度以及梯度平方的运行平均值的系数(默认:0.9,0.999)。该超参数在稀疏梯度(如在 NLP 或计算机视觉任务中)中应该设置为接近 1 的数。
4 eps (float, 可选) – 为了增加数值计算的稳定性而加到分母里的项(默认:1e-8)。其为了防止在实现中除以零。
5 weight_decay (float, 可选) – 权重衰减(L2惩罚)(默认: 0)
1 | # 构建网络结构 |
6.5 模型训练
Epoch,Batch Size和Iteration的区别:
举个例子:将10kg的面粉使用面条加工机(每次只能处理2kg),加工成10kg的面条。首先得把10kg面粉分成5份2kg的面粉,然后放入机器加工,经过5次,可以将这10kg面粉首次加工成面条,但是现在的面条肯定不好吃,因为不劲道,于是把10kg面条又放进机器再加工一遍,还是每次只处理2kg,处理5次,现在感觉还行,但是不够完美;于是又重复了一遍:将10kg上次加工好的面条又放进机器,每次2kg,加工5次,最终成型了,完美了,结束了。那么到底重复加工几次呢?只有有经验的师傅才知道。这就形象地说明:Epoch就是10斤面粉被加工的次数(上面的3次);Batch Size就是每份的数量(上面的2kg),Iteration就是将10kg面粉加工完一次所使用的循环次数(上面的5次)。显然 1个epoch = BatchSize * Iteration。
hidden就是伪激活值h0(也就是吴恩达理论课程中的a^0),全0向量。
1 | # 训练 |
输出为:
Epoch: 1000 cost = 0.056945
Epoch: 1000 cost = 0.066035
Epoch: 2000 cost = 0.010118
Epoch: 2000 cost = 0.010668
Epoch: 3000 cost = 0.002922
Epoch: 3000 cost = 0.003213
Epoch: 4000 cost = 0.000966
Epoch: 4000 cost = 0.001142
Epoch: 5000 cost = 0.000349
Epoch: 5000 cost = 0.000402
测试代码:
1 | # 测试 |
7 TextCNN实现
RNN网络有一个问题就是没有办法并行,因为时间步之间还会有水平信息传递,而CNN网络的优势在于没有时间维度的限制。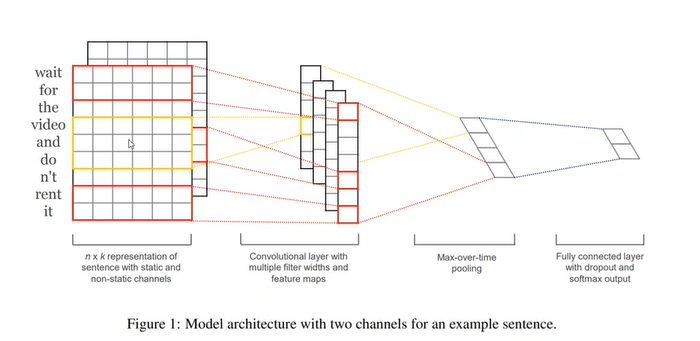
如上图,一个含有9个词的句子,被转换成9*6的矩阵,即每个词用6维的向量编码。
第一个卷积核位于图中红框处,为6*2,它的宽度设置为2的好处是同时覆盖了wait和for两个词的向量。如果步长stride(偏移量,即一个大方块和一个小方块卷积的时候,小方块每次移动的量)为1的话,那么下一次卷积核覆盖的是for和the两个词的向量。在文本处理中,同时考虑一个词的上下文是很重要的一点。由上图可以看出,这里使用了四个不同尺寸的卷积核。
参考原理
参考实现
参考视频
我们的代码是实现对一个句子的情感进行二分类。
7.1 导库
1 | import torch |
7.2 数据集处理和参数设定
定义数据集:
1 | # 定义数据集 |
textCNN参数:
1 | # TextCNN参数 |
封装数据集:
1 | # 构建dataset,定义dataloader |
7.3 构建模型
embedding编码如下图所示: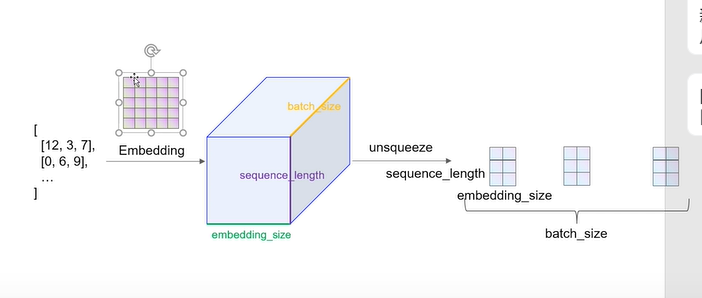
最终黄色边为样本数据的数目,紫色是一个样本数据中的单词个数,绿色是一个单词被编码的长度。
下面详细介绍一下数据在网络中流动的过程中维度的变化。输入数据是个矩阵,矩阵维度为 [batch_size, seqence_length],输入矩阵的数字代表的是某个词在整个词库中的索引(下标)。
首先通过 Embedding 层,也就是查表,将每个索引转为一个向量,比方说 12 可能会变成 [0.3,0.6,0.12,…],因此整个数据无形中就增加了一个维度,变成了 [batch_size, sequence_length, embedding_size]。
之后使用 unsqueeze(1) 函数使数据增加一个维度,变成 [batch_size, 1, sequence_length, embedding_size]。现在的数据才能做卷积,因为在传统 CNN 中,输入数据就应该是 [batch_size, in_channel, height, width] 这种维度。
[batch_size, 1, 3, 2] 的输入数据通过 nn.Conv2d(1, 3, (2, 2)) 的卷积之后,得到的就是 [batch_size, 3, 2, 1] 的数据,由于经过 ReLU 激活函数是不改变维度的,所以就没画出来。最后经过一个 nn.MaxPool2d((2, 1)) 池化,得到的数据维度就是 [batch_size, 3, 1, 1]。图示过程如下: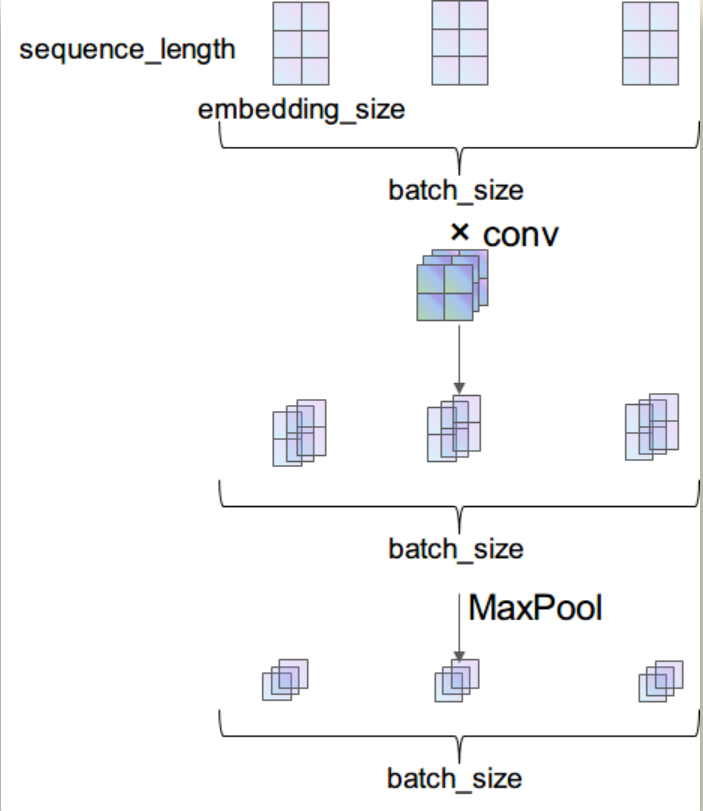
需要注意经过卷积后的尺寸计算公式:
1 | # 构建模型 |
7.4 模型训练
模型训练:
1 | model = TextCNN().to(device) |
model.train()的意思并不是把模型设置为训练模式才能开始训练。只对一些特定的层有用,
并不一定需要写。
model.eval()的意思并不是把模型设置为eval状态才能开始测试。只对一些特定的层有用,
并不一定需要写。
模型测试:
1 | # 模型测试 |
如果要实现使用不同的大小的卷积核,那么需要init部分定义一个卷积层的list,然后在forward卷积部分加上一个for循环。
8 TextLSTM实现
基本LSTM简介
pytorch中LSTM接口
LSTM实现文本分类
以简单数据集和网络结构实现TextLSTM,训练集中包括10个单词,用每个单词的前三个字符去预测最后一个字符,目的是便于读者更好的理解该网络的原理。
8.1 导库和设置数据类型
1 | import torch |
8.2 数据集处理和模型参数
1 | # 准备数据集 |
8.3 建立网络
1 | class TextLSTM(nn.Module): |
8.4 模型训练和验证
1 | # 训练 |
9 BiLSTM实现
pytorch实现
参考讲解
我们的目的是使用一句话作为训练集训练模型,使得它可以预测某个长句子的下一个单词是什么。
9.1 导库
1 | import torch |
9.2 准备数据&模型参数设置
1 | # 准备数据 |
9.3 建立网络
1 | # 建立网络 |
9.4 训练&测试
1 | # 训练 |
输出的第i位的target是sentences的第i+1位。
10 注意力模型
10.1 注意力模型直观理解
注意力模型或者说注意力这种思想,是深度学习中最重要的思想之一。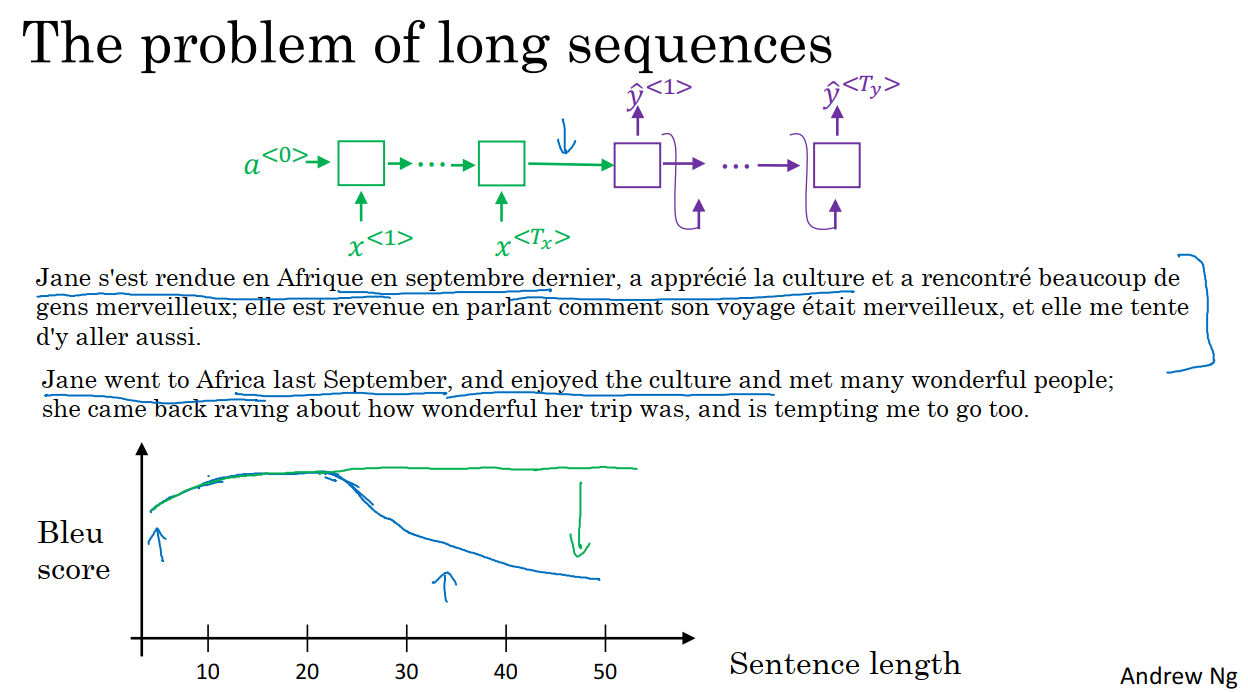
上图中给定一个很长的法语句子,在我们的神经网络中,这个绿色的编码器要做的就是读整个句子,然后记忆整个句子,再在感知机中传递。而对于图中紫色的神经网络,即解码网络,将生成英文翻译。
人工翻译并不会通过读整个法语句子,再记忆里面的东西,然后从零开始,机械式的翻译成一个英语句子。人工翻译首先做的可能是先翻译出句子的一部分,再看下一部分并翻译这一部分,这样不断重复。因为记忆整个长句子是非常困难的。
在编码解码结构中,它对于短句子的效果会非常好,会有一个相对高的布鲁分;但对于长句子而言,比如大于30或者40词的句子,它的表现就会变差。
注意力模型模仿人类翻译句子的过程,一次翻译句子的一部分。有了注意力模型,机器翻译系统的表现变成了绿色的曲线,随着句子的边长,布鲁分不会有巨大的下降,也就是神经网络记忆长句子的能力并不会下降。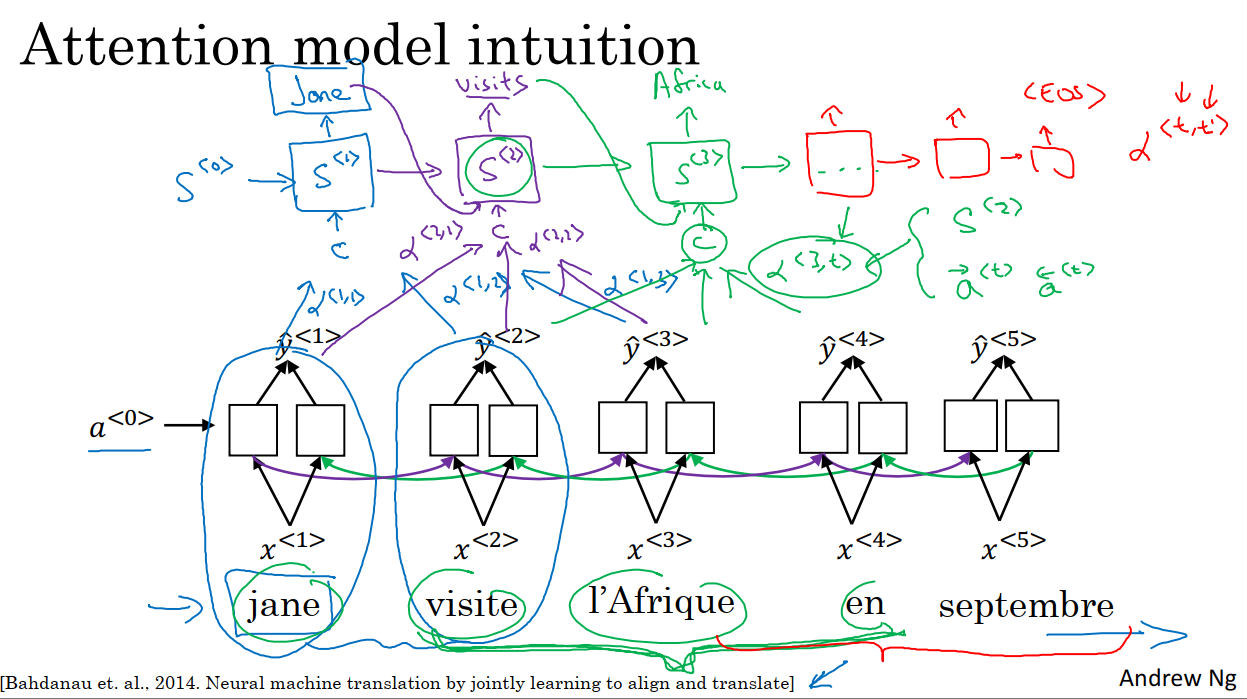
注意力模型最早应用于机器翻译领域,现在已经推广到了其他应用领域。如上图,我们以短句子的处理为例说明注意力模型的思想。input句子是法语的,假定我们使用双向BiRNN来计算input的特征集,并使用另外一个RNN网络来将这些特征集翻译成英语。
用于翻译英语的EN-RNN网络的激活值是S^i,我们希望在这个模型中第一个生成的单词会是Jane。现在的问题就是当我们尝试生成第一个词Jane时,我们应该看输入的input句子的哪个部分?
似乎我们应该看input的第一个单词,或者它附近的词。但我们不能看的太远,比如看到句尾去。所以注意力模型就会计算注意力权重,我们使用α^(1,1)来表示当我们生成第一个词时,我们应该放多少注意力在第一块信息处(即BiRNN的第一个时间步),然后我们计算第一个单词中BiRNN第二个时间步的注意力权重α^(1,2),当我们尝试去计算第一个词Jane时,我们应该放多少注意力在input的第二个词上面。同理有α^(1,3)…这些注意力权重会告诉我们应该花多少注意力在每个输入单词上面,我们将这些特征和对应的注意力权重输入到EN-RNN单元中,然后再生成第一个词Jane。
对于EN-RNN的第二个时间步,我们将有一个新的隐藏状态S^2:
1 我们也会有一个新的注意力权重集,α^(2,1)表示我们在生成第二词时要花费多少注意力在input的第一个词,同理其他的由input计算得到的特征也会根据对应的注意力权重输入到该RNN单元中。
2 在第一个时间步中生成的词Jane也会输入到第二个时间步的RNN单元中。
经过计算,我们生成了第二个词visits。
接下来我们来到了EN-RNN的第三个时间步,它和第二个时间步的计算过程大致相同。我们是否需要花费注意力在BiRNN的第t个时间步的输出特征上,这取决于在该时间步的BiRNN的激活值(两个,前向和后向)和EN-RNN上一时间步的激活值。例如α^(3,t)取决于S^2和a前^t、a后^t。
然后随着EN-RNN时间步的增加,我们每一个时间步都生成一个词,直到最终生成EOS。
注意力权重α^(t,t)的意义在于当EN-RNN在生成第t个输出时,应该花费多少注意力在input的第t个输入上。这帮助EN-RNN在生成输出时很好地考虑到了周围的输入信息。
10.2 注意力模型
在上一部分我们了解了注意力模型如何让一个神经网络只注意到一部分地输入句子,下面我们详细说明下计算过程。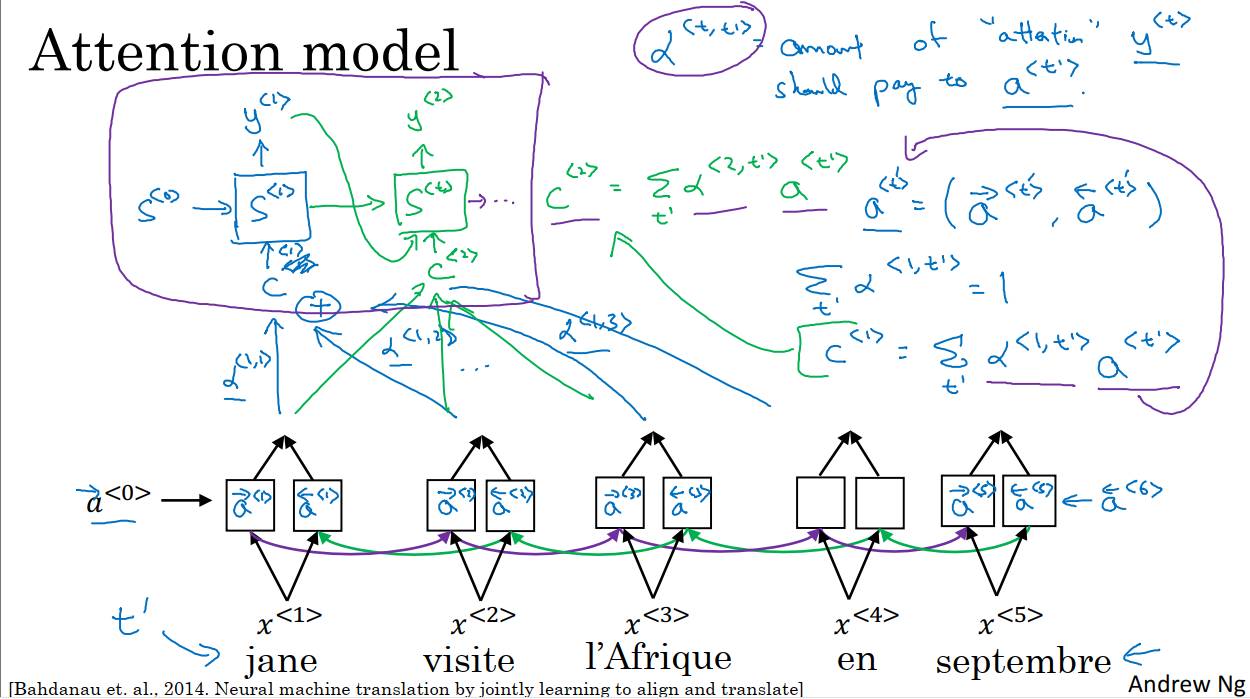
如上图,我们使用了和上一节相同的输入和网络结构,我们使用BiRNN来计算每个输入词的特征,LSTM可能使用的更多。对于BiRNN的每个时间步,我们有前向的激活值和后向的激活值。位于最左边和最右边的伪激活值都是0向量。为了便于后续使用,我们把BiRNN每个时间步的两个激活值统一表示为a^t,特别的,我们使用t’来索引input句子中的词。
然后我们用于输出英语的EN-RNN网络是一个单向的RNN,用S^t来表示激活值,y^1表示在时间步1的输出。我们用C来表示输入EN-RNN某个时间步的上下文信息,C的取值和注意力参数alpha^(t,t’)的大小有关,同时α参数也量化了C对于我们从输入得到的特征的依赖程度。
我们定义上下文的方式实际上来源于来自不同时间步的一些特征,再考虑这些特征对应的注意力权重。总之,注意力权重是一个非负的值,并且权重和为1,在下文中我们将会说明如何满足这个条件。
例如,在EN-RNN时间步1,注意力权重需要满足的条件是:
在EN-RNN时间步1,上下文C^1的计算方式为:
其中a^t’表示的是Bi-RNN网络中时间步t’时的前向激活值和后向激活值。所以α^(t,t’)就是y^t应该在t’时花在a^t’上的注意力数量。也就是在EN-RNN时间步t时刻生成词时,对Bi-RNN时间步t’的注意力时多少。
在EN-RNN下一个时间步2,我们会有一个新的注意力权重集,继续计算C^2,并且考虑上一步的输出,然后生成第二个输出。
接下来我们需要定义注意力权重的计算方式。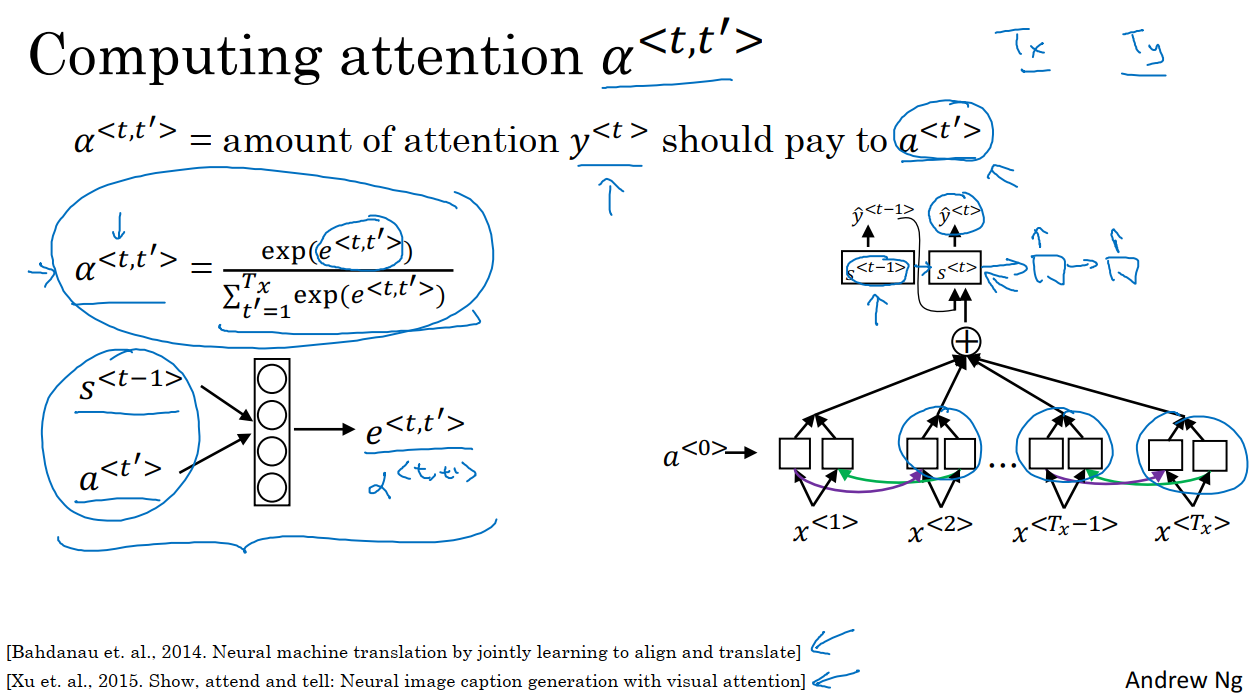
我们知道,α^(t,t’)就是y^t应该在t’时花在a^t’上的注意力数量。如上图,它的算法方式为:
计算α^(t,t’)的关键是用softmax来保证对于每一个固定的t,在对t’求和时,和为1。
在计算α^(t,t’)之前,我们需要计算e^(t,t’),我们可以使用上图中左边小的神经网络来计算e。输入一是EN-RNN网络t-1时间步的状态(也是激活值)S^(t-1),输入二是BiRNN网络t’时间步的状态a^t’。直观来说就是如果我们要决定花多少注意力在t’的激活值上,它很大程度上取决于EN-RNN网络上一时间步的激活值(我们还无法计算出当前时间步的激活值)和每一个词t’的特征值。但是我们不知道具体的参数是多少,于是我们选择使用一个小的神经网络来学习这个参数。这个小的神经网络告诉我们应该花费多少注意力在a^t’上。然后我们使用softmax来确保注意力权重和为1。
这个算法的缺点是他的复杂度是O(n^2)。如果我们有Tx个输入单词,Ty个输出单词,于是注意力参数的总数就会是Tx*Ty,所以空间复杂度为O(n^2)。
可视化注意力权重十分有趣。对应的输入输出词的注意力权重,会比其他的高。这表明网络在生成特定的输出词时,通常会花注意力在恰当的输入词上面。
10.3 Transformer网络直觉
深度学习领域中最令人兴奋的成就之一就是Transformer网络。Transformer是一种在nlp(自然语言处理)领域十分重要的网络架构。它是一种相对复杂的神经网络架构。
随着序列任务复杂性的增加,模型的复杂性也会随之增加。RNN:由于RNN存在梯度消失问题,因此RNN很难捕捉到远距离依赖,于是我们研究了循环门控单元(GRU)和长短期记忆(LSTM)模型,用于解决这类问题。在这些模型中,我们使用门来控制信息流,因此每个单元都需要相当多的计算。他们改进了RNN的缺点,但是同时也增加了复杂性。因此当我们从RNN到GRU,再到LSTM,模型变得越来越复杂。
所有这些模型都是序列模型,以为它们接受输入数据,这些输入数据或许是一个句子、一个单词或一个标记。因此每个单元就像是信息流的一个瓶颈,因为只有先算出前面所有单元的输出数据,才能得出最后单元的输出数据。transformer架构的目的是为了在序列中进行更多的并行计算。所以,我们可以在同一时间内对一个完整的句子进行处理,而不是从左到右逐词进行处理。transformer架构的主要创新在于把基于注意力的模型与卷积神经网络CNN的处理方式结合起来。
由于RNN一次只能处理一个输出数据,我们要先得出y^1,再把y^1输出到RNN第二个时间步中,得到y^2,然后以此类推。而CNN可以一次性接受大量像素,也就是可以对许多词进行并行计算处理。
注意力网络是一种可以对大量有用词汇进行计算处理的方法。不过在某种程度上,它类似于这种CNN模型进行并行处理。
我们需要了解自注意力机制。假如一个句子有5个单词,自注意力机制的目的就是最终计算出这五个单词的五个表达A^1,A^2,A^3,A^4,A^5,这就是并行计算注意力模型中所有单词表达的方法。。
我们需要了解多头注意力机制,可以理解为自注意力机制的处理过程的循环。所以最终得到多个版本的表达。事实证明,这些丰富的表达,可以有效地用于机器翻译或其他NLP领域。
10.4 自注意力机制

在前面部分我们了解了注意力机制与RNN一起工作地情况,为了将注意力与卷积神经网络结合起来,我们需要计算自注意力,基于我们对于输入句子的每一个单词创建的基于注意力的表述。我们使用上图中的例子来说明。
我们的目的是为每一个单词计算出一个基于注意力的表达A^1,…A^5。我们将会在后面解释A(q,K,V)中每个符号的含义。后面我们将详细讲述如何计算x^3的注意力表达A^3。
我们需要用到词嵌入的相关知识,表示x^3的一种方法,就是查找x^3的词嵌入。不过根据语境,我们是把x^3作为一个历史名胜或假日胜地,还是世界第二大洲来考虑呢?根据我们对x^3的理解,可以选择不同方式来表示它,这就是A^3表达的目的所在。先来看看x^3周围的单词,根据上下文信息决定最合适的表达。实际上,自注意网络的计算过程,与我们前面了解的基于RNN的注意力机制没有什么大的区别,除非我们要进行并行计算来确定这个句子中5个单词的表达。
回想我们在attention-RNN中使用的注意力方程,如图中左边部分所示,而在self-attention模型中,注意力方程变成了:
我们可以通过对比上图中的两个方程,发现它们之间的相似之处。都涉及一个softmax函数。最主要的区别在于对于每个单词而言,以x^3为例,可以有3个值,query,key和value。这些值是计算每个单词注意力值得关键输入数据。
我们将详细讲述如何计算x^3的注意力表达A^3。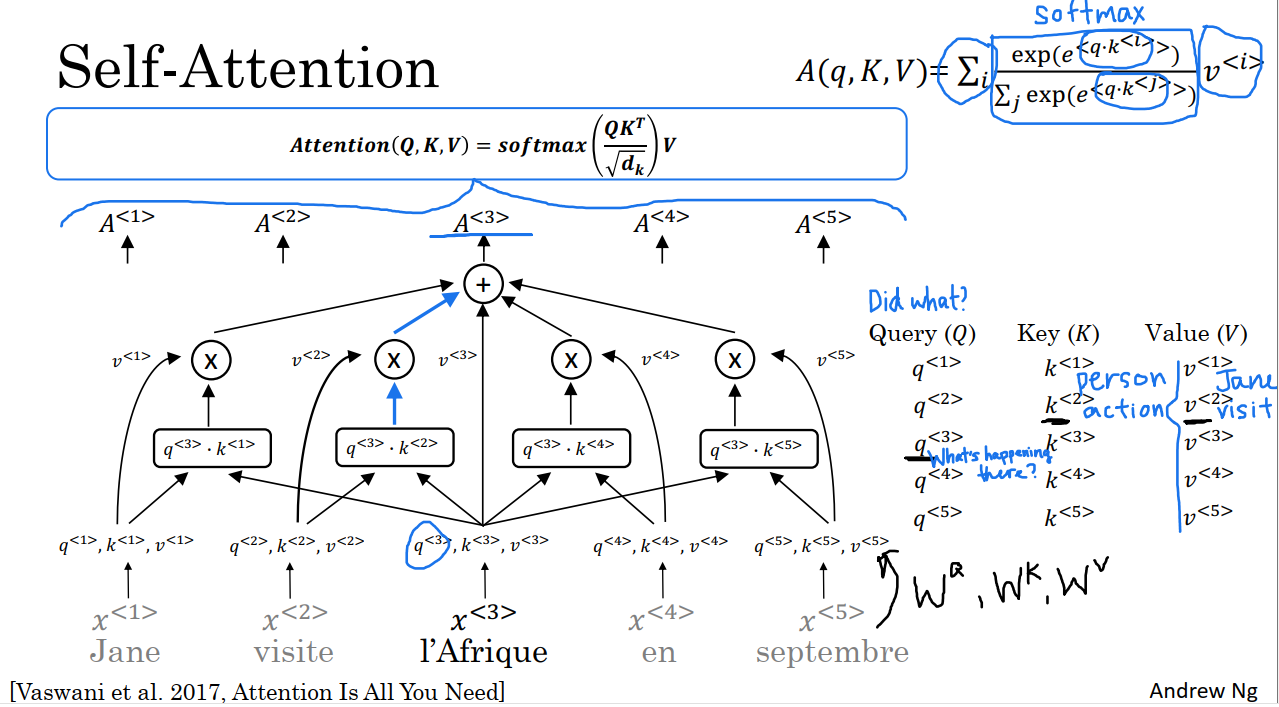
我们要把每一个单词与(query,key,value)对关联起来。如果x^3是输入第三个单词的词嵌入,那么q^3的计算方式为
key和value同理:
其中W^Q,W^K,W^V都是这个学习算法的参数。通过这些参数,我们可以得出每一个单词的query,key和value。(query,key,value)的作用就是:
q^3是一个关于x^3的问题,我们计算q^3和k^1的内积m1,m1表示当用x1来回答q3这个问题时,答案的正确程度。然后我们计算q3和k2的内积m2,m2表示用x2来回答这个问题时,答案的正确程度。以此类推,可以计算出q3问题下其他单词作为答案的正确程度。这样做的目的在于获得所需要的最多信息,以帮助我们计算出最有用的表达A^3。
同样,为了建立直观感觉,如果k1代表一个人,k2代表一个动作,那么我们就会发现q3与k2的乘积最大,这意味着x2提供了与x3的问题最有关联的背景。换言之,x3就是x2动作的目的地。
我们要做的就是获取五个词的key和value,并将它们通过softmax函数(具体见上图右上角)。
在q3乘以k2的例子中,k2可能是q3*ki的最大值,如图中蓝色路径。然后我们可以通过求和计算出对应的A3,准确来说是A(q3,K,V)。
这种表达的主要优点是x^3这个词不是某种固定的词嵌入,相反,它让自注意力机制意识到它是访问的目的地,从而计算出这个词更丰富、更有用的表达。我们可以使用类似的方法计算出A1,…,A5其他值。如果把所有5个值得计算放在一起,我们得出了如上图所示得表达式。在这个表达式中,用attention(Q,K,V)表示刚才讨论的所有计算。其中Q,K,V矩阵的值如图中右边部分所示。softmax部分为计算式子的向量化表达。它的分母部分只是点积的缩放,并不会爆炸。因此这个模型的名字叫做缩放点积注意力。
最终,self-attention机制中的输入有query,key,value。query可以让我们问一个关于这个词的问题,key通过点积计算可以查看所有其他单词和query的相似度,它有助于我们得出与问题最有关联的答案。value参与A值的计算。如果可以得出更多这些单词的表达,而不是基于每一个词的左右的内容,使得所有一切都能结合语境进行考虑.
10.5 多头注意力机制
每计算一次序列中的自注意力,就称为一个头。那么多头注意力,就意味着多次计算注意力。在上一节中对于每一个输入项,得到了Q,K,V,然后用它们的数据值乘上WQ,WK和WV。在多头注意力机制中,可以同样取query、key和value的向量作为输入数据,并计算多个注意力。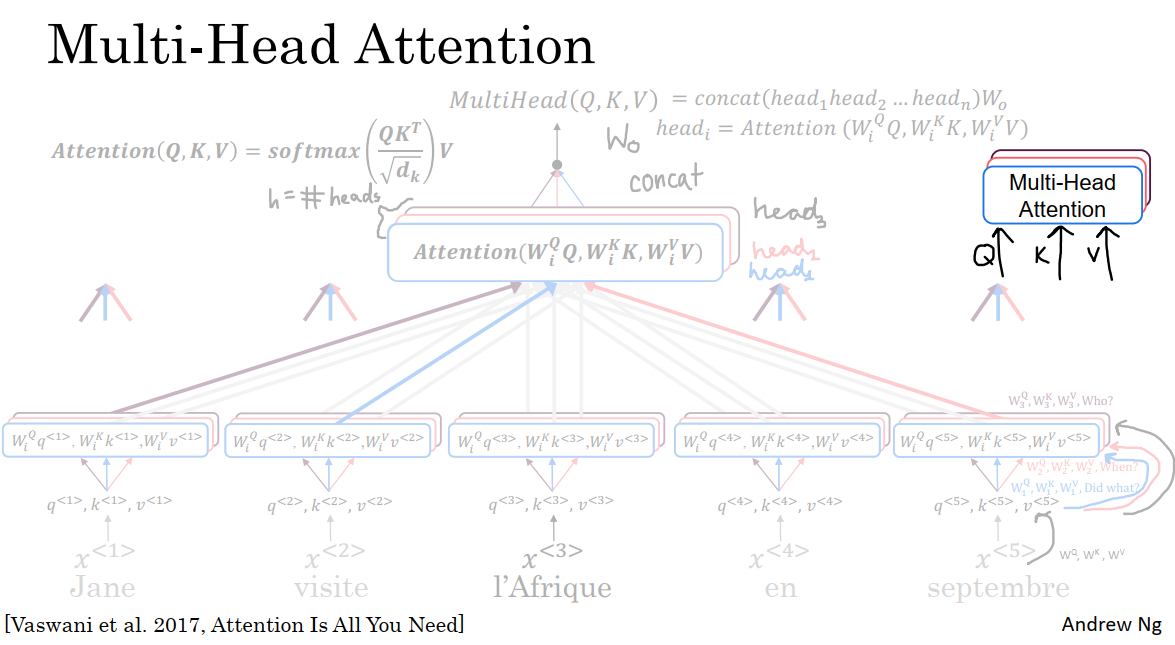
如上图所示,我们从第一个开始,用它的embedding值(词嵌入)乘上权重矩阵值W_1^Q,W_1^K和W_1^V。这三个值就是第一个单词的新向量集,也就是第一个单词的新的query,key和value。
并以此类推,计算出其他每一个单词的新向量集。为了便于理解,我们会发现W_1^Q,W_1^K,W_1^V有助于提出和解决问题。即那里发生了什么?也就是上一节所介绍的自注意力的范例。然后单词visit提供了关于发生了什么的最佳答案,也就是visit的key和Afrique的query之间的内积具有最大值,这便是我们的第一个问题。(蓝色箭头)
上图中所示的是单词“Afrique”获得表达的过程,我们对Jane,visit,September也进行相似的操作,以获得这个句子中5个单词的5个向量集。这是在多头注意力机制,第一个头所进行的计算。至于其他单词,也需要与单词Afrique一样进行计算,即用A1,A2,A3,A4,A5来表述这个句子。
不过,在多头注意力机制中,我们不只进行一次计算,而是进行许多次,如果我们有8个头,就意味着整个计算过程要进行八次。到目前为止,我们已经进行了第一个头的计算,得到W_1^Q,W_1^K,W_1^V。注意力方程Attention也如图中式子所示,与自注意力机制没有区别。
现在我们需要进行第二个头的计算,第二个头将有一个新的矩阵集,得到W_2^Q,W_2^K,W_2^V,它们允许这个机制回答第二个问题,第一个问题是发生了什么?也许第二个问题是什么时候发生的?通常情况下,我们在第一个头后面叠加第二个头。然后重复进行一次与第一个头一样的计算,不过这次是与新矩阵集一起进行的。在这种情况下,最终得出September的key和Afrique的query之间的内积取得最大值。(红色箭头),这表明September的值将在Afrique表达的第二部分中,发挥着举足轻重的作用。
也许我们想问的第三个问题,其权重矩阵为W_3^Q,W_3^K,W_3^V,它关心的内容是谁和Afrique有关系?在这种情况下,当进行第三次计算时,或许Jane的key向量与Afrique向量之间的内积会取得最大值(黑色箭头)。这样Jane的值,将在这个表达中具有最大的权重。
在文献中,头的数目通常用小写字母h表示,即h=头数。在本例中,我们在上图中画出了3个头。但更典型的是八个头。在先用三个头或八个头进行相关计算后,(也可以是别的数量的头),把这三个值(三头计算结果)串联起来,再并行计算多头注意力的输出数据。最后的值是对所有这些头的合并,然后最后的值乘以一个矩阵Wo,如图中上部的式子。
还有一个细节,在多头注意力的描述中,在不同的头我们要计算不同的值,就像是用一个for循环来不断进行头计算一样。但在实际操作中,我们需要并行计算这些不同头的值,因为这些头的值之间没有什么依存关系。实际上就操作流程而言,要并行计算所有头的值,而不是按顺序计算,然后把它们连接起来,再乘上Wo,这就是多头注意力的值。
过程总结:
1 把输入单词表示为query、key、value三元组。
2 对于第i头的计算,乘上W_i^Q,W_i^K,W_i^V。
3 计算Attention(W_2^Q×Q,W_2^K×K,W_2^V×V)。
4 把n个头的计算结果连接起来。
5 乘上Wo,得到最终结果。
10.6 Transformer网络
在本节,我们将学习如何通过模仿前面视频所见过的注意力机制,来构建Transformer架构。让我们再次使用上次的输入示例,以及输入示例对应的嵌入(embedding)来开始这个过程。我们将详细了解把这句话从法语翻译成英语的过程。
首先我们在句子的开始和结尾添加了SOS和EOS标志。到目前为止,为了简单起见,我们只讨论句子中单词的嵌入,不过在许多序列翻译任务中,句子开始的标志SOS和句子结尾表示EOS,都非常常见。
使用Transform的第一步,就是把这些嵌入,输入到一个具有多头注意力层的编码器中,然后,向多头注意力层输入由嵌入计算得到的Q,K,V。该层会生成一个能传输到前馈神经网络的矩阵,该网络有助于确定句子中有趣的特征。据Transform的相关文献介绍,这个编码器要重复进行N次这种操作,其中最常见的N=6。
经过6次编码器的操作后,这个编码器的输出数据会被输入到一个解码器里。解码器额作用就是输出英语译文。第一个输出SOS,无论我们生成的翻译内容是什么,解码器每一次都要输入前几个单词,一旦开始工作,我们唯一知道的事情,就是翻译将从句子的开头标识开始,因此,要把句子的开头标识SOS输入到多头注意力区块,最终便可生成多头注意力区块的Q,K和V值。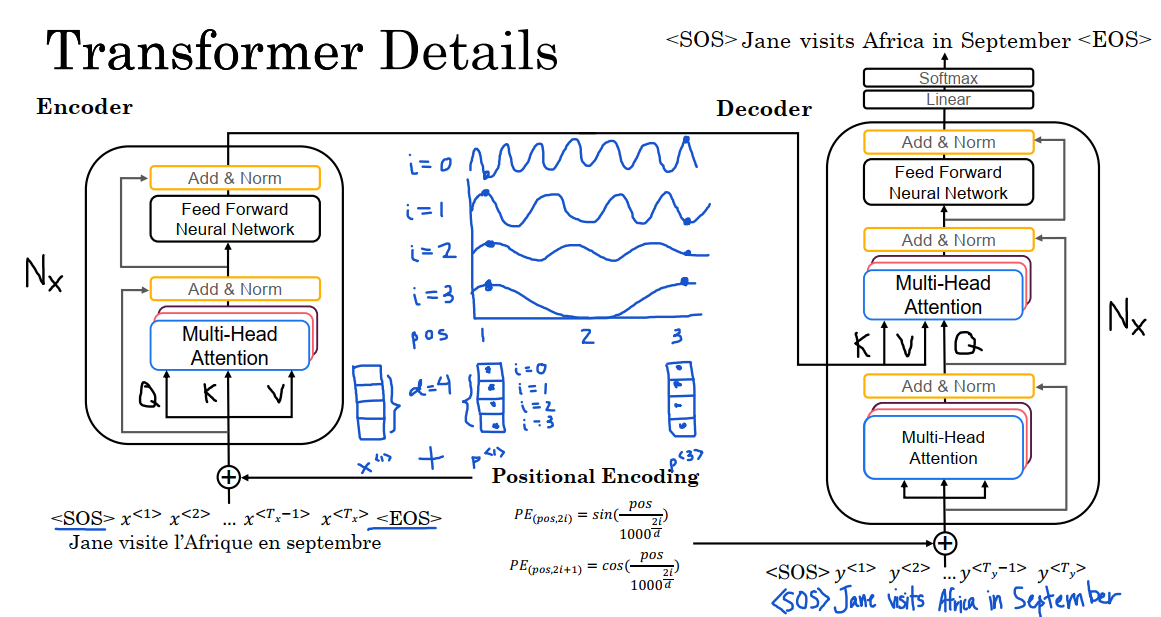
第一个区块的输出可用于生成下一个多头注意力区块的Q矩阵,而编码器的输出则用于生成K和V的值,这就是第二个多头注意力区块的Q、K、V的值。
为什么是这样的构造呢?上图中右下角是目前为止,我们输出的翻译,这会使query提出这句话的开始是什么?接下来我们要用K和V提取来自于法文句子的上下文,并据此尝试决定序列中要生成的下一个单词是什么。
要结束解码器的工作,多头注意力区块将会将输出值传递到一个前馈神经网络中,并重复此操作n次,可能n=6。我们需要在此过程中从前馈神经网络中提取输出值,再把输出值传递到输入中,这样的操作也要进行6次。
解码器中前馈神经网络的作用是预测句子中的下一个单词。我们希望,它将决定英语译文的第一个单词是Jane,然后我们要做的是把Jane同样传递给输入,现在下一个query就来自SOS和Jane,并提出给定Jane,接下来最合适的词会是什么?我们要找到正确的key和value,它们将有助于生成最合适的下一个词,希望会生成visit。然后我们再次运行这个神经网络,得到了Africa,再将Africa传递回输入,以此类推,得出in,继而是September。在理想状态下,通过这种方法,就可以生成句子结尾的标识,这时翻译任务便完成了。
这就是编码器和解码器区块,至于它们如何组合来完成一系列翻译任务,则需要在Transformer架构中寻找答案了。
在这种情况下,通过把输入的句子翻译成另一个语言的句子,我们大致清楚了神经网络中的注意力是如何组合起来同步运算的。不过,除了弄懂Transformer架构的主要内容外,还需要额外变换一些花里胡哨的东西,让我们来简单地逐步变换。这些内容,使Transformer网络工作得更好。
首先使输入的位置编码。我们回想自注意力方程式,就会发现它不可以标识单词的位置,这个词是位于句首。句中还是句末?单词在句子中的位置对于翻译来说至关重要,所以对输入元素的位置进行编码的方式,是这些正弦和余弦方程式的组合,见图中下部位置的式子,其中pos标识该词的数字位置,就Jane来说,pos=1。式中的i是指编码的不同维度。
我们来详细介绍i。例如,假设我的词嵌入是一个具有四个相同值的向量,在这种情况下,这个词嵌入的维度D是4,x^1,x^2,x^3,x^4,四维向量。在本例中,我们要创建一个具有相同维度的位置嵌入向量,也就是四维的,例如我们使用4维向量p^1标识输入的第一个单词Jane。第一个单元i=0,第二个单元i=1,一直到i=3。
pos和i都是用于计算编码值的变量,pos指的是单词的位置,在4维向量编码时,i可以从0到3,d=4是指这个向量的编码的目标维度。
含有正弦和余弦函数的位置编码的目的是创建一个独一无二的位置编码向量。每个单词的向量都是唯一的。向量p^3编码了Afrique的位置,Afrique用四个值表示,但与对第一个单词Jane的位置进行编码的四个值有所不同。这样就是我们的目的所在。
在图中的上半部分我们画出了正弦和余弦曲线的样子。当i=0时,我们的曲线为正弦曲线。当i=1时,我们会得到余弦曲线。当i=2时,我们会得到低频正弦曲线。当i=3时,会得到低频余弦曲线。就位置1而言,它的编码p^1就是这些曲线pos=1处。不同的单词,在图中有不同的位置,比如现在水平轴上的位置是3,就会有不同的一组值。
由于位置编码p^1是直接添加到x1输入的,因此,每个单词的向量也受到单词在句中位置的影响。
除了把位置编码添加到嵌入外,还可以利用残差连接将它们传递到网络中。这些残差连接与ResNet中的类似。在这种情况下,它们的目的是通过整个架构传递位置信息。除了位置编码外,Transformer网络还使用一个称为Add&Norm层,它非常类似于Batch Norm层。在整个架构中,这种类似于Batch Norm的Add&Norm层可以不断在框架中出现。
最后,就解码器区块的输出而言,实际上还存在一个线性层,和一个softmax层来预测下一个单词,且每次只能与预测一个单词。如果阅读关于Transformer网络的文献,我们可能会看到掩码多头注意力机制,我们可以在上图中右下角的位置看到它。只有在用一个合适的数据集训练Transformer网络时,才能显示出掩码多头注意力机制的重要性。
前面我们介绍了Transformer网络如何一次预测一个单词。现在,假设我们的数据集包含关于法语Jane,visit,Afrique,September的正确英文译文Jane visits Africa in September。在训练时,我们需要访问完整的正确的英文译文,正确的输入和正确的输出。由于数据集中含有完整的正确的译文输出,因此在预测过程中,我们不需要一次生成一个译文,相反,掩码的作用时屏蔽句子的最后部分,以便模拟网络在测试时需要做出的预测。换句话说,掩码多头注意力机制的工作就是先反复假装网络已经做出了前几个词的翻译,并且屏蔽余下的词,来查看前面的部分是否翻译的不错,再看看新网络是否可以准确地预测出序列中下一个单词的含义。